2023. 9. 20. 20:37ㆍ딥러닝 모델: 파이토치
♣ 전체 순서
1. 데이터 다운로드 및 독립변수와 종속변수 구성
2. 데이터를 이용하여 Dataset 만들기
3. Dataset을 이용하여 DataLoader 만들기
4. 데이터 정규화하기
5. 모듈과 파라미터 정의하기(Module, ConvLayer, LinearLayer, Parameter 등)
6. CNN 만들기(Sequential, AdatpivePool 등을 추가로 사용, 훅 추가하기)
7. 손실함수 정의하기
8. 옵티마이저 구현하기
9. DataLoaders 만들기
10. Learner class 만들기
11. 콜백 함수 정의하기
12. 위에서 만든 CNN, DataLoaders, 손실함수, 콜백함수, 학습률 등을 이용하여 Learner 사용하기(학습)
13. 학습률 스케줄링하기(보다 적절한 학습률을 찾는 것)
♣ 이미지 데이터 다운로드 및 확인, 종속변수(label) 구성하기

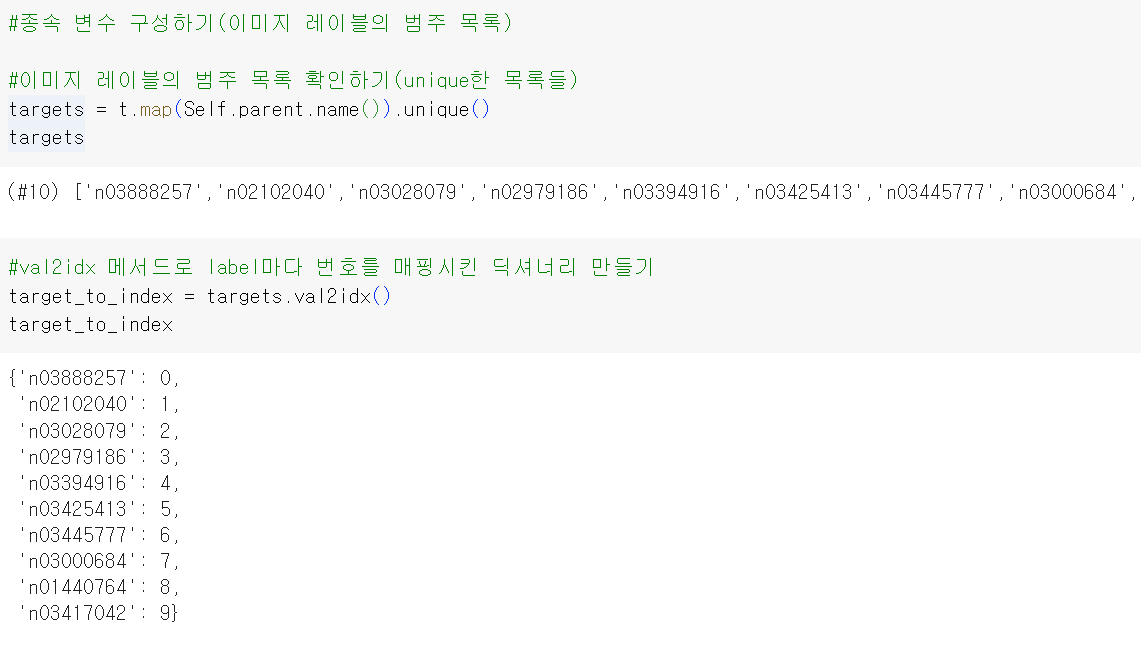
val2idx : 값을 key로, index를 value로 하여 Dictionary를 만듦. 즉 복잡한 label을 숫자 index로 바꿀 수 있음
♣ Dataset 만들기
Dataset은 데이터셋의 특징을 가져오고, 하나의 샘플에 정답(label)을 지정하는 일을 한 번에 함.
사용자 정의 Dataset 클래스는 반드시 3개 함수를 구현해야 함: __init__, __len__, __getitem__
- __init__: __init__ 함수는 Dataset 객체가 생성될 때 한 번만 실행됨.
- __len__: Dataset의 샘플 개수 반환
- __getitem__: 주어진 인덱스에 해당하는 샘플을 Dataset에서 불러오고 반환함.


train에는 train_filt가 true였던 train data들이 들어감
valid에는 train_filt가 false였던 valid date들이 들어감

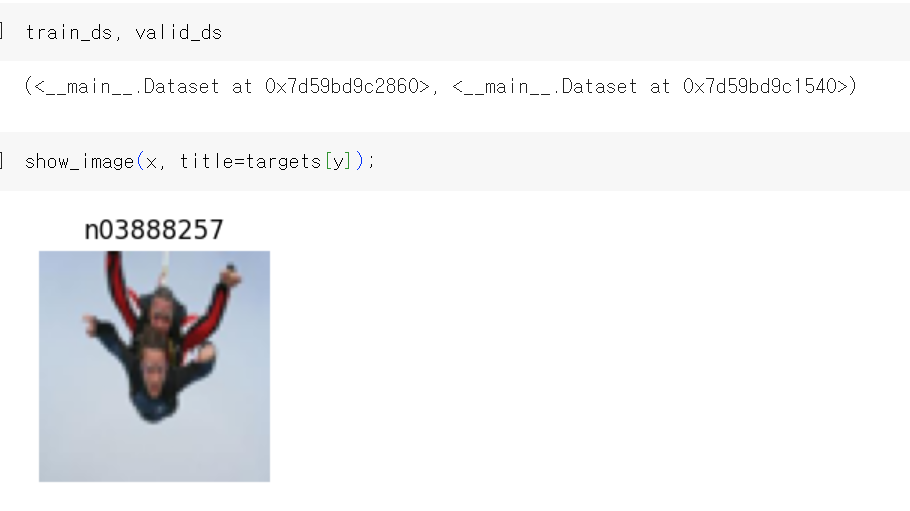
Dataset 클래스에 train dataset을 넣어서 train_dls를 만들면 2가지가 return됨. 표준화된 im 이미지와 label 명인 y.
x, y = train_dls[0]은 그 중 첫 번째 객체이고, x는 0번째 이미지를, y는 0번째 이미지의 label을 할당받음.
따라서 train_ds에 해당하는 첫 번째 이미지의 label은 0임.
*Dataset 클래스 만들기 Tutorial
https://tutorials.pytorch.kr/beginner/basics/data_tutorial.html
Dataset과 DataLoader
파이토치(PyTorch) 기본 익히기|| 빠른 시작|| 텐서(Tensor)|| Dataset과 DataLoader|| 변형(Transform)|| 신경망 모델 구성하기|| Autograd|| 최적화(Optimization)|| 모델 저장하고 불러오기 데이터 샘플을 처리하는 코
tutorials.pytorch.kr
* 사용자 정의 Dataset 만들기 코드 예시(FashionMNIST 예시)
https://colab.research.google.com/drive/1zyLpiOIVsqZidheC5a0KukVqcQTP4wEq#scrollTo=FKXnRH6t0VtR
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
♣ Dataset을 미니배치 형태로 재구성하기
PyTorch 데이터로더에서 배치(batch)를 생성하기 위한 collate 함수를 정의한 부분. 이 함수는 인덱스 목록과 데이터셋 객체를 받아서 해당 인덱스에 해당하는 예제들(데이터들)을 배치로 묶어주는 역할을 함.

Dataset 클래스와 collate 함수를 만들었으니 DataLoader를 정의할 준비가 됨.
DataLoader에는 DataSet과 collate 기능 외에 두 가지를 추가로 제공함: 학습용 데이터셋을 임의로 뒤섞는 shuffle을 선택적으로 활성화하는 기능과 전처리 작업을 병렬로 처리하는 ProcessPoolExecutor
♣ Dataset과 collate 함수를 이용하여 DataLoader 만들기




ds = 데이터를 불러올 데이터셋
bs = 배치 크기
shuffle = 데이터를 불러오기 전에 데이터를 셔플할지 여부
n_workers = 병렬 데이터 로딩에 사용할 워커 프로세스의 수
len 메소드: 데이터로더의 길이 정의. 데이터셋의 길이와 배치 크기를 기반으로 계산함. 데이터로더가 전체 데이터셋을 충분히 커버하는 배치를 제공하도록 함
iter 메소드: 데이터로더를 반복 가능한(iterable) 형태로 사용할 수 있게 하며 데이터 배치를 순환하는 데 사용함. 각 chunk는 하나의 배치에 대한 인덱스임. 셔플된, 또는 셔플되지 않은 인덱스를 배치 크기로 나누어 배치를 생성함
데이터를 병렬로 로딩하기 위해 ProcessPoolExecutor 사용
즉 idx를 사용하여 dataset을 shuffle한 뒤 batch 크기에 맞게 잘라서 chunks를 만들고, 이렇게 자른 chunks에 collate 함수를 사용하여 이미지는 이미지대로, label은 label대로 쌓아서 미니배치를 만드는 것.
♣ 데이터 정규화

- stats = [xb.mean((0, 1, 2)), xb.std((0, 1, 2))]: 이 코드는 두 가지 통계 정보를 계산하고 리스트 stats에 저장합니다.
- xb.mean((0, 1, 2)): xb는 이미지 데이터를 담고 있는 텐서(batch)입니다. .mean((0, 1, 2))를 사용하여 이 텐서의 평균을 계산합니다. (0, 1, 2)는 평균을 계산할 차원을 지정하는데, 여기서는 0, 1, 2가 사용되어 이미지 데이터의 모든 차원(높이, 너비, 채널)에서 평균을 계산합니다. 결과로 나온 평균은 RGB 이미지의 각 채널별로 계산된 값입니다.
- xb.std((0, 1, 2)): 마찬가지로 xb의 표준 편차를 계산합니다. 역시 (0, 1, 2) 차원에서 표준 편차를 계산하며, 각 채널별로 계산된 값입니다.
- stats: 계산된 평균과 표준 편차가 [평균값, 표준 편차값] 형태의 리스트로 저장됩니다. 이 통계 정보는 일반적으로 데이터 정규화(normalization) 단계에서 사용되며, 모델의 입력 데이터를 표준화하고 중심화하는 데 활용됩니다.
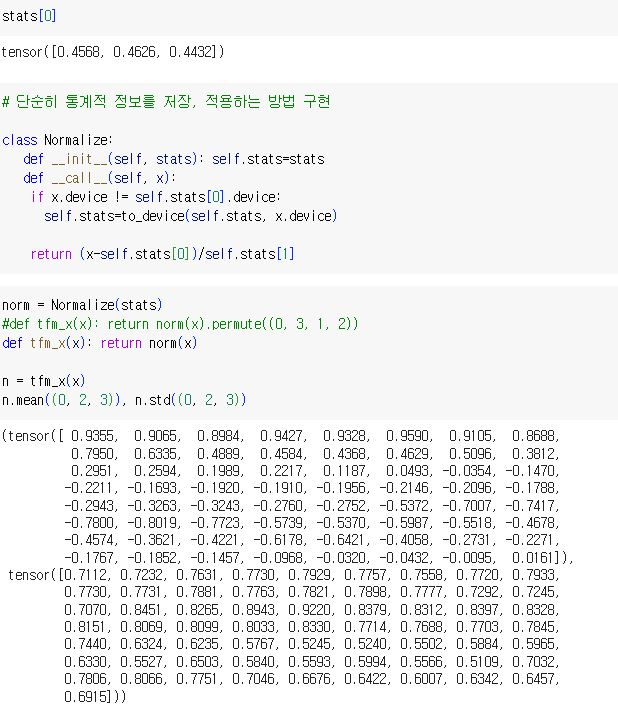
return (x - self.stats[0]) / self.stats[1]: 입력 데이터 x에서 평균 (self.stats[0])을 빼고, 그 결과를 표준 편차 (self.stats[1])로 나눠서 데이터를 정규화함. 이렇게 하면 데이터가 평균 0과 표준 편차 1을 가지도록 스케일링됨
norm 객체를 Normalize 클래스를 적용하여 만듦. tfm_x 함수에서 norm 객체를 생성한 후 이미지 차원의 순서를 바꾸는 것.
========================================오답노트============================================
처음에는 permute((0, 3, 1, 2))를 사용하여 이미지 차원을 변경했음. 기존 차원 순서가 (높이, 너비, 채널)인 이미지를 (배치, 채널, 높이, 너비)로 변경함. 이 작업은 주로 PyTorch와 같은 딥러닝 프레임워크에서 사용되는 기본 차원 순서로 변환하는 것임.
그런데 어떻게 된 일인지 뒤에서 Learner를 사용할 때 permute가 적용되어서 input의 차원이 [128, 3, 64, 64] 가 되면서 ConvLayer(3, 16)과 채널 수가 같을 것으로 생각했는데 그렇게 되지 않았음. 아래와 같은 Error가 뜸.
RuntimeError: Given groups=1, weight of size [16, 3, 3, 3], expected input[128, 64, 64, 3] to have 3 channels, but got 64 channels instead
input이 3개의 channel을 가져야 하는데 64개의 채널을 가지고 있어서 3개 채널로 시작하는 ConvLayer(3, 16)에 input으로 들어갈 수 없다는 것. 그래서 ConvLayer(64, 16)으로 바꿔서 채널을 64개로 맞추려고 했으나 계속 에러가 뜸.
input의 채널 수 자체가 잘못된 것이 아니라 앞에서 permute를 이용하여 차원을 미리 바꾼 것이 문제인가? Learner를 거치면서 그때그때 바꿔야 하는건가 라는 생각이 들어서 실행해봄.

♣ 모듈과 파라미터

PyTorch에서 사용되는 사용자 정의 Parameter 클래스를 정의하는 코드
Tensor 클래스를 확장하여 PyTorch 모델의 학습 가능한 파라미터를 나타냄
1. Parameter 클래스는 Tensor 클래스를 상속받아 'Tensor'의 기능을 포함하며 파라미터로 사용함
2. new 매서드는 Parameter 클래스의 생성자 역할. 새로운 Parameter 객체를 생성할 때 호출됨. make_subclass를 호출하여 새 Parameter 서브클래스를 생성하고 반환함.
3. init 매서드는 Parameter 클래스의 초기화 매서드. 파라미터를 초기화할 때 호출됨. requires_grad_를 호출하여 이 파라미터가 gradients를 계산하는 데 필요한지 여부를 설정함. requires_grad_는 학습 가능한 파라미터의 경우 True로 설정되어 파라미터가 역전파되는 동안 업데이트될 것임을 나타냄.
*requires_grad_는 속성(attribute)이며 메서드가 아님

Parameter 사용 예시. 텐서처럼 작동함.
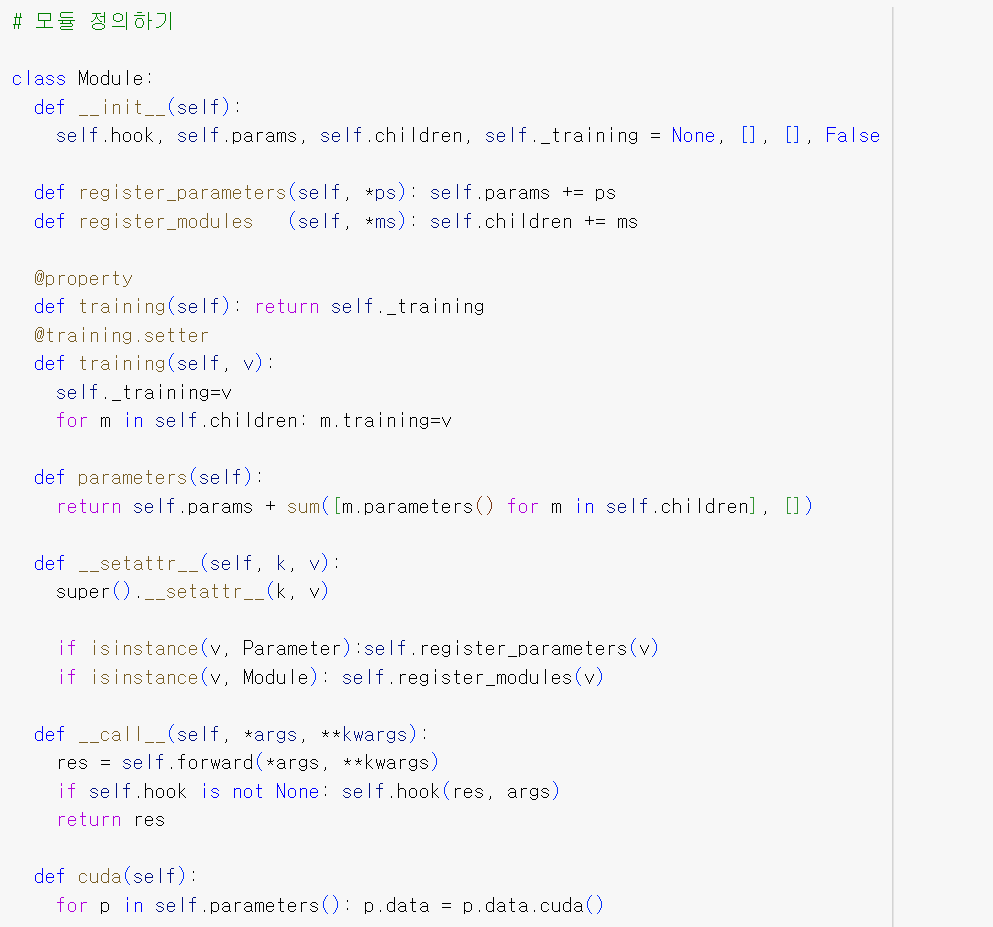
self.params + sum([m.parameters() for m in self.children], [ ]) 는 Module에 포함된 모든 파라미터를 반환함.
setattr 매서드로 인해 자신의 파라미터를 알 수 있음.
self.register_parameters(v) 코드가 앞에서 만든 Parameter 클래스를 마커로 사용함. 즉 Parameters 클래스의 모든 것을 params에 추가함.
call 메서드는 객체를 함수처럼 다룰 때 일어날 일을 정의함. forward 매서드를 호출하는데, Module에는 forward 매서드가 정의되지 않았으므로 이후 Module을 상속받는 하위 모듈에 추가되어야 함.

*weights vs bias
- 둘 다 입력 데이터를 기반으로 예측을 수행하는 데 사용되는 두 가지 유형의 parameter임
weights(가중치)
- 신경망 내의 뉴런 간 연결의 강도를 결정하는 parameter
- 가중치는 입력값이 뉴런을 통과하는 동안 입력값을 조정하는 데 사용됨
- 신경망 내에서 각 뉴런 간의 연결마다 하나의 가중치가 있음. 신경망 내의 가중치 수는 편향보다 훨씬 많음
bias
- 편향은 모델에 추가적인 자유도를 제공하여 뉴런의 활성화 함수를 이동시키는 역할을 하는 매개변수
- 각 뉴런에는 하나의 편향항이 연결되어 있으며 이는 상수값임
init = nn.init.kaiming_normal_ if act else nn.init.xavier_normal_
init(self.w)
합성곱레이어의 가중치를 초기화하는 역할. act 활성화 인자를 기반으로 적절한 가중치 초기화 방법을 선택함
- act가 True인 경우 nn.init.kaining_normal_을 선택함. 이는 ReLU와 같은 활성화 함수와 함께 사용하기 위해 설계된 가중치 초기화 방법으로, ReLU 활성화를 사용할 때 vanishing gradient 또는 exploding gradient와 같은 문제를 방지하는 데 도움을 줌
- act가 False인 경우 nn.init.xavier_normal_ 을 선택함. 이것은 시그모이드 또는 탄젠트와 같은 활성화 함수에 적합한 다른 가중치 초기화 방법임.
init(self.w)는 선택된 가중치 초기화 방법을 적용하여 합성곱 레이어의 가중치를 초기화함.
* ConvLayer 객체를 생성할 때마다 가중치를 초기화해야 하는 이유
1. 각 layer가 자신만의 가중치를 가짐
2. 가중치를 초기화함으로써 신경망 모델 내에서 서로 다른 가중치로 여러 layer를 쉽게 생성할 수 있음. 이로써 모델 다양성을 유지하고 다른 layer에서 서로 다른 특성을 학습할 수 있음

ConLayer에는 weight, bias로 가중치가 2개라는 의미.

xbt = tfm_x(xb)
입력 텐서 xb에 변환(tfm_x) 적용. 데이터 전처리 또는 정규화를 함. xb는 train dataloader의 첫 번째 미니배치임( 그 중 이미지).
r = l(xbt.permute((0, 3, 1, 2)))
변환된 입력 텐서 xbt를 합성곱 layer l에 통과시킴(입력채널이 3, 출력채널이 16인 합성곱 layer).
layer l은 가중치를 이용하여 입력 텐서에 합성곱 작업을 적용.
그냥 xbt를 넣으면 torch.Size([128, 64, 64, 3]) 이라서 차원이 안 맞음. permute((0, 3, 1, 2))를 해주면 차원이 (배치 크기, 채널 수, 너비, 높이)로 조정되어서 ConvLayer에 input으로 사용할 수 있음.
r.shape
출력 텐서 r의 형태를 검색함.
torch.Size([128, 16, 64, 64])
- 128은 미니배치 크기를 나타냄
- 16는 합성곱 레이어의 출력 채널 수를 나타냄
- 64, 64는 출력 텐서의 높이와 너비를 나타냄

self.w: 가중치는 출력 채널 수와 입력 채널 수에 의해 결정됨
self.b: 편향의 크기는 출력 채널 수와 동일함. 편향은 선형 연산 후에 더해지는 parameter임
nn.init.xavier_normal_ 은 시그모이드 또는 탄젠트와 같은 활성화 함수에 적합한 다른 가중치 초기화 방법
def forward는 순전파 연산을 정의함.
x@self.w.t() + self.b 는 입력 x와 가중치 행렬 w를 곱함. t는 행렬의 전치(뒤집는 것)을 나타내며 가중치 행렬을 전치함으로써 곱셈이 올바르게 수행됨. 그 다음 편향을 더해서 최종 결과를 반환함.

l = Linear(4, 2)
ni=4, if=2 인 Linear 객체 생성. 4차원의 input 공간을 2차원 output 공간으로 나타내야 함.
이는 classification 이나 regression과 같은 과제에서 사용됨
r = l(torch.ones(3, 4))
torch.ones(3, 4) 텐서를 이용하여 linear layer 객체를 생성함.

이 torch.ones(3, 4) 형태의 텐서를 Linear(4, 2) 객체에 적용함. torch.ones(3, 4) 텐서에 self.w.t()를 곱하고, self.b를 더하면 r이 생성됨.
torch.ones(3, 4)는 3X4 크기이고, self.w는 Parameter(torch.zerose(2, 4))인데 이걸 전치하니까 4X2 크기가 될 것. 그러면 3X4 행렬과 4X2 행렬을 곱해서 3X2 행렬이 나옴. 여기에 편향치를 나타내는 행렬을 더함.
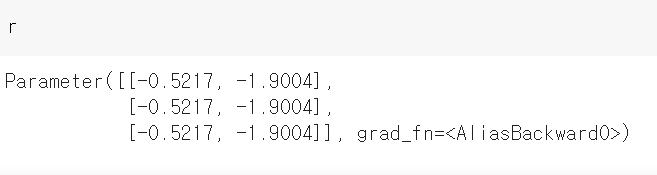

T 모듈에는 각각 편향과 가중치가 있는 합성곱과 선형 계층이 포함되므로 파라미터가 총 4개 있음
♣ 간단한 CNN 만들기

Sequential class는 Module을 상속받아서 register_modules 메서드를 사용함. 그래야 parameters 메서드 호출할 때 각 모듈의 parameter가 모두 나타남

위의 모듈을 호출하면 입력텐서에 mean을 적용하여 1X1 모양의 출력을 만듦. (2, 3)을 보면 2는 높이를 나타내는 차원임. 3은 너비를 나타내는 차원임.
즉 각 채널의 높이와 너비를 평균화해서 1X1 모양의 출력을 만드는 것

Sequentail, ConvLayer, AdaptivePool, Linear 모듈을 사용하여 간단한 CNN 신경망 정의
위의 simple_cnn을 그대로 쓰면 최종 channel의 수가 10개임. 이는 10가지 종류로 분류하는 task에서 사용할 수 있음. 각 channel에 부여되는 수는 각 labels로 분류될 확률을 의미함.

마지막 layer에서 output이 10개이므로 가중치 10개 세트와 편향 10개를 가지고 있을 것.

print_stats에서 outp (레이어의 출력)과 inp (레이어의 입력)가 인수로 들어감. 함수 내부에서는 outp 텐서의 평균과 표준 편차를 계산하고 출력함. 이 때 .mean() 및 .std() 메서드를 사용하며, .item()은 결과로 나온 평균과 표준 편차 텐서를 Python float 값으로 변환하여 출력함
for i in range(4)를 이용하여 CNN 신경망의 앞의 4개 ConvLayer에 hook을 적용함.

xbt = tfm_x(xb)
입력 텐서 xb에 변환(trm_x) 적용. 데이터 전처리 또는 정규화를 함. xb는 train dataloader의 첫 번째 미니배치에 해당하는 이미지임.
즉 데이터 전처리가 된 train dataloader의 첫 번째 미니배치를 이용하여 간단한 CNN 신경망을 만들어서 r로 정의한 다음 shape을 알아보면 128개 이미지마다 10개의 값을 가질 것.
소수점으로 프린트된 것은 각 ConvLayer에서 output 레이어의 평균과 표준편차임.
* hook이란?
신경망의 개별 레이어 또는 모듈에 연결할 수 있는 함수로, 신경망의 순전파 또는 역전파 중에 사용자 지정 작업을 수행하는 데 사용됨. 위의 경우, 순전파 과정 중에 레이어 출력의 통계(평균과 표준 편차)를 출력하기 위한 후크를 설정한 것
♣ 손실 함수 정의하기

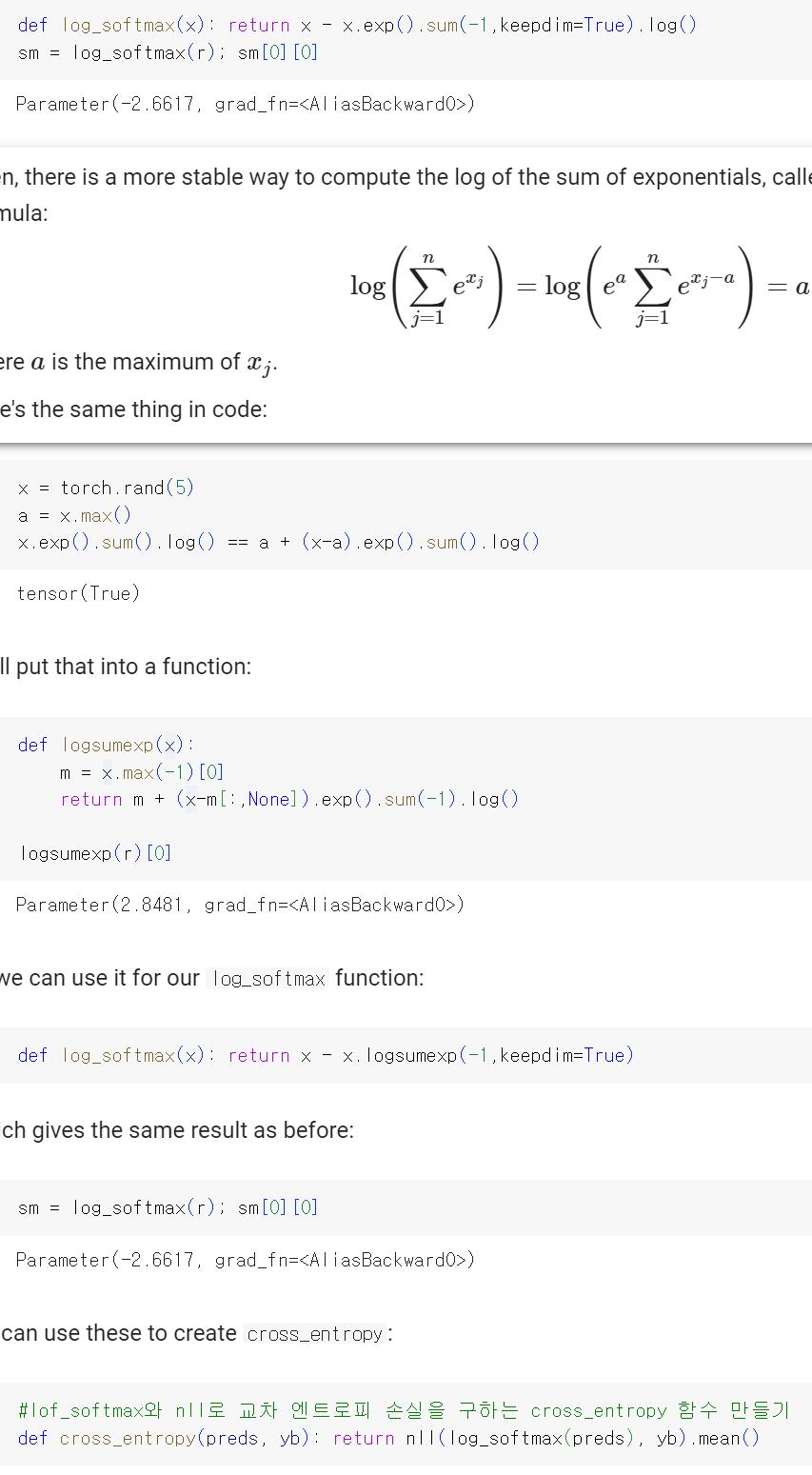
♣ Learner 정의하기
지금까지 데이터, 모델, 손실 함수를 만들었음. 마지막으로 옵티마이저 만들기
* 옵티마이저 관련 설명
https://jy-deeplearning.tistory.com/6
옵티마이저(최적화)의 의미와 경사하강법(Gradient Descent)
♣ 최적화(옵티마이저) 손실함수 값을 최소화하는 파라미터를 구하는 과정 즉 모델이 예측한 값과 실제값의 차이를 최소화하는 신경망 구조의 파라미터를 찾는 과정 손실함수 값의 변화에 따라
jy-deeplearning.tistory.com

딥러닝 모델을 훈련하는 데 사용되는 최적화 알고리즘 중 하나로, 모델 파라미터를 업데이트하여 손실 함수를 최소화함
params: 최적화할 모델의 파라미터들을 나타내는 리스트
wd(weight decay): 가중치 감소
for 루프를 사용하여 모델의 각 파라미터 p에 대해 다음과 같은 업데이트를 수행합니다:
- p.data -= (p.grad.data + p.data*self.wd) * self.lr: 현재 파라미터의 데이터를 업데이트합니다. 이때, 경사(그래디언트)를 기반으로 하며, lr은 학습률, wd는 가중치 감소를 나타냅니다. 이러한 학습률과 가중치 감소를 사용하여 파라미터를 업데이트하면 모델이 손실을 줄이는 방향으로 이동합니다.
- p.grad.data.zero_(): 파라미터의 그래디언트를 0으로 초기화합니다. 이는 각 업데이트 스텝 이후에 그래디언트를 리셋하여 새로운 스텝에서 그래디언트를 누적하지 않도록 합니다.

위에서 만든 DataLoader를 저장하는 DataLoaders 모듈

1. __init__(self, model, dls, loss_func, lr, cbs, opt_func=SGD
클래스 초기화 메서드
cbs: 콜백 함수들의 리스트
opt_func: 옵티마이저 함수로, 기본값은 SGD
cb.learner는 Learner 클래스의 속성 중 하나. 콜백 객체(cb)가 현재 사용 중인 Learner 인스턴스를 참조하게 됨. 이를 통해 콜백은 학습 중에 모델, 데이터셋, 손실함수 등 다양한 학습 관련 객체에 접근하고 상호작용할 수 있음.
2. one_batch
학습 데이터로 한 번의 배치를 처리하는 메서드
'before_batch_ " 콜백을 호출함
xb(입력데이터)와 yb(레이블)을 가져와 모델에 전달하여 예측값과 손실을 계산함. 이때 앞에서 한 것처럼 데이터마다 permute((0, 3, 1, 2))를 사용하여 차원 바꾸기
모델이 학습 중인 경우 역전파를 수행하고, 옵티마이저를 업데이트함.
'after_batch_' 콜백을 호출함.
3. one_epoch
한 번의 epoch 동안 학습 또는 검증 데이터셋을 처리하는 메서드
train 매개변수에 따라 학습 데이터셋 또는 검증 데이터셋을 선택
'before_epoch' 콜백 호출
데이터로더에서 배치 단위로 데이터를 가져와서 one_batch를 호출하여 처리함
4. fit
주어진 epoch 수만큼 모델을 학습시키는 메서드
옵티마이저를 초기화하고 주어진 epoch 수만큼 반복
학습 도중 예외가 발생하면 학습을 중단하고 'after_fit' 콜백을 호출
5. __call__
콜백 함수들을 호출하는 메서드. 'name'은 호출할 콜백의 이름
콜백 객체의 이름에 해당하는 메서드를 호출하되, 만약 해당하는 메서드가 없으면 아무 작업도 수행하지 않는 noop 함수를 호출

Learner에 있는 정보에 접근하거나 변경하는 것을 더 쉽게 하려고 Callback을 GetAttr의 하위 클래스로 정의하고, 기본 속성에 learner를 할당함.
GetAttr은 fastai에서 정의한 클래스로, 파이썬의 표준 메서드인 __getattr__과 __dir__를 구현함. 존재하지 않는 속성에 접근할 때마다 해당 속성을 _default가 가리키는 부분(여기서는 learner)로 전달하는 기능을 함.
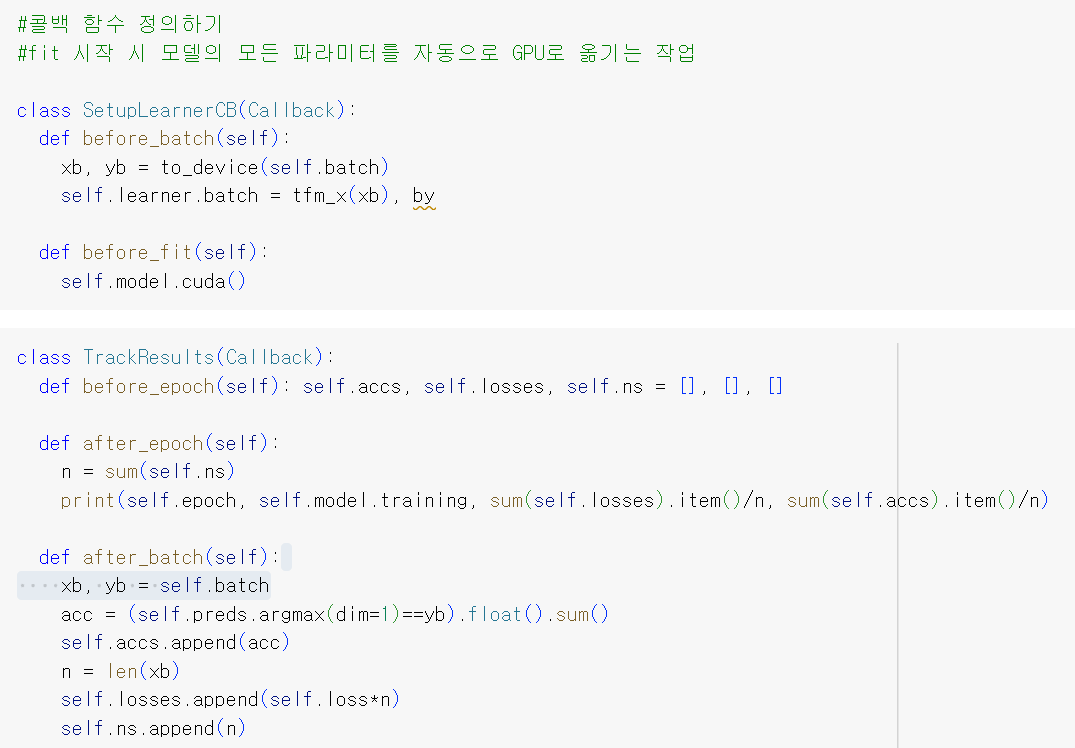
콜백 함수 정의하기


1. before_epoch
각 훈련 epoch가 시작하기 전에 실행됨
현재 epoch에 대한 정확도(self.accs), 손실(self.losses), 및 샘플 수(self.ns)를 저장할 빈 리스트를 초기화함
2. after_epoch
각 훈련 epoch가 완료된 후에 실행됨
아래의 정보를 계산하여 출력
self.epoch: 현재 epoch 번호
self.model.training: 모델이 훈련 모드인지(True), 평가 모드인지(False)인지 여부
sum(self.losses).tiem()/n: epoch 내 모든 배치의 평균 손실
sum(self.accs).item()/n: epoch 내 모든 배치의 평균 정확도
3. after_batch
각 훈련 배치가 완료된 후에 실행됨
현재 배치에 대한 정보를 계산하고 저장함
acc: 배치의 정확도로, 올바르게 예측된 샘플 수를 배치 내 전체 샘플 수로 나눈 비율
n: 배치 내의 샘플 수
self.loss * n: 배치에 대한 총 손실
계산된 정확도, 손실 및 샘플 수를 해당 리스트에 추가하여 epoch 전체에서 추적함.

Learner를 이용하여 학습하기

학습률 탐색은 모델을 훈련하기 전에 적절한 학습률을 찾기 위해 사용되며, 학습률을 조절하면 모델의 학습곡선을 관찰하여 안정적인 훈련을 달성할 수 있음.
LRFinder 클래스는 Callback 클래스를 상속하며, 학습률 탐색을 위한 콜백 기능을 정의함
1. before_fit
훈련 시작 전에 호출됨. 초기 학습률(self.learner.lr)을 매우 작은 값인 1e-6으로 설정함. 이 작은 학습률에서부터 시작하여 점진적으로 높여가며 손실 관찰
2. before_batch
각 미니배치 훈련 전에 호출됨. 모델이 훈련 중인 경우에만 실행됨.
if not self.model.training은 현재 모델이 훈련 중인지를 확인하는 조건문임. PyTorch의 모델은 .train( ) 및 .eval( ) 메서드를 사용하여 훈련 및 추론 모드로 전환할 수 있음.
현재 학습률을 1.2배로 증가시킴. 이렇게 함으로써 매 미니배치마다 학습률이 증가하게 됨.
3. after_batch
각 미니배치 훈련 후에 호출됨. 모델이 훈련 중인 경우에만 실행됨. 학습률이 너무 높거나 NaN 값이 되면 훈련을 중단하고 CancelFitException 예외를 발생시킴. 또한 현재 미니배치에서의 손실과 학습률을 기록함.
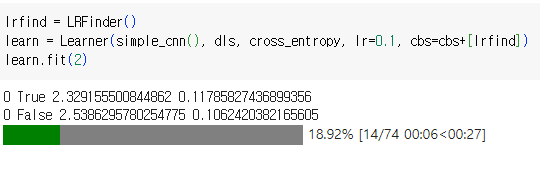
위에서 정의한 LRFinder 클래스를 이용하여 객체 생성. Learner에 적용하여 훈련함. lr=0.1이긴 하지만 LRFinder를 사용하므로 초기 학습률이 1e-6에서부터 시작하게 됨.
중간에 학습이 멈추는 이유
- 학습률이 너무 높음: Learning Rate Finder는 학습률이 두 번째 에포크 동안 너무 높아져 손실이 급격히 증가하는 것을 감지했을 수 있습니다. 이것은 과도하게 높은 학습률이 불안정한 학습과 발산을 초래할 수 있기 때문에 문제가 될 수 있습니다.
- 손실값이 NaN (숫자가 아님)이 됨: 다른 가능성은 손실값이 두 번째 에포크 동안 NaN (숫자가 아님)이 되었을 때 일어날 수 있습니다. 이는 일반적으로 학습률이 극도로 높고 모델의 매개변수가 수치적으로 불안정한 상태에서 발생합니다.
- 임계값 달성: LRFinder에는 학습률과 손실값에 대한 미리 정의된 임계값이 있을 수 있으며, 이러한 임계값이 초과되면 학습률 탐색을 일찍 중단시킵니다. 코드에서 학습률이 10보다 큰 경우 탐색을 중단하기 위한 조건을 확인하는데, 이 조건이 충족되면 CancelFitException을 발생시켜 훈련을 중지합니다.
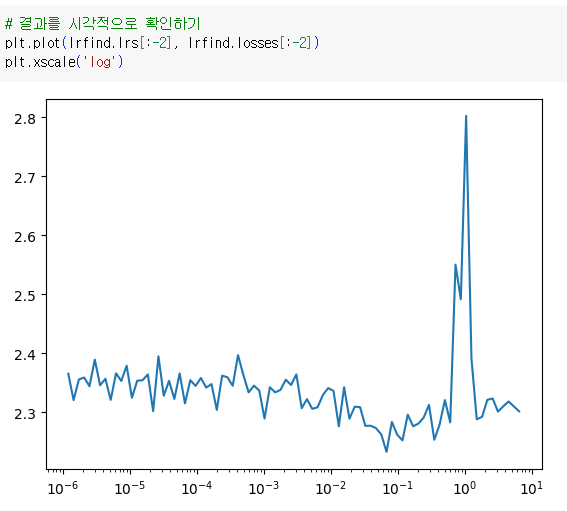
lrfind.lrs는 LRFinder에서 정의했던 lrs에 해당함. 테스트 중에 다양한 학습률을 포함하는 목록. [:-2] 슬라이싱은 마지막 두 학습률을 제외한 것. 끝단의 학습률은 너무 높거나 너무 낮아서 손실 곡선에서 이상한 동작을 할 수 있기 때문에 제외하는 것이 일반적인 관행임.
lrfind.losses는 각 학습률에서 얻은 손실값을 나타냄.
위의 시각자료를 보면 epoch 중에 학습률이 10을 넘어가서 멈춘 것으로 예상됨
*콜백 함수를 사용하는 이유
콜백 함수는 못델 학습 중에 직접 학습 루프나 모델을 수정하지 않고도 다양한 작업을 수행함. 주요 코드를 더럽히지 않고 학습 프로세스를 확장하고 사용자 정의하는 유연한 방법을 제공함.
- 모듈성: 콜백을 사용하면 특정 기능을 별도의 모듈로 캡슐화할 수 있습니다. 예를 들어 학습률 스케줄링, 조기 중단, 모델 체크포인트 및 로깅에 대한 다른 콜백이 있을 수 있습니다. 이러한 콜백을 별도로 정의하면 학습 코드는 깔끔하고 체계적인 상태를 유지합니다.
- 재사용성: 콜백 함수를 정의한 후 다양한 학습 실행과 모델에서 재사용할 수 있습니다. 이렇게 하면 서로 다른 실험을 위해 동일한 논리를 다시 작성할 필요가 없으므로 시간과 노력을 절약할 수 있습니다.
- 유연성: 콜백은 학습 프로세스를 사용자 정의하는 유연성을 제공합니다. 다양한 학습 전략을 실험하거나 프로젝트 요구 사항을 적용하기 위해 간단하게 콜백을 추가, 제거 또는 변경할 수 있습니다.
- 실시간 모니터링: 콜백을 사용하면 학습 진행 상황을 실시간으로 모니터링할 수 있습니다. 예를 들어 콜백을 사용하여 메트릭을 추적하고 학습 곡선을 그리며 모델 예측을 시각화할 수 있습니다. 이를 통해 학습 조정에 관한 정보를 실시간으로 얻을 수 있습니다.
- 조기 중단 및 학습률 스케줄링: 조기 중단 및 학습률 앤닝과 같은 콜백은 효율적인 학습을 위한 중요한 도구입니다. 이러한 콜백은 과적합을 방지하고 학습 매개변수를 실시간으로 조정하여 수렴을 개선하는 데 도움을 줍니다.
학습 결과 확인

원 사이클 class는 딥러닝에서 인기 있는 학습률 스케줄로, 훈련 중에 학습률을 특정한 패턴으로 변화시킴. 일반적으로 낮은 학습률로 시작하여 최댓값까지 증가시킨 후 다시 서서히 감소시킴. 훈련 효율성과 모델 성능을 향상시키는 데 도움이 됨
1. __init__(self, base_lr)
클래스의 생성자. base_lr은 기본 학습률로, 훈련 중에 사용될 최소 학습률을 의미함. 후에 Learner를 훈련시킬 때, lr=0.1로 정의함. 그러면 base_lr이 0.1이 되는 것. 즉 학습률은 초기값인 0.1에서 시작.
2. before_fit(self, base_lr)
훈련이 시작되기 전에 호출되는 메서드. lrs라는 빈 리스트를 초기화하여 각 배치에서의 학습률을 저장함
3. before_batch(self)
각 훈련 배치가 시작되기 전에 호출되는 메서드. 원 사이클 학습 스케줄에 기반하여 현재 배치에 대한 학습률을 계산하고 설정함.
n: 훈련 데이터셋의 총 배치 수
bn: 훈련 프로세스 내 현재 배치 번호
mn: 모든 에포크 동안 처리될 총 배치 수
pct: 지금까지 완료된 배치의 백분율
pct_start, div_start: 원 사이클 스케줄의 모양을 결정하는 상수
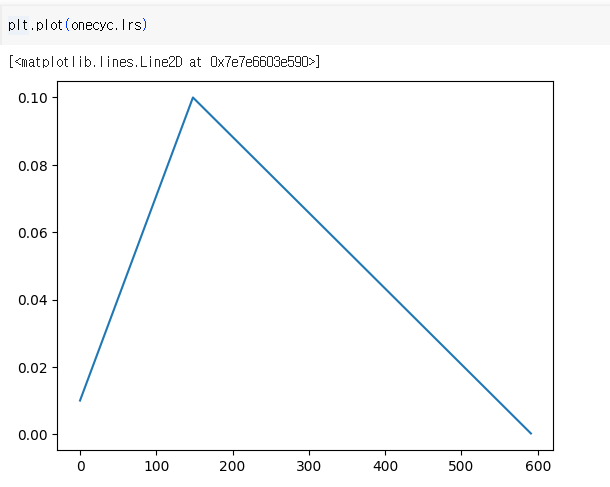
x축은 훈련 단계, 또는 epoch를 나타냄
y축은 학습률을 나타냄
훈련 중 첫 25% 동안(pct_start=0.25라고 정의된 부분) 학습률은 base_lr의 일부에서 전체 base_lr까지 선형으로 증가함.
첫 25% 이후, 학습률은 전체 base_lr에서 낮은 값까지 선형으로 감소하며 훈련의 나머지 75% 동안 이 값으로 유지됨
- 시작 시 낮은 학습률: 훈련은 상대적으로 낮은 학습률로 시작됩니다. 이것은 일반적으로 모델이 초기 훈련 단계에서 천천히 안정적으로 수렴하도록 하는 데 사용됩니다. 낮은 학습률로 시작하면 모델이 가중치와 편향을 조금씩 조정할 수 있습니다.
- 학습률 급증: 초기 단계(일반적으로 전체 훈련 단계 또는 에포크의 25% 주변에서, 코드에서 pct_start로 정의) 이후에는 학습률이 급격하게 증가합니다. 이 단계를 "웜업(warm-up)" 단계라고 합니다. 이 단계의 목적은 높은 학습률을 사용하여 모델이 빠르게 가중치 공간을 탐색하고 지역 최소값에서 벗어나도록 하는 것입니다. 이는 손실 공간에서 잠재적인 플래토 상태를 극복하는 데 도움을 줄 수 있습니다.
- 학습률 점진적 감소: 급격한 증가 이후 나머지 훈련 단계 또는 에포크(전체 훈련 단계 또는 에포크의 75%에 해당) 동안 학습률은 점진적으로 감소합니다. 이를 "앤닐링(annealing)" 단계라고 합니다. 이 단계에서 학습률을 감소시키면 모델이 가중치를 미세 조정하고 안정된 솔루션으로 수렴하도록 돕습니다. 이 단계에서 낮은 학습률은 모델이 더 정확하고 안정된 솔루션으로 수렴하도록 돕습니다.
♣ 관련 코드
https://colab.research.google.com/drive/1-To8wKIN9XyjHhCEcMzRblX-aLlxdnMv#scrollTo=3tzPzNSYuSXI
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| epoch vs 배치 크기 vs 반복 횟수 (0) | 2023.10.22 |
|---|---|
| 파이토치 튜토리얼 (1) | 2023.10.07 |
| DataBlock와 DataLoader 비교 (0) | 2023.09.17 |
| ImageDataLoaders vs ImageDataBunch (0) | 2023.08.15 |
| 텐서(Tensor) (0) | 2023.08.07 |