2024. 3. 6. 00:04ㆍ딥러닝 모델: 파이토치
이번에는 MNIST 데이터에 대해서 이해하고 파이토치로 소프트맥스 회귀를 구현하여 MNIST 데이터를 분류해보자
♣ MNIST 데이터 이해하기

MNIST는 숫자 0부터 9까지의 이미지로 구성된 손글씨 데이터셋이다. 총 60,000개의 훈련 데이터와 레이블, 총 10,000개의 테스트 데이터와 레이블로 구성되어 있다. 레이블은 0부터 9까지 총 10개이다.
MNIST 문제는 손글씨로 적힌 숫자 이미지가 들어오면 그 이미지가 무슨 숫자인지 맞추는 문제이다.
각각의 이미지는 아래와 같이 28 픽셀 × 28 픽셀의 이미지이다.

이 이미지는 28 * 28 = 784 픽셀이므로, 각 이미지를 총 784개의 원소를 가진 벡터로 만든다. 즉 총 784개의 특성을 가진 샘플이 되는데, 이는 앞서 풀었던 문제들보다 특성이 훨씬 많은 샘플이다.

♣ torchvision 소개하기
torchvision은 유명한 데이터셋들, 이미 구현되어있는 유명한 모델들, 일반적인 이미지 전처리 도구들을 포함하는 패키지이다. 아래 링크는 torchvision 어떤 데이터셋들과 모델들, 전처리 방법들을 제공하고 있는지 보여준다.
https://pytorch.org/docs/stable/torchvision/index.html
♣ 분류기 구현을 위한 사전 설정

랜덤 시드 고정하기

하이퍼파라미터를 변수로 설정하기
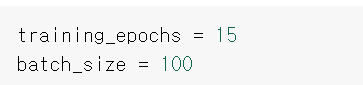
torchvision.datasets는 torch.utils.data.Dataset의 하위클래스이므로 __getitem__과 __len__ 메소드를 가지고 있으며, torch.utils.data.DataLoader 메소드를 적용해서 batch size나 shuffle여부 등의 매개변수를 적용하여 데이터 로딩을 편리하게 할 수 있다.
torchvision.datasets는 torch.utils.data.Dataset을 상속받아서 다양한 표준 데이터셋을 제공하는 모듈이다. torchvision.datasets 모듈에는 여러 가지 데이터셋이 내장되어 있어서 사용하기 편리하다.
예시)
- Image Classification: CIFAR10, CIFAR100, MNIST, FashionMNIST, Caltech101, ImageNet 등
- Image Detection or Segmentation: CocoDetection, celebA, Cityscapes, VOCSegmentation 등
- Optical Flow: FlyingChairs, FlyingThings3D, HD1K, KittiFlow, Sintel 등
- Stereo Matching: CarlaStereo, Kitti2015Stereo, CREStereo, SintelStereo 등
- Image Pairs: LFWPairs, PhotoTour
- Image Captioning: CocoCaptions
- Video Classification: HMDB51, Kinetics, UCF101
- Base Classes for Custom Datasets: DatasetFolder, ImageFolder, VisionDataset
torchvision.datasets의 주요 기능은 아래와 같다.
1. 표준 데이터셋 로드: 일반적으로 사용되는 여러 데이터셋을 손쉽게 로드
2. 전처리 및 변환: 데이터셋을 로드할 때 데이터 전처리 및 변환을 적용할 수 있는 기능 제공.
♣ MNIST 분류기 구현하기
torchvision.datasets.dsets.MNIST를 사용하여 MNIST 데이터셋을 불러오기


첫 번째 인자 root는 MNIST 데이터를 다운로드 받을 경로이다. 두번째 인자 train은 True를 주면 MNIST의 훈련 데이터를 리턴받으며 False를 주면 테스트 데이터를 리턴받는다. 세번째 인자 transform은 현재 데이터를 파이토치 텐서로 변환한다. 네번째 인자 download는 해당 경로에 MNIST 데이터가 없다면 다운로드 받겠다는 의미이다.
다운로드받은 데이터를 DataLoader로 사용하기


DataLoader에는 4개의 인자가 있다. 첫번째 인자인 dataset은 로드할 대상을 의미하며, 두 번째 인자인 batch_size는 배치 크기, shuffle은 매 epoch마다 미니 배치를 셔플할 것인지의 여부, drop_last는 마지막 배치를 버릴 것인지를 의미한다.
- drop_last를 하는 이유를 이해하기 위해서 1,000개의 데이터가 있다고 했을 때, 배치 크기가 128이라고 해봅시다. 1,000을 128로 나누면 총 7개가 나오고 나머지로 104개가 남습니다. 이때 104개를 마지막 배치로 한다고 하였을 때 128개를 충족하지 못하였으므로 104개를 그냥 버릴 수도 있습니다. 이때 마지막 배치를 버리려면 drop_last=True를 해주면 됩니다. 이는 다른 미니 배치보다 개수가 적은 마지막 배치를 경사 하강법에 사용하여 마지막 배치가 상대적으로 과대 평가되는 현상을 막아줍니다.
출력한 길이를 보면 본래 mnist_train 데이터셋은 60,000개였으나 batch_size를 100으로 해서 묶으면 600개의 미니배치로 나뉘어서 data_loader가 된다는 것을 알 수 있다.
모델 설계하기
이제 모델을 설계한다. input_dim은 784(이미지의 크기가 28*28이므로)이고, output_dim은 10이다.

to( ) 함수는 연산을 어디서 수행할지를 정한다. to( ) 함수는 모델의 매개변수를 지정한 장치의 메모리로 보낸다.
CPU를 사용할 경우에는 필요없지만, GPU를 사용하려면 to('cuda')를 할 필요가 있다.
bias는 편향 b를 사용할 것인지를 나타낸다. 기본값이 True이므로 굳이 할 필요는 없다.
비용함수와 옵티마이저 정의하기

앞서 소프트맥스 회귀를 배울 때는 torch.nn.functional.cross_entropy( )를 사용하였지만 여기서는 torch.nn.CrossEntropyLoss( )를 사용한다. 둘 다 파이토치에서 제공하는 크로스 엔트로피 함수로 둘 다 소프트맥스 함수를 포함하고 있다.
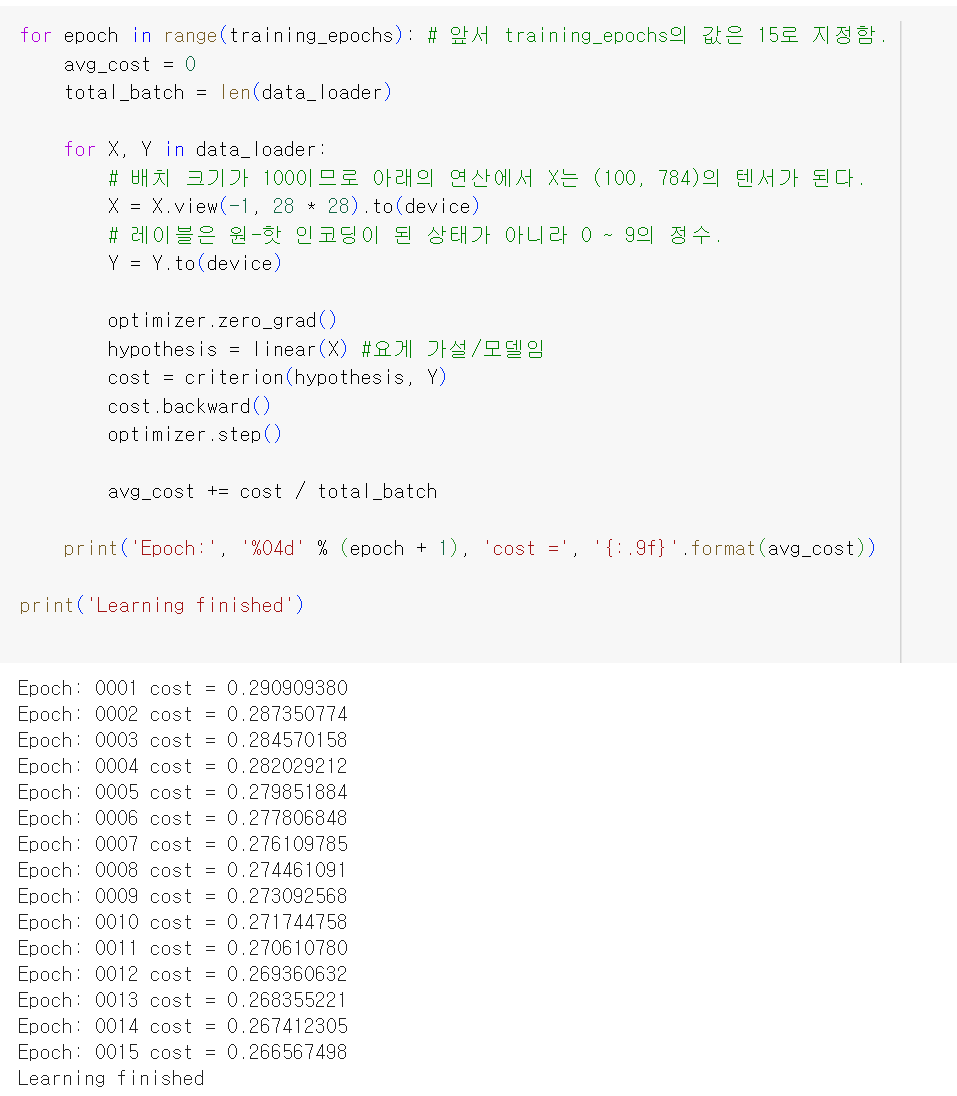
학습하기
테스트 데이터를 활용하여 모델 테스트하기

테스트 데이터 중 하나를 뽑아서 예측하기

correct_prediction = torch.argmax(prediction, 1) == Y_test를 보면 dim=1을 기준으로, 가장 큰 값을 가지는 인덱스를 찾는다. 즉 각 행을 기준으로 해서 각각의 클래스 중 가장 큰 값을 가지는 클래스를 찾는 것이다. 가장 큰 값을 가지는 클래스는 그 데이터가 해당 클래스로 분류될 확률이 가장 큰 것이다. 이 값이 실제 label인 Y_test와 같은지 확인하여 correct_prediction을 구하는 것이다.
♣ 참고 자료
출처: https://rfriend.tistory.com/784 [R, Python 분석과 프로그래밍의 친구 (by R Friend):티스토리]
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(06-02. 인공신경망: 퍼셉트론) (0) | 2024.03.08 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(06-01. 인공신경망: 머신 러닝 용어 이해하기) (0) | 2024.03.06 |
| Pytorch로 시작하는 딥러닝 입문(05-03. 소프트맥스 회귀 구현하기) (0) | 2024.03.03 |
| Pytorch로 시작하는 딥러닝 입문(05-02. 소프트맥스 회귀 이해하기) (0) | 2024.03.02 |
| Pytorch로 시작하는 딥러닝 입문(05-01. 원-핫 인코딩/One-Hot Encoding) (0) | 2024.03.01 |