2023. 7. 11. 20:43ㆍVGG16
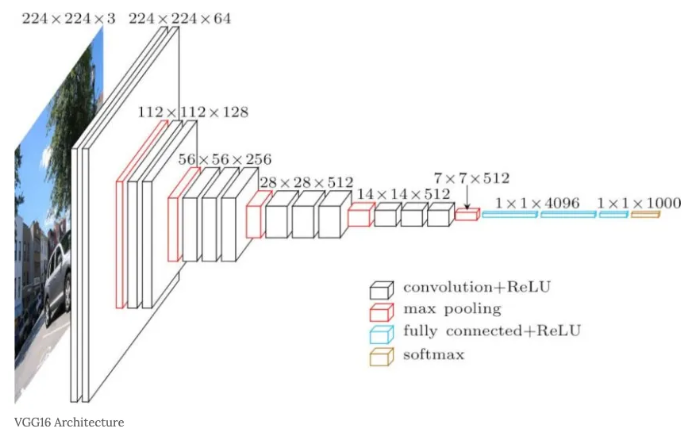

VGG16 Architecture 구성
- 13 Convolution Layers + 3 Fully-connected Layers with ReLu (합성곱과 함께 활성함수 ReLu도 사용)
- 3*3 convolution filters
- stride: 1&padding:1
- 2*2 max pooling(stride:2) => 위의 표에서는 'M'이 MaxPooling임
- conv3: 3X3 필터
- conv1: 1X1 필터
- conv3-N: N은 필터의 개수. conv3-64라고 하면 64개의 3X3 필터를 학습 매개변수로 사용했다는 의미
------------------------------------------------------------------여기까지가 Feature Extractor: 이미지의 특성 뽑는 기능
- FC: 완전히 연결된 FC 레이어
- softmax: 출력층은 classification을 위한 softmax 함수 사용
-------------------------------------------------------------------Classifier: fully connected 레이어와 출력층에서 이미지를 분류하는 기능
VGG16은 왜 Conv 필터의 사이즈가 3*3으로 고정되어 있을까?
- 필터를 거칠수록 이미지의 크기는 줄어듦. 필터의 사이즈가 클수록 이미지가 줄어드는 것이 빨라져서 레이어를 깊게 만들 수 없음
- 따라서 필터를 가장 작은 사이즈인 3*3으로 설정하여 큰 필터보다 이미지가 적게 줄어서 상대적으로 레이어가 깊은 모델을 만들어서 사용함
- 각 Convolution 연산은 ReLu 함수를 포함함. 따라서 필터링을 많이 하면 ReLu 함수가 그만큼 많이 적용되는 것. 비선형 함수인 ReLu가 많이 적용되면 결정함수의 비선형성이 증가하게 되어서 이미지의 특징을 더 잘 식별할 수 있게 됨
- Convolution Network 구조를 학습할 때, 가중치는 필터의 크기에 해당함. 따라서 작은 필터를 사용하면 파라미터 수가 감소함.
☎ 참고 자료
VGG16 논문 리뷰 — Very Deep Convolutional Networks for Large-Scale Image Recognition
VGG-16 모델은 ImageNet Challenge에서 Top-5 테스트 정확도를 92.7% 달성하면서 2014년 컴퓨터 비전을 위한 딥러닝 관련 대표적 연구 중 하나로 자리매김하였다.
medium.com
-VGG16 모델 구조: https://daechu.tistory.com/10
[VGGNet] VGGNet 개념 정리
안녕하세요 대추입니다. 이번에 딥러닝에 대해 공부를 하며 VGGNet도 건드려 봤는데 사용하기전 알아두면 좋을 만한 것에 대해 정리해보고자 작성하게 되었습니다. VGGNet에는 A, A-LRN, B, C, D, E가 있
daechu.tistory.com
'VGG16' 카테고리의 다른 글
| (논문)Analysis of Convolutional Neural Network based Image Classification Techniques (0) | 2023.07.11 |
|---|