2024. 4. 16. 21:32ㆍ딥러닝 모델: 파이토치
DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치에 대해 알아보자. TF-IDF를 사용하면 기존의 DTM을 사용하는 것보다 많은 정보를 고려하여 무서들을 비교할 수 있다.
♣ TF-IDF
TF-IDF는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다. DTM을 만든 후, TF-IDF 가중치를 부여한다.
TF-IDF는 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있다.
TF-IDF는 TF와 IDF를 곱한 값을 의미하는데, 이를 식으로 표현해보자. 문서를 d, 단어를 t, 문서의 총 개수를 n이라고 표현할 때, TF, DF, IDF는 각각 다음과 같이 정의할 수 있다.
1. tf(d, t): 특정 문서 d에서의 특정 단어 t의 등장 횟수
2. df(t): 특정 단어 t가 등장한 문서의 수
앞서 배운 DTM에서 바나나는 문서2와 문서3에서 등장했다. 이 경우, 바나나의 df는 2이다. 문서3에서 바나나가 두 번 등장했지만, 그것은 중요한 게 아니다. 심지어 바나나란 단어가 문서2에서 100번 등장했고, 문서3에서 200번 등장했다고 하더라도 바나나의 df는 2가 된다.
3. idf(t): df(t)에 반비례하는 수

log를 사용하지 않았을 때, IDF를 DF의 역수로 사용한다면 총 문서의 수 n이 커질 수록, IDF의 값은 기하급수적으로 커지게 된다. 그렇기 때문에 log를 사용한다. 왜 log가 필요한지 n=1,000,000일 때의 예를 들어서 알아보자.. log의 밑은 10을 사용한다고 가정하였을 때 결과는 아래와 같다.
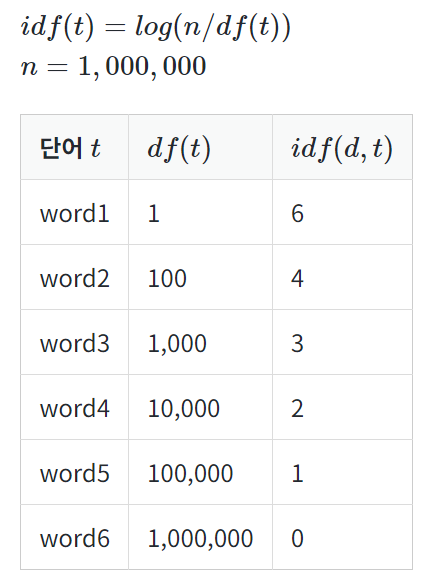

다르게 설명하자면, 불용어 등과 같이 자주 쓰이는 단어들은 비교적 자주 쓰이지 않는 단어들보다 최소 수십 배 자주 등장한다. 그런데 비교적 자주 쓰이지 않는 단어들조차 희귀 단어들과 비교하면 또 최소 수백 배는 더 자주 등장하는 편이다. 때문에 log를 씌워주지 않으면, 희귀 단어들에 엄청난 가중치가 부여될 수 있다. 로그를 씌우면 이런 격차를 줄이는 효과가 있다. log 안의 식에서 분모에 1을 더해주는 이유는 첫번째 이유로는 특정 단어가 전체 문서에서 등장하지 않을 경우에 분모가 0이 되는 상황을 방지하기 위함이다.
TF-IDF는 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단하며, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단한다. TF-IDF 값이 낮으면 중요도가 낮은 것이며, TF-IDF 값이 크면 중요도가 큰 것이다. 즉, the나 a와 같이 불용어의 경우에는 모든 문서에 자주 등장하기 마련이기 때문에 자연스럽게 불용어의 TF-IDF의 값은 다른 단어의 TF-IDF에 비해서 낮아지게 된다.
앞서 DTM을 설명하기 위해 들었던 위의 예제를 가지고 TF-IDF에 대해 이해해보자.


문서의 총 수는 4이기 때문에 ln 안에서 분자는 늘 4으로 동일하다. 분모의 경우에는 각 단어가 등장한 문서의 수(DF)를 의미하는데, 예를 들어서 '먹고'의 경우에는 총 2개의 문서(문서1, 문서2)에 등장했기 때문에 2라는 값을 가진다. 각 단어에 대해서 IDF의 값을 비교해보면 문서 1개에만 등장한 단어와 문서 2개에만 등장한 단어는 값의 차이를 보인다. IDF는 여러 문서에서 등장한 단어의 가중치를 낮추는 역할을 한다.
TF-IDF 를 계산해보자. 각 단어의 TF는 DTM에서의 각 단어의 값과 같으므로, 앞서 사용한 DTM에서 단어 별로 위의 IDF값을 곱해주면 TF-IDF 값을 얻는다.
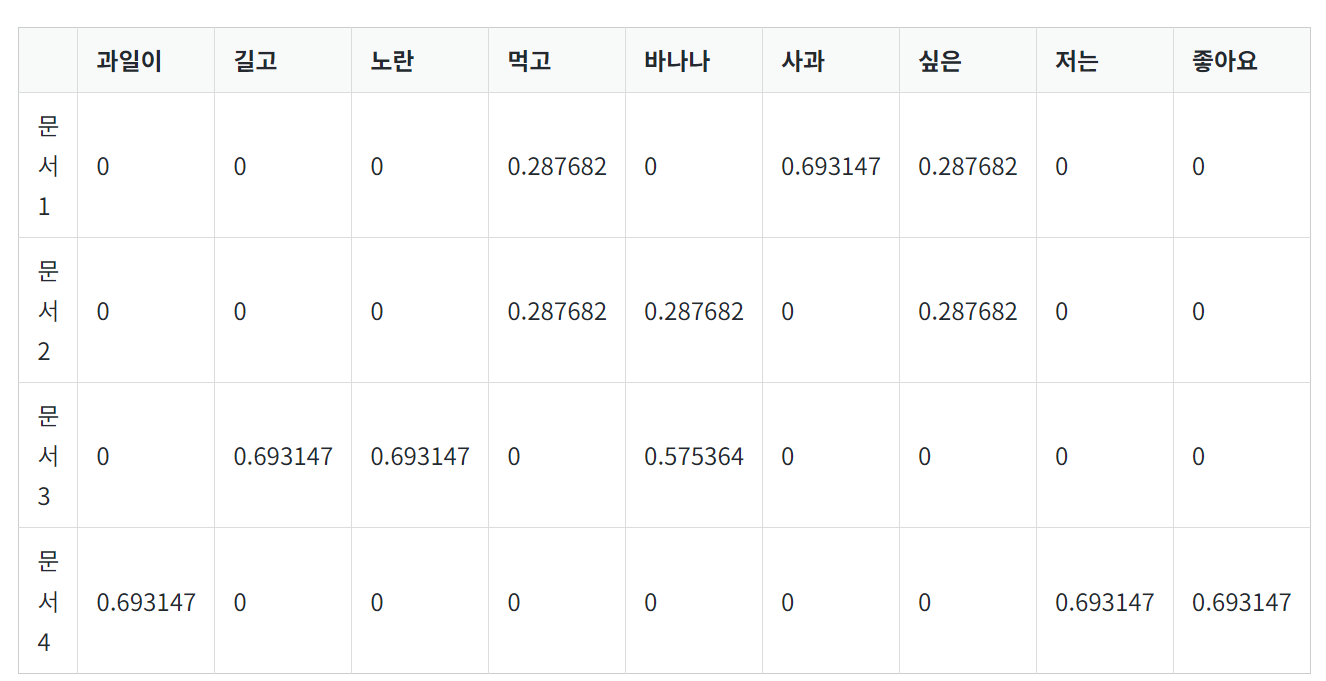
문서3에서의 바나나만 TF 값이 2이므로 IDF에 2를 곱해주고, 나머진 TF 값이 1이므로 그대로 IDF 값을 가져온다. 문서2에서의 바나나의 TF-IDF 가중치와 문서3에서의 바나나의 TF-IDF 가중치가 다른 것을 볼 수 있다. 수식적으로 말하면, TF가 각각 1과 2로 달랐기 때문인데 TF-IDF에서의 관점에서 보자면 TF-IDF는 특정 문서에서 자주 등장하는 단어는 그 문서 내에서 중요한 단어로 판단하기 때문이다. 문서2에서는 바나나를 한 번 언급했지만, 문서3에서는 바나나를 두 번 언급했기 때문에 문서3에서의 바나나를 더욱 중요한 단어라고 판단하는 것이다.
♣ 파이썬으로 TF-IDF 직접 구현하기
위의 과정을 파이썬으로 직접 구현해보자. 앞의 설명에서 하용한 4개 문서를 docs에 저장한다.

TF, IDF, TF-IDF 값을 구하는 함수를 구현한다.

TF를 구해보자. (DTF을 데이터 프레임에 저장하여 출력하기)
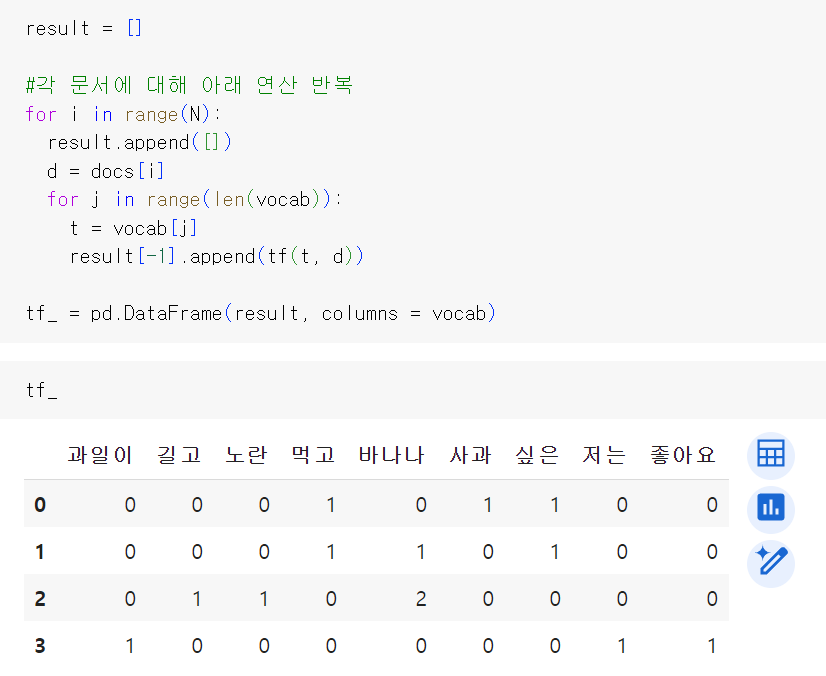
정상적으로 DTM이 출력되었다. 각 단어에 대한 IDF 값을 구해보자.

위에서 수기로 구한 IDF 값들과 일치한다. TF-IDF 행렬을 출력해보자.

실제 TF-IDF 구현을 제공하고 있는 많은 머신 러닝 패키지들은 패키지마다 식이 조금씩 상이하지만, 위에서 배운 식과는 다른 조정된 식을 사용한다. 그 이유는 위의 기본적인 식을 바탕으로 한 구현에는 몇 가지 문제점이 존재하기 때문이다. 만약 전체 문서의 수 4인데, df(t)의 값이 3인 경우에는 어떤 일이 벌어질까? df(t)에 1이 더해지면서 log항의 분자와 분모의 값이 같아지게 된다. 이는 log의 진수값이 1이 되면서 idf(d, t)의 값이 0이 됨을 의미한다. 식으로 표현하면 idf(d, t) = log(n/(df(t)+1)) =0 다. IDF의 값이 0이라면 더 이상 가중치의 역할을 수행하지 못한다. 아래에서 실습할 사이킷런의 TF-IDF 구현체 또한 위의 식에서 조정된 식을 사용하고 있다.
♣ 사이킷런을 이용한 DTF과 TF-IDF 실습
사이킷런을 통해 DTF과 TF-IDF를 만들어보자. BoW를 설명하며 배운 CountVectorizer를 사용하면 DTM을 만들 수 있다.

DTM이 완성되었다. DTM에서 각 단어의 인덱스가 어떻게 부여되었는지 확인하기 위해 인덱스를 확인하였다. do가 0의 인덱스를 가지고 있는데 do는 세 번째 문서에만 등장했기 때문에 세 번째 행에서만 1의 값을 가진다. 1의 인덱스를 가진 know는 첫 번째 문서에만 등장했으므로 첫 번째 행에서만 1의 값을 가진다.
사이킷런은 TF-IDF를 자동 계산하는 TfidVectorizer를 제공한다. 사이킷런의 TF-IDF는 위에서 배웠던 보편적인 TF-IDF 기본 식에서 조정된 식을 사용한다. 요약하자면, IDF의 로그항의 분자에 1을 더해주며, 로그항에 1을 더해주고, TF-IDF에 L2 정규화라는 방법으로 값을 조정하는 등의 차이로 TF-IDF가 가진 의도는 여전히 그대로 갖고 있다.

'딥러닝 모델: 파이토치' 카테고리의 다른 글
| 전이학습(Transfer Learning) (0) | 2024.06.06 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(11-05. 코사인 유사도를 이용한 추천 시스템) (0) | 2024.04.17 |
| Pytorch로 시작하는 딥러닝 입문(11-03. 문서 단어 행렬: Document-Term Matrix, DTM) (0) | 2024.04.11 |
| Pytorch로 시작하는 딥러닝 입문(11-02. 텍스트의 유사도: Bag of Words) (0) | 2024.04.08 |
| Pytorch로 시작하는 딥러닝 입문(11-01. 텍스트의 유사도: 단어의 표현 방법) (0) | 2024.04.08 |