2024. 4. 8. 20:10ㆍ딥러닝 모델: 파이토치
Bag of Words는 단어의 등장 순서를 고려하지 않는 빈도수 기반의 단어표현방법이다.
♣ Bag of Words란?
단어들의 순서는 전혀 고려하지 않고 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현방법이다.
단어들이 들어있는 가방을 상상해보자. 갖고 있는 텍스트 문서에 있는 단어들을 가방에다 전부 넣는다. 그 후에 가방을 흔들어서 단어들을 섞는다. 만약 해당 문서 내에서 특정 단어가 N번 등장했다면 이 가방에는 특정 단어가 N개 들어있다. 또한 가방을 흔들어서 단어를 섞었기 때문에 더 이상 단어의 순서가 중요하지 않다.
BoW를 만드는 과정을 두 가지 과정으로 생각해보자.
- 각 단어에 고유한 정수 인덱스를 부여한다.
- 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만든다.
한국어 예제를 살펴보자.
문서1: 정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다.
문서1에 대해서 BoW를 만들어보자. 아래 함수는 입력된 문서에 대해서 단어 집합(vocabulary)을 만들어 각 단어에 정수 인덱스를 할당하고, BoW를 만든다.

해당 함수에 문서1을 입력으로 넣어보자.

문서1에 각 단어에 대해서 인덱스를 부여한 결과는 첫 번째 출력 결과이다. 문서1의 BoW는 두 번째 출력 결과이다.
두 번째 출력 결과를 보면 인덱스 4에 대항하는 '물가상승률'은 두 번 언급되었기 때문에 인덱스 4에 해당하는 값이 2이다.
만약 한국어에서 불용어에 해당하는 조사들까지 제거한다면 더 정제된 BoW를 만들 수도 있다.
♣ Bag of Words의 다른 예제들
위의 함수에 임의의 문서2를 입력으로 하여 결과를 확인해보자.


5번 index에 해당하는 '을'이 두 번 나온다.

문서1과 문서2를 합쳐서 문서3이라고 명명하고 BoW를 만들 수도 있다.


문서3의 단어 집합은 문서1과 문서2의 단어들을 모두 포함한다. BoW는 종종 여러 문서의 단어 집합을 합친 뒤, 해당 단어 집합에 대한 각 문서의 BoW를 구하기도 한다. 문서3에 대한 단어 집합을 기준으로 문서1, 문서2의 BoW를 만든다고 하면 결과는 아래와 같다.

문서3에서 '물가상승률'이라는 단어는 인덱스가 4에 해당한다. 물가상승률이라는 단어는 문서1에서 2회 등장하며 문서2에서는 1회 등장했기 때문에 두 BoW의 인덱스4의 값은 각각 2와 1이 되는 것을 볼 수 있다.
BoW는 각 단어가 등장한 횟수를 수치화하는 텍스트 표현 방법이므로 주로 어떤 단어가 얼마나 등장했는지를 기준으로 문서가 어떤 성격의 문서인지 판단하는 작업에 쓰인다. 즉 분류 문제나 여러 문서 간의 유사도를 구하는 문제에 주로 쓰인다.
예를 들어 '달리기', '체력', '근력'과 같은 단어가 자주 등장하면 해당 문서를 체육 관련 문서로 분류할 수 있다. '미분', '방정식', '부등식'과 같은 단어가 자주 등장하면 수학 관련 문서로 분류할 수 있다.
♣ CountVectorizer 클래스로 BoW 만들기
scikit-learn 에서 단어의 빈도를 Count하여 Vector로 만드는 CountVectorizer 클래스를 지원한다. 이를 이용하면 영어에 대해서는 손쉽게 BoW를 만들 수 있다.


예제 문장에서 you와 love는 두 번씩 언급되었으므로 각각 인덱스 2와 인덱스 4에서 2의 값을 가지며, 그 외의 값에서는 1의 값을 가지는 것을 볼 수 있다. 또한 알파벳 I는 BoW를 만드는 과정에서 사라졌는데, 이는 CountVectorizer가 기본적으로 길이가 2이상인 문자에 대해서만 토큰으로 인식하기 때문이다. 정제(Cleaning) 챕터에서 언급했듯이, 영어에서는 길이가 짧은 문자를 제거하는 것 또한 전처리 작업으로 고려되기도 한다.
주의할 것은 CountVectorizer는 단지 띄어쓰기만을 기준으로 단어를 자르는 낮은 수준의 토큰화를 진행하고 BoW를 만든다는 점이다. 이는 영어의 경우 띄어쓰기만으로 토큰화가 수행되기 때문에 문제가 없지만 한국어에 CountVectorizer를 적용하면, 조사 등의 이유로 제대로 BoW가 만들어지지 않음을 의미한다.
♣ 불용어를 제거한 BoW 만들기
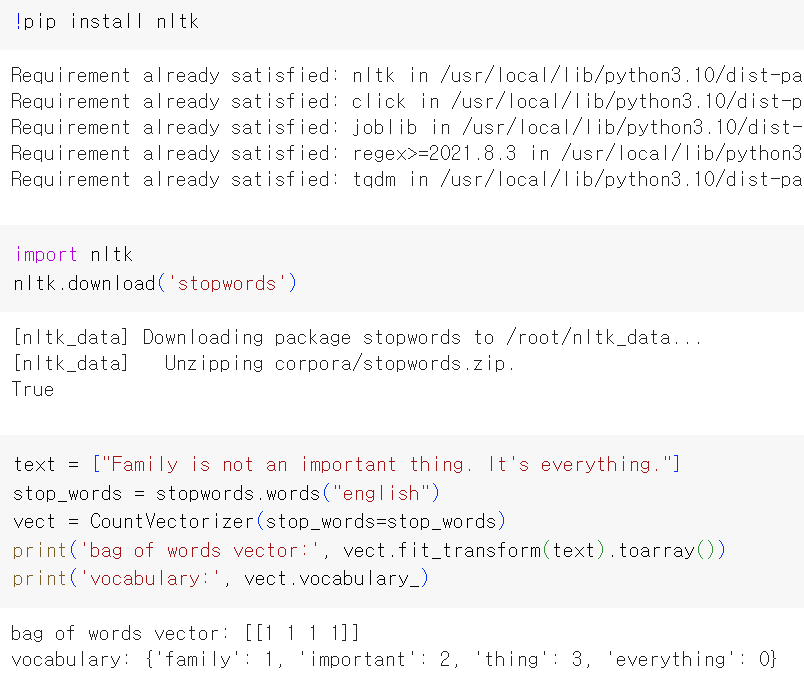
불용어는 자연어 처리에서 별 의미를 갖지 않는 단어들이라고 이야기했다. BoW를 사용한다는 것은 해당 문서에서 각 단어가 얼마나 자주 등장했는지 보겠다는 것이다. 그리고 각 단어에 대한 빈도를 수치화하는 것은 문서 내에서 어떤 단어들이 중요한지를 본다는 의미이다. BoW를 만들 때 자연어 처리의 정확도를 높이기 위해선 불용어를 제거하는 전처리 기법을 사용할 수 있다.
영어의 BoW를 만들기 위해 사용하는 CounterVectorizer는 불용어를 지정하면 불용어는 제외하고 BoW를 만들 수 있도록 불용어 제거 기능을 지원한다.
1. 사용자가 직접 정의한 불용어 사용

2. CountVectorizer에서 제공하는 자체 불용어 사용

3. NLTK에서 지원하는 불용어 사용
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(11-04. TF-IDF: Term Frequency-Inverse Document Frequency) (0) | 2024.04.16 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(11-03. 문서 단어 행렬: Document-Term Matrix, DTM) (0) | 2024.04.11 |
| Pytorch로 시작하는 딥러닝 입문(11-01. 텍스트의 유사도: 단어의 표현 방법) (0) | 2024.04.08 |
| 활성화 함수(시그모이드, ReLU, 소프트맥스) (0) | 2024.04.07 |
| Pytorch로 시작하는 딥러닝 입문(10-05. 펄플렉서티: perplexity, PPL) (0) | 2024.04.06 |