2023. 11. 3. 21:41ㆍEfficientNet
♣ 데이터 둘러보기(4가지 label 중 하나로 다중분류)


♣ 데이터 시각화


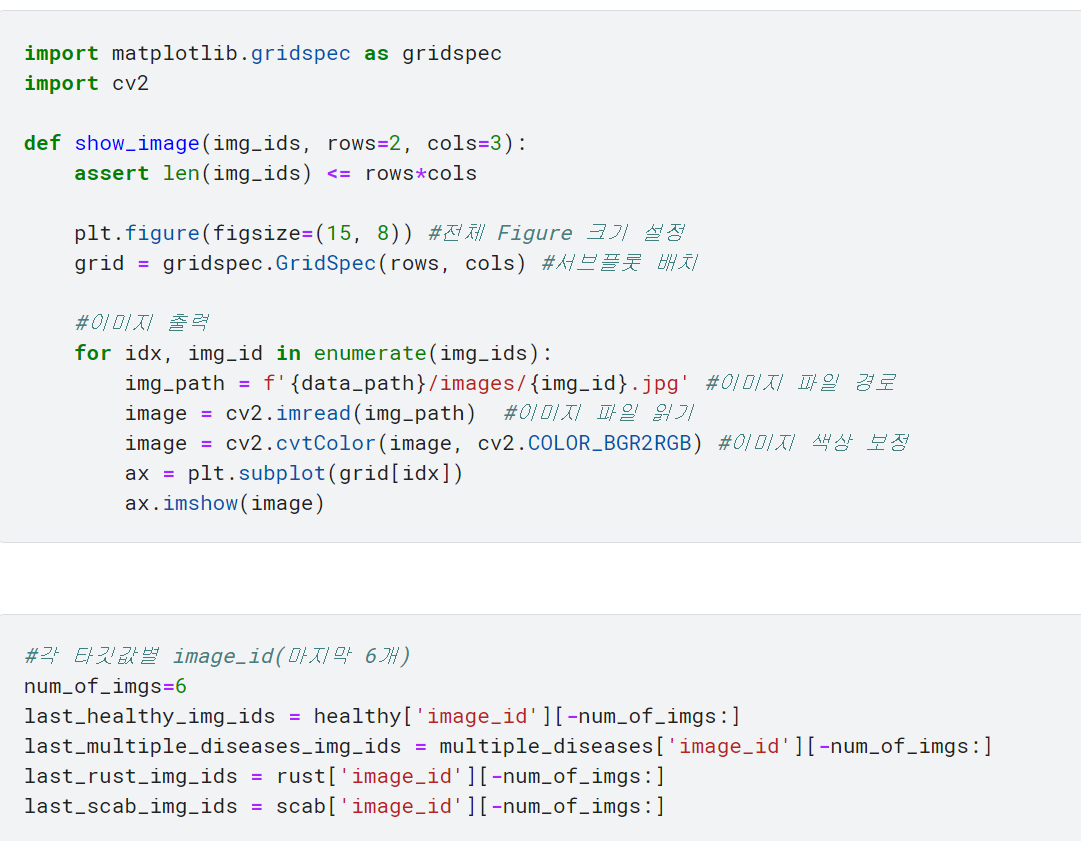
♣ 이미지 출력

♣ 베이스라인 모델
1. 시드값 고정 및 GPU 장비 설정: 재현성을 위해 랜덤 시드를 고정.

2. 데이터 준비: train, valid로 나누기

타깃값이 골고루 분포되도록 분리하기 위해 stratify 파라미터에 타깃값 4개를 전달함.
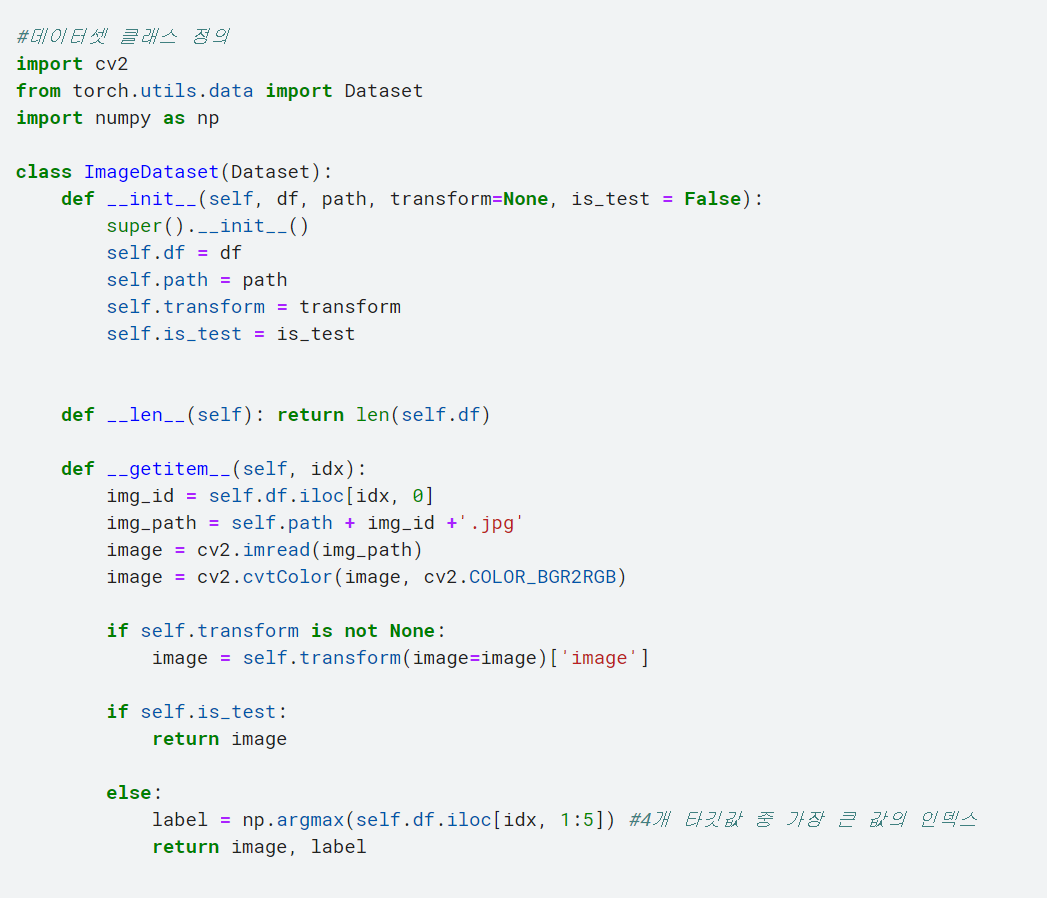
3. 데이터셋 클래스 정의하기
4. 이미지 변환기 정의하기
이 전까지 주로 torchvision 모듈에서 제공하는 변환기를 사용했지만, 이번 대회에서는 albumentations 모듈의 변환기 사용
albumentations는 이미지 증강을 위한 파이썬 라이브러리임.

Resize: 이미지 크기를 조절하는 변환기. 여기서는 임의로 450, 650으로 설정.
RandomBrightnessContrast: 이미지의 밝기와 대비를 조절하는 변환기
- brightness_limit=0.2 면 -0.2~0.2 범위의 밝기 조절자를 갖는다는 의미. 이 범위에서 임의로 밝기 조절값을 뽑아서 적용함. 전체 범위는 -1~1임. -1이면 완전 어둡게(아예 검은색 이미지로) 변하고, 1이면 완전 밝게(아예 하얀 이미지로) 변함.
즉 값이 클수록 이미지 밝기가 많이 변함.
- contrast_limit: 이미지 대비 조절값 설정. 동장방식은 brightness_limit와 같음
- p:적용 확룰 설정. 0.3을 전달하면 30%의 확률로 변환기를 적용함
ShiftScaleRotate: 이동, 스케일링, 회전 변환기
- shift_limit: 이동 조절값
- scale_limit: 스케일링 조절값
- rotate_limit: 회전 각도 조절값
OneOf: 여러 변환 중 하나를 선택하여 변환
- Emboss: 양각화 효과
- Sharpen: 날카롭게 만드는 효과
- Blur
PiecewiseAffine: 어파인 변환기. 이동, 확대/축소, 회전 등으로 이미지 모양을 전체적으로 바꾸는 변환.
Normalize: 값을 정규화하는 변환기. torchvision의 transforms.Normalize와 비슷함
ToTensorV2: 이미지 데이터를 텐서 형식으로 변환. torchvision의 transforms.ToTensor와 비슷함.

Resize, ToTensor

Resize, ToTensor, RandomBrightnessContrast

Resize, ToTensor, RandomBrightnessContrast, VerticalFlip

Resize, ToTensor, RandomBrightnessContrast, VerticalFlip, HorizontalFlip

Resize, ToTensor, RandomBrightnessContrast, VerticalFlip, HorizontalFlip, ShiftScaleRotate

*albumentations 정리글
https://jy-deeplearning.tistory.com/35
albumentations
albumentations: 이미지 증강을 위한 파이썬 라이브러리 ♣ 이미지 증강 4단계 1. albumentations 및 이미지를 읽는 라이브러리 import 하기 2. 증강 파이프라인 정의하기 3. 이미지 읽어오기 4. 이미지를 증
jy-deeplearning.tistory.com
♣ 데이터셋 및 데이터 로더 생성



♣ 모델 생성
사전 훈련 모델(pretrained model): 한 분야에서 훈련을 마친 모델
전이 학습(transfer learning): 사전 훈련 모델을 유사한 다른 영역에서 재훈련시키는 기법
파이토치로 사전 훈련 모델을 이용하는 방법(3가지)
1. torchvision.models 모듈 이용
2. pretrainedmodels 모듈 이용
https://github.com/Cadene/pretrained-models.pytorch#pretrained-models-for-pytorch-work-in-progress
GitHub - Cadene/pretrained-models.pytorch: Pretrained ConvNets for pytorch: NASNet, ResNeXt, ResNet, InceptionV4, InceptionResne
Pretrained ConvNets for pytorch: NASNet, ResNeXt, ResNet, InceptionV4, InceptionResnetV2, Xception, DPN, etc. - GitHub - Cadene/pretrained-models.pytorch: Pretrained ConvNets for pytorch: NASNet, R...
github.com
3. 직접 구현한 모듈 이용
본 대회에서는 EfficientNet 사용

*EfficientNet 설명 정리글
https://jy-deeplearning.tistory.com/39
EfficientNet
♣ 개념 적은 파라미터 대비 압도적인 성능이 특징인 모델 모델 성능 = resolution*depth*width(= 이미지 크기*네트워크의 깊이*필터 수) 기존에는 위의 세 가지 요소를 수동으로 조절했지만, 깊이와 필
jy-deeplearning.tistory.com
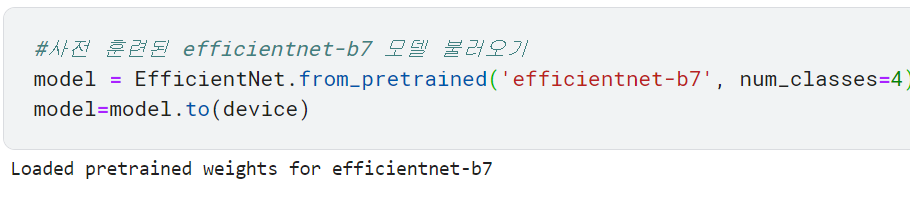
num_classes 파라미터는 최종 출력값 개수를 뜻함. EfficientNet은 타깃값이 1000개인 이미지넷 데이터로 사전 훈련한 모델이므로 num_classes에 아무 값도 전달하지 않으면 최종 출력값이 1000개가 됨. 본 대회에서 예측해야 하는 타깃값은 총 4개이므로 4를 전달함.
*출력값을 4개로 바꾸는 또 다른 방법

♣ 모델 훈련 및 성능 검증

AdamW: Adam에 가중치 감쇠를 추가로 적용해서 일반화 성능이 더 우수함
*가중치 감쇠(weight_decay): 가중치를 작게 조절하는 규제 기법으로, 과대적합을 억제함
preds=torch.softmax(outputs.cpu(), dim=1).numpy()
- torch.softmax에 dim=1을 적용하면 특정한 차원을 따라 동작함. 이 경우, dim=1은 열을 따라서 softmax 함수가 적용되는 것을 의미함. 즉 텐서의 각 행(각 샘플)에 대해 softmax 함수가 각 열(서로 다른 클래스)를 기반으로 확률 분포를 계산한다는 것. 열에 따라 softmax를 적용함으로써, 각 행 내에서 각 클래스에 대한 값(확률)의 합이 1이 되도록 보장함.
- 텐서의 각 행(샘플)에 대해 softmax 함수가 각 열을 기반으로 작동합니다.
- softmax 함수는 각 행의 값을 정규화하여 확률 분포로 변환합니다. 이 분포는 각 클래스에 대한 샘플이 속할 확률을 나타냅니다.
- 각 행 내에서 이러한 확률들이 1이 되도록 하는 것은, 각 샘플의 각 클래스에 대한 확률이 0부터 1 사이의 범위 내에서 잘 조정되어 있고, 그 합이 1이라는 확률 분포의 요건을 충족하는 것입니다.
♣ 예측 밎 결과 제출


preds_dim과 preds_part, preds를 print 했을 때 첫 번째 mini batch에서의 결과
pred_dim 값을 보면

미니배치 사이즈가 4니까 이미지가 4개라서 행이 4개고, 각 행에서의 각 열은 해당 이미지가 4개 labels에 해당할 확률을 의미함.

preds_part를 보면 preds_dim 값을 squeeze한 뒤 numpy를 적용함.
preds_dim과 preds_part는 사실상 동일한 값이지만 데이터 유형이 다름. 첫 번째 값은 PyTorch 텐서로 표현되었으며 두 번째 값은 Numpy 배열로 표현됨.
preds가 np.zeros(len(test_df), 4)) 여서 여기에 맞춰서 더하기 위해 preds_part는 Numpy로 형태를 바꾼 것으로 보임.

preds를 보면 위의 미니배치부터 preds_part를 더해서 각 이미지가 각각의 label에 해당할 확률값을 더하고 있음. 모든 미니배치가 다 돌아가면 모든 값이 채워짐.

♣ 성능 개선
1. epoch 늘리기
2. 스케줄러 추가
3. TTA(테스트 단계 데이터 증강) 기법
4. 레이블 스무딩 적용
[스케줄러 설정]
스케줄러는 훈련 과정에서 학습률을 조정하는 기능 제공. 빠르게 가중치를 갱신하기 위해, 훈련 초반에는 학습률이 큰 게 좋음. 훈련을 진행하면서 학습률을 점차 줄이면 최적 가중치를 찾기가 더 수월함.
- get_cosine_schedule_with_warmup 스케줄러
: 지정한 값(옵티마이저에서 지정한 학습률)만큼 학습률을 증가시켰다가 코사인 그래프 모양으로 점차 감소시키는 스케줄러

epoch 수를 39로 크게 늘림. 베이스라인에서는 5였음. epoch이 너무 작으면 과소적합, 너무 많으면 과대적합이 일어나기 쉬움.
스케줄러의 첫 번째 파라미터는 옵티마이저. 해당 옵티마이저로 가중치를 갱신할 때 스케줄러로 학습률을 조정함. 학습률은 매 훈련 이터레이션마다 갱신됨.
num_warmup_steps는 몇 번만에 지정한 학습률(여기서는 0.000006)에 도달할지를 의미함. 1 epoch의 반복 수는 len(train_dl)임. 3 epoch 만에 지정한 학습률에 도달하도록 len(train_dl)*3을 전달함. 정해진 값은 없으며 총 반복 수 (len(train_dl))*epochs 에 비해 상대적으로 작은 값이면 OK!
num_training_stepos는 모든 훈련을 마치는 데 필요한 반복 횟수를 의미함. 총 39 epoch만큼 훈련하니까 len(train_dl)*epochs를 전달함.
학습률이 선형으로 점점 증가하여 epoch 3에서 지정한 학습률에 도달함. 그 다음부터는 코사인 그래프 모양으로 학습률이 점차 감소함.
모델 훈련 및 성능 검증에 스케줄러 학습률 갱신 코드 추가

[TTA 기법]
- TTA
앞서서 albumentations를 활용하여 훈련 데이터를 증강시켰던 것처럼 데이터 증강 기법을 테스트 단계에서도 이용하여 예측 성능을 더 끌어올리는 기법을 TTA(Test-Time-Augmentation)이라고 함
일반적으로는 훈련된 모델이 테스트 데이터 원본을 활용하여 타깃값을 예측하지만 TTA를 적용하면 테스트 데이터를 여러 차례 변형한 뒤 예측함. 따라서 테스트 데이터가 늘어난 것과 같은 효과를 얻음.
TTA를 활용하여 예측하는 절차
1. 테스트 데이터에 여러 변환을 적용함
2. 변환된 테스트 데이터별로 타깃 확률값을 예측함
3. 타깃 예측 확률의 평균을 구함.
3단계에서 구한 평균 확률을 최종 제출값으로 사용함. => 앙상블 효과가 있어서 원본 데이터로 한 차례만 예측할 때보다 성능이 높아질 가능성이 큼.

위 그림에서 보면 원본으로만 예측할 땐 rust일 확률이 0.7로 가장 높음. 한편, 데이터를 네 차례 변환(TTA 적용)한 뒤 변환한 데이터로 타깃값을 예측하여 평균내면 scab일 확률이 0.7로 가장 높음.
TTA를 적용하면 앙상블 효과가 나타나서 예측 확률이 바뀜.

원래 baseline대로 원본 dataset과 DataLoader를 만들고, 훈련 데이터처럼 데이터 증강을 수행할 TTA dataset과 DataLoader를 만든다.

원본 테스트 데이터를 이용해서 결과를 예측하고, TTA를 이용해서 결과를 예측함
num_TTA는 TTA를 7번 수행했음을 의미함.
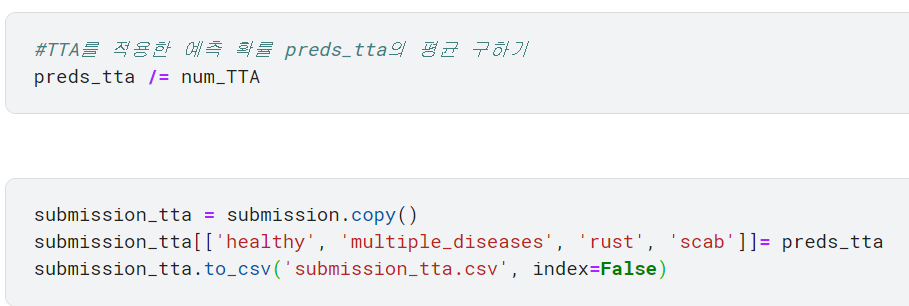
TTA(데이터증강)을 7번 실시했으므로 preds_tta 값을 7로 나눠서 평균을 구함.
그 값을 submission에 넣기

원본 테스트 데이터셋을 이용한 예측 결과
[레이블 스무딩 기법(label smoothing)]
간혹 딥러닝 모델이 과잉 확신하는 경우, 일반화 성능이 떨어질 우려가 있음
일반화 성능을 높이려면 과잉 확신한 예측값을 보정해야 함. 이럴 때 사용하는 보정 기법이 레이블 스무딩임

알파가 0이면 보정한 값이 원래 예측값과 똑같고, 1이면 모든 타깃 예측값이 1/K로 같아짐.
알파가 클수록 보정 강도가 강해짐
<preds가 (0, 0, 1, 0) 이고 알파가 0.1일 때의 예시>
타깃값 개수 K = 4
preds=(0, 0, 1, 0) 이므로 세 번째 타깃값을 과잉 확신함.


df: DataFrame
target: 타깃값 이름의 리스트
alpha: 레이블 스무딩 강도
threshold: 레이블 스무딩을 적용할 최솟값(타깃값이 임곗값을 넘을 때만 적용)
각 타깃값에 대해 임곗값을 넘는지 판단함. 임곗값을 넘으면 과잉 확신한 것으로 간주하여 레이블 스무딩을 적용
예를 들어 row가 (0.025, 0.025, 0.925, 0.025)이고 threshold가 0.9 이면 (row > threshold).any( )는 True임.
any( )는 모든 값 중 하나라도 참이면 True를 반환함. 0.925가 0.9보다 크므로 이 값은 True임.
타깃값이 임곗값을 넘으면 레이블 스무딩을 적용함. 그런 다음 현재 타깃값을 '레이블 스무딩을 적용한 값'으로 변환
위의 함수를 원본 데이터를 이용한 결과와 TTA를 이용한 결과에 적용하여 레이블 스무딩 실시

원본 데이터를 이용하여 얻은 결과와 TTA를 이용하여 얻은 결과 복사하기

레이블 스무딩 적용하기
총 4개의 제출 파일
- submission: 테스트 데이터 원본으로 예측
- submission_tta: TTA 적용
- submission_test_ls: submission_test에 레이블 스무딩 적용
- submission_tta_ls: submission_tta에 레이블 스무딩 적용
♣ 추가 공부
Efficient-b7 대신 Efficient-b0 사용하기(아마 효율이 좀 더 떨어지겠지?)
(3, 450, 650) 크기의 input을 넣었을 때 model architecture 확인하기
결과적으로 b7이 b0보다 훨씬 점수가 높다.
♣ 참고 코드
- Efficientnet-b0 사용
https://www.kaggle.com/code/polljjaks/fork-of-plant-study-e3022c/edit
Fork of plant(study) e3022c
Explore and run machine learning code with Kaggle Notebooks | Using data from Plant Pathology 2020 - FGVC7
www.kaggle.com
'EfficientNet' 카테고리의 다른 글
| 흉부 엑스선 기반 폐렴 진단(pytorch 사용) (1) | 2023.11.18 |
|---|---|
| EfficientNet (1) | 2023.11.04 |