2023. 11. 18. 13:35ㆍEfficientNet
♣ 데이터 탐색
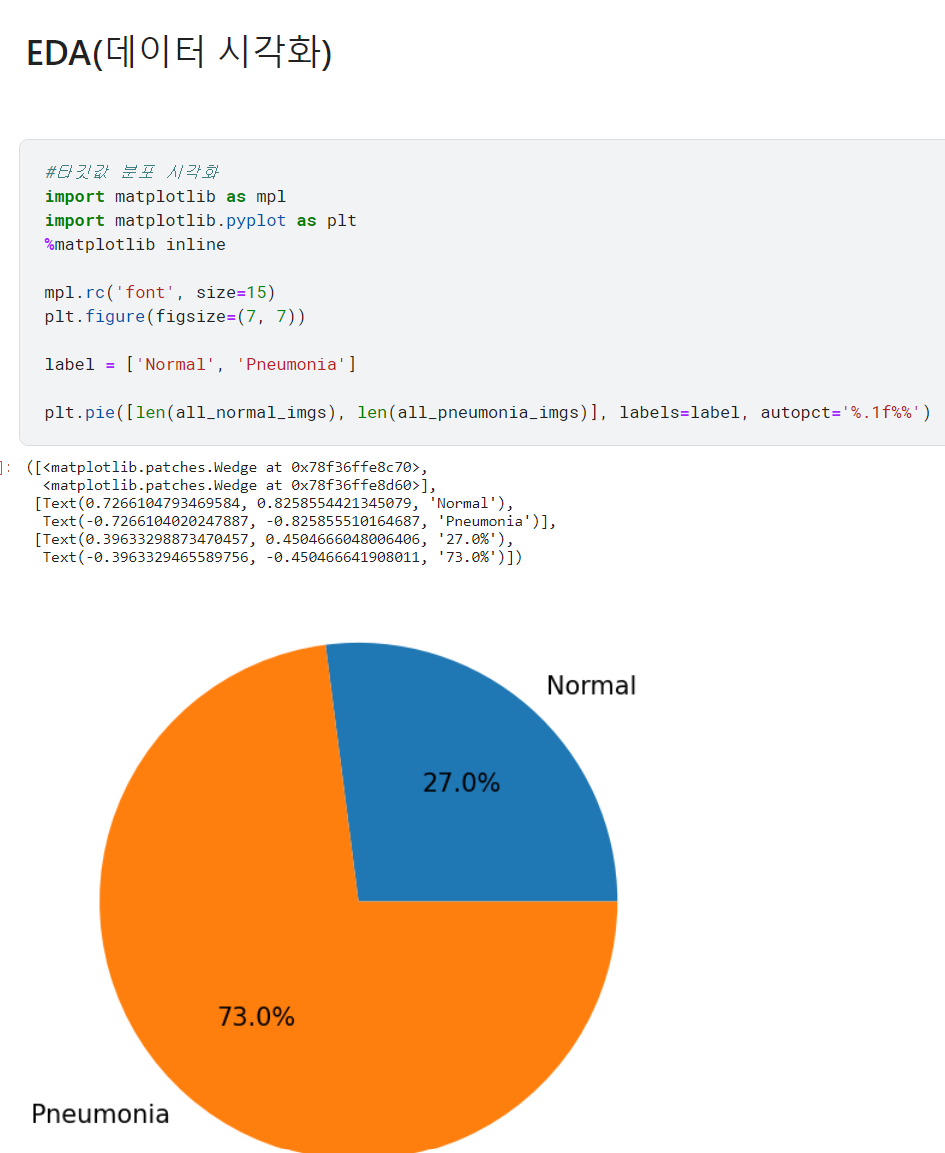
♣ 데이터 시각화
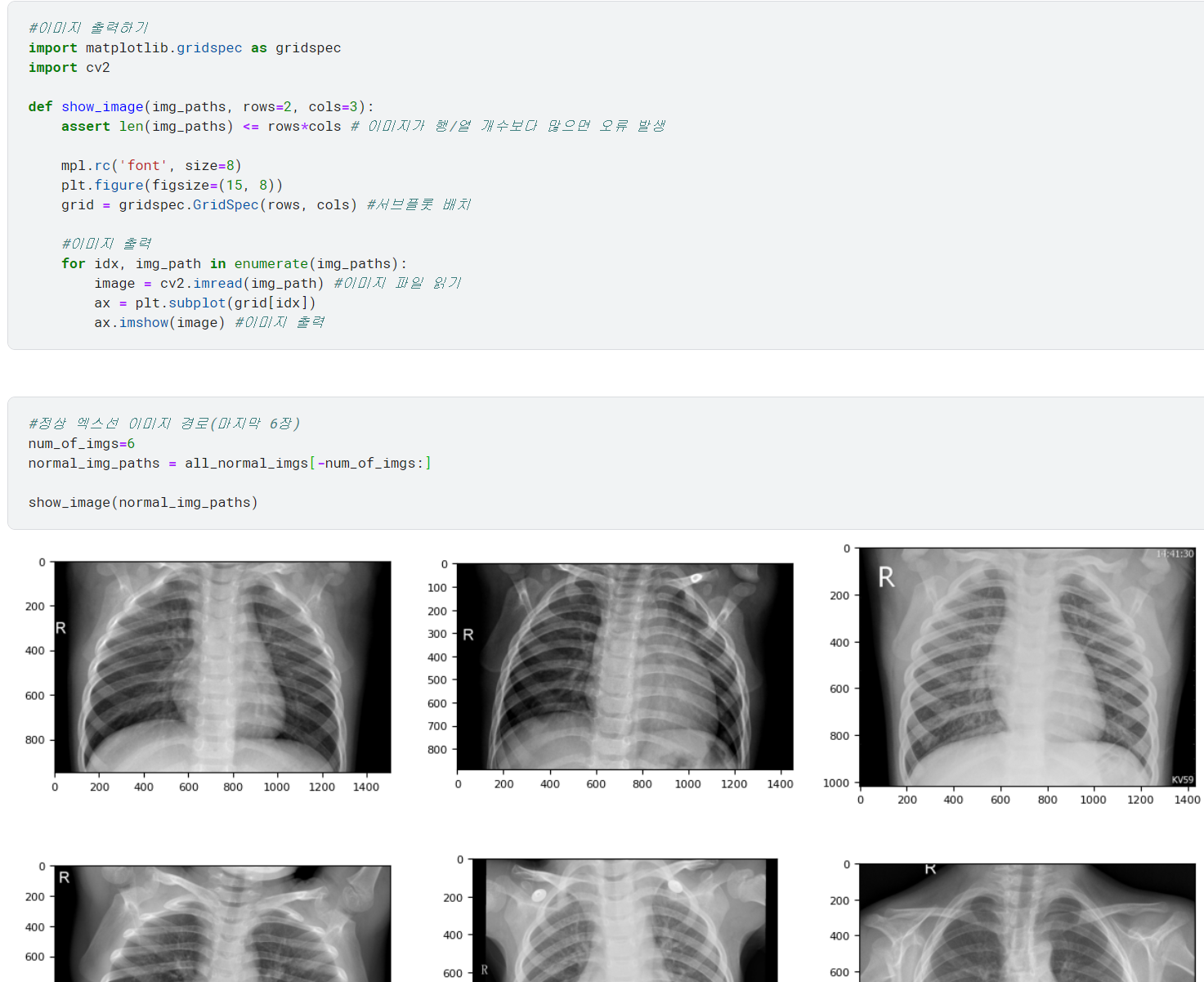

♣ 베이스라인 모델

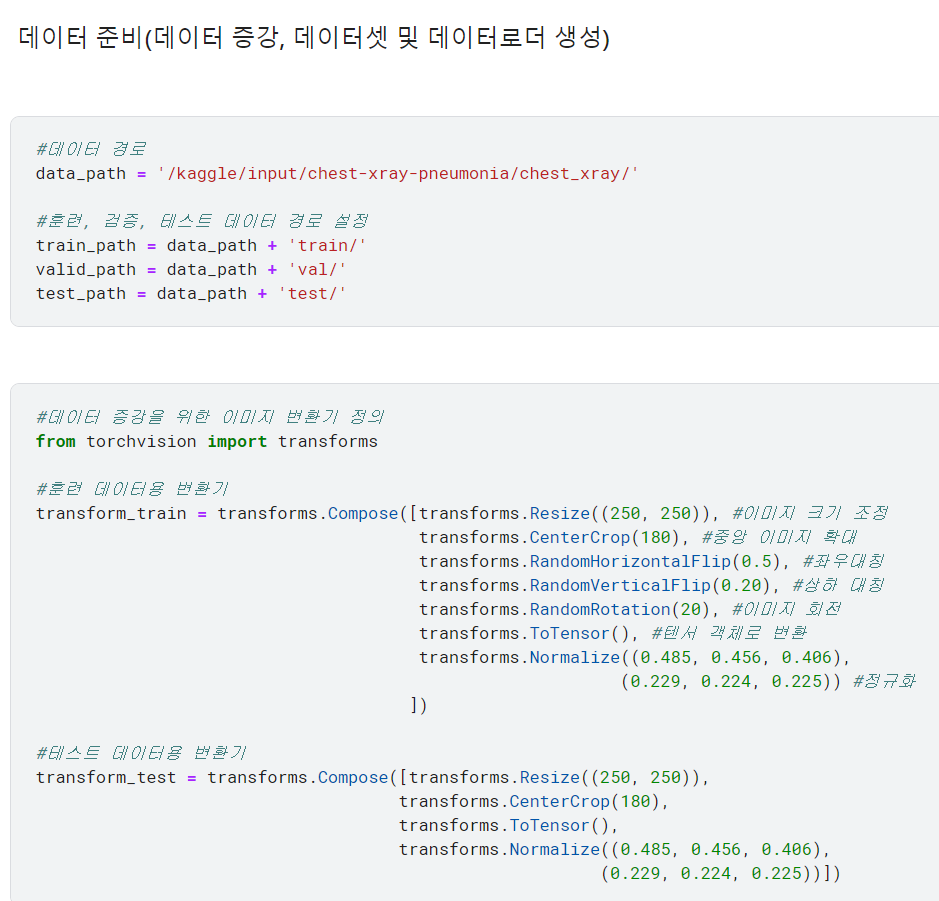
* 데이터셋 및 데이터 로더 생성
이번 장에서는 데이터셋 클래스를 정의하지 않음
-> 타깃값이 같은 이미지끼리 디렉토리로 구분되어 있으면 ImageFolder 클래스를 이용하여 바로 데이터셋을 만들 수 있음
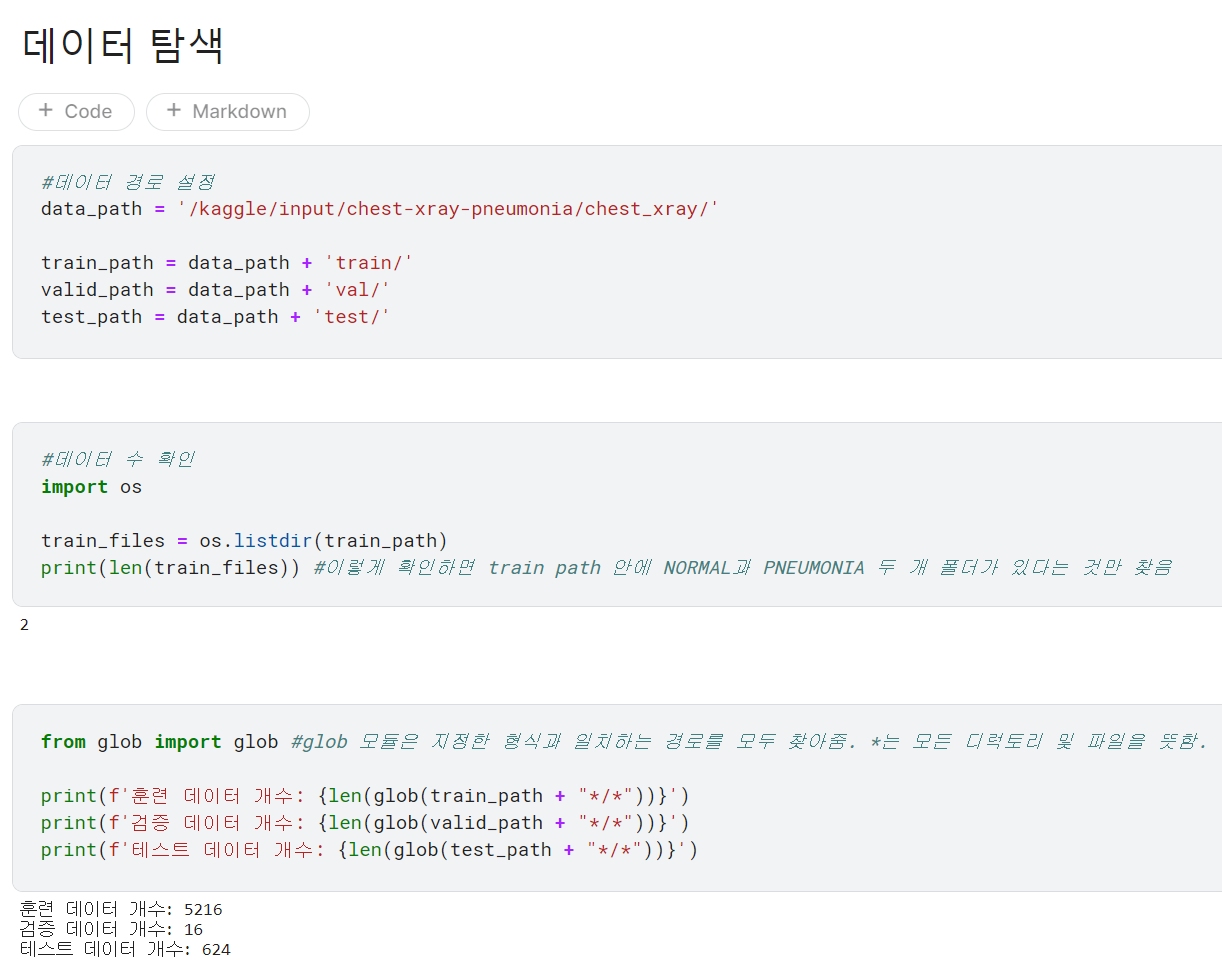
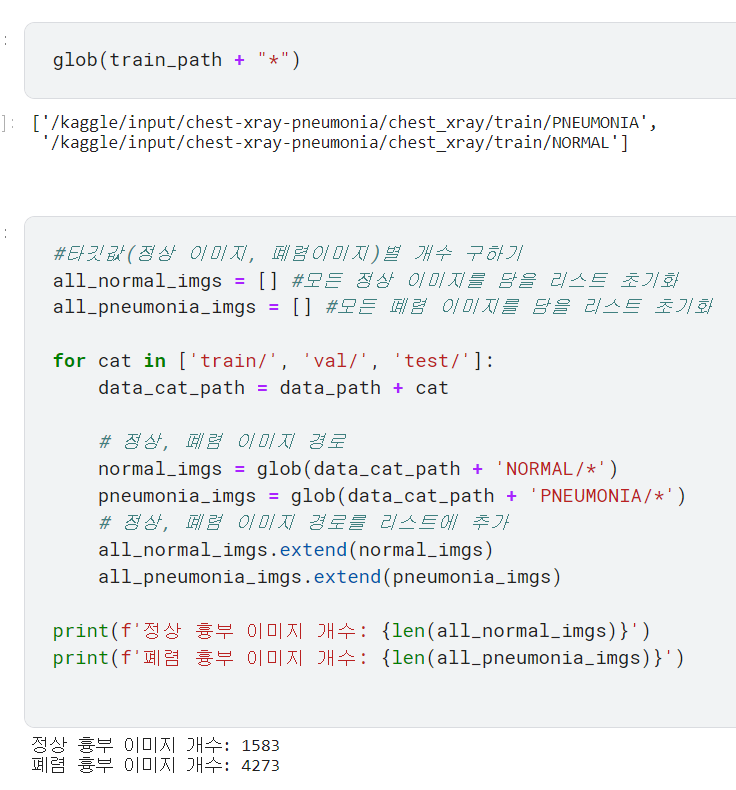
NORMAL 디렉토리에 담긴 이미지의 타깃값은 0, PNEUMONIA 디렉토리에 담긴 이미지의 타깃값은 1로 간주함.

ImageFolder 클래스는 root 파라미터에 전달한 경로에 있는 이미지들로 곧바로 데이터셋을 만들어줌.
데이터셋 클래스를 별도로 정의하지 않아도 되어서 편리함! 항상 사용할 수 이는 것은 아니고 타깃값이 같은 데이터들이 같은 디렉토리에 모여 있어야 사용할 수 있음.

♣ 모델 생성


numel( ) 은 텐서 객체가 갖는 구성요소의 총 개수를 구해줌
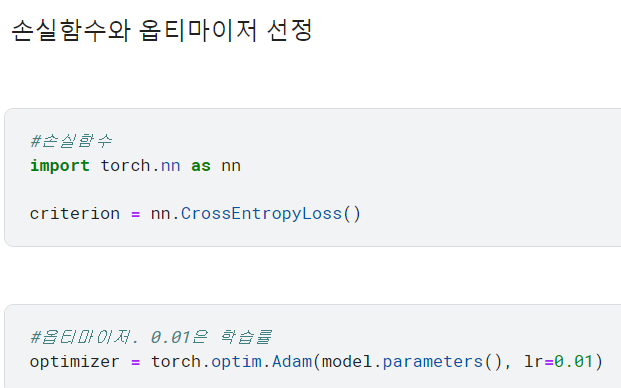
♣ 모델 훈련 및 성능 검증
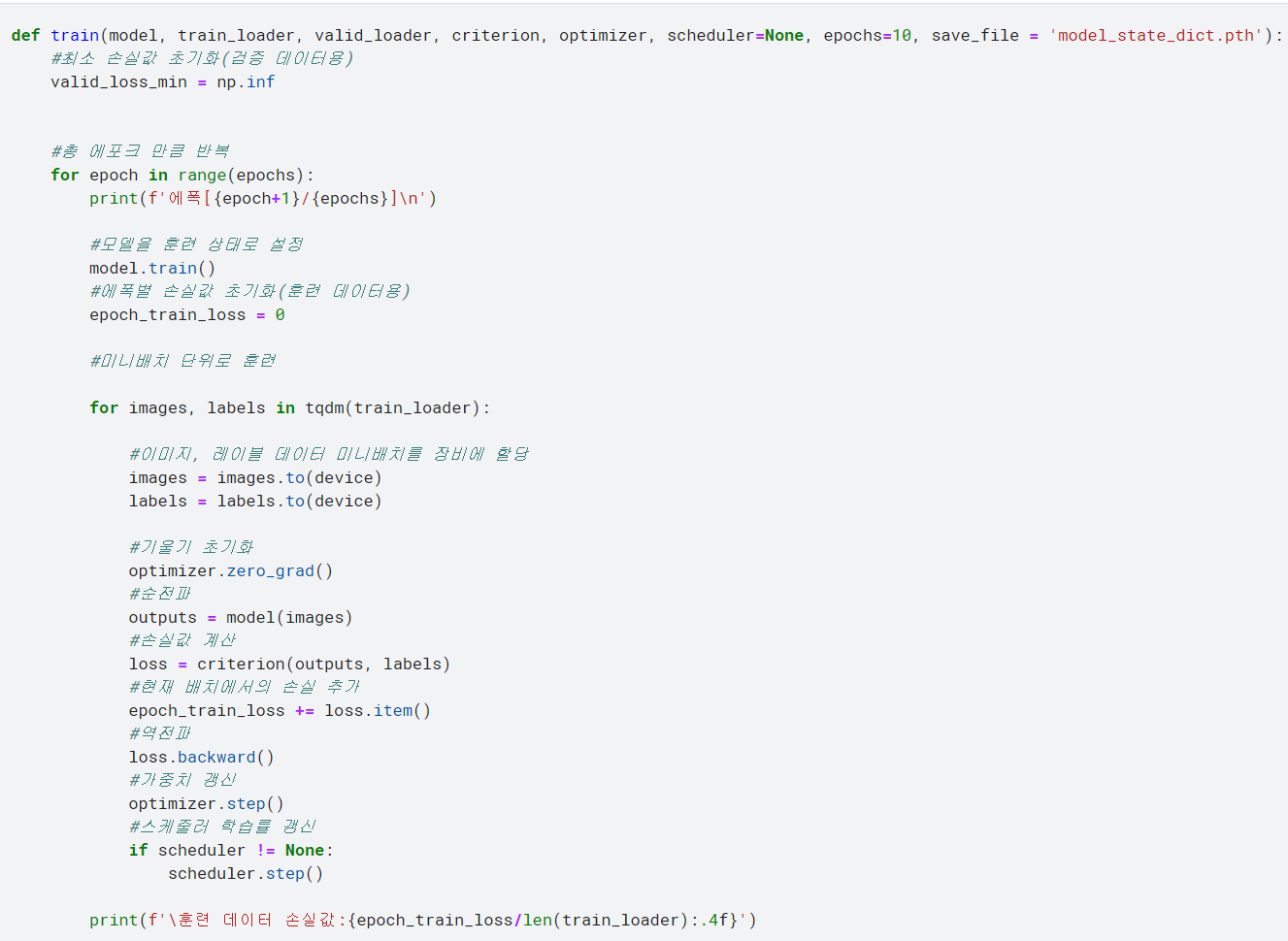
*훈련 함수 작성
epochs 수만큼 훈련과 검증을 반복하면서 최적 모델 가중치를 찾아서 마지막으로 반환하는 구조의 훈련 함수 작성.
데이터 로더를 이용하므로 훈련과 검증을 미니배치 단위로 수행함.
<훈련 함수의 훈련 부분>
<훈련 함수의 검증 부분>
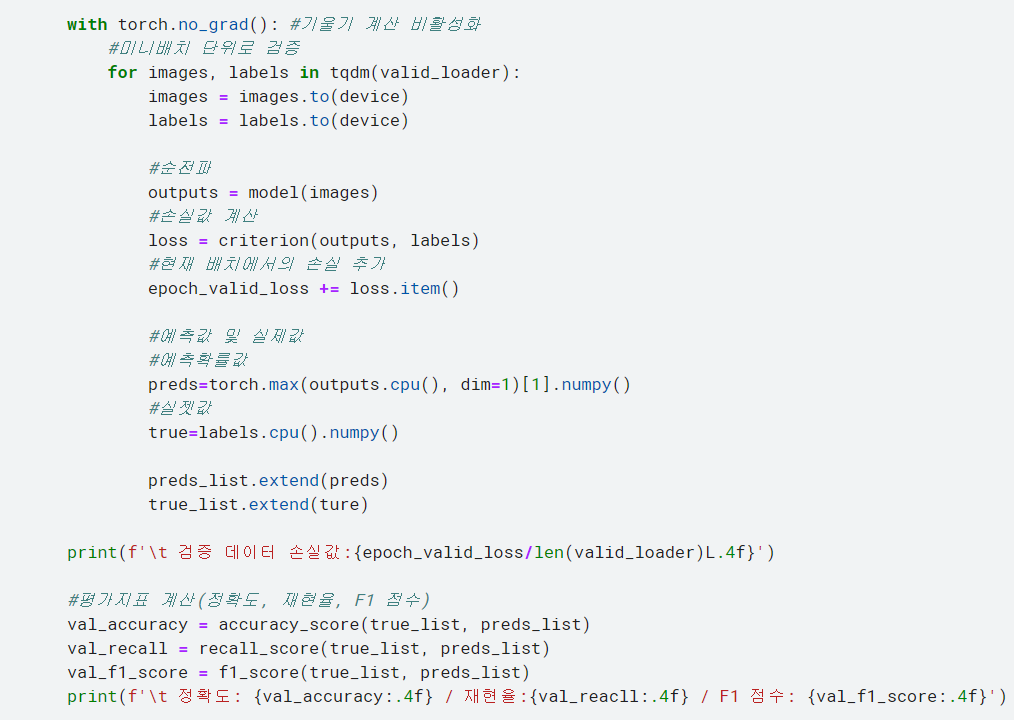
예측값 preds를 보면 torch.max는 최댓값을 구하는 메서드로, 예측 확률을 이산값으로 바꿔줌. 평가지표로 정확도, 재현율, F1 점수를 이용하려고 하므로 예측값을 확률이 아닌 이산값(0 또는 1)로 구해야 함.
torch.max 메서드 사용 예시
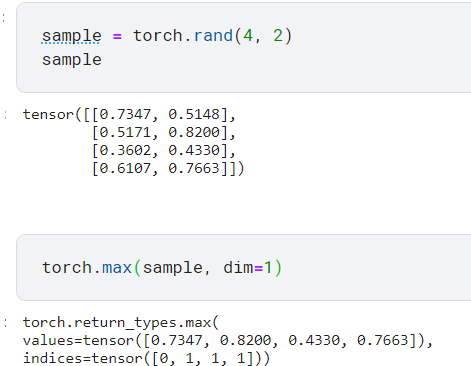
rand를 이용하여 랜덤값으로 4행 2열 tensor를 만듦. torch.max를 이용하여 각 행마다의 최댓값을 구함.
그리고 현재 2차원인 입력을 1차원으로 만듦. =>
values=tensor([0.7347, 0.8200, 0.4330, 0.7663])
하지만 예측값을 이산값으로 받아야 하므로 values가 아니라 indices가 필요함.

<최적 모델 가중치 찾기>

*훈련 함수 전체 코드
https://www.kaggle.com/code/polljjaks/chest-xray?scriptVersionId=151209911
chest xray
Explore and run machine learning code with Kaggle Notebooks | Using data from Chest X-Ray Images (Pneumonia)
www.kaggle.com



4번째 epoch에서 검증 데이터 손실값이 가장 작음. 이때의 모델 가중치가 최적 모델 가중치임.

테스트 데이터로 결과를 예측하는 predict 함수 정의

평가 결과

[성능 개선]
세 개의 모델을 앙상블해서 베이스라인보다 우수한 성능 내기
EfficientNet 중 B7이 가장 파라미터가 많아서 복잡하고, 따라서 복잡한 이미지를 더 잘 구분함.
하지만 항상 파라미터가 많은 게 좋은 것은 아님. 단순한 이미지를 구분할 때는 오히려 과대적합이 일어나서 평가 점수가 떨어질 수도 있음
이번에는 B1, B2, B3를 앙상블한 모델을 사용할 것


B7에 비하면 B1, 2, 3는 파라미터가 상대적으로 적은 편임(B7은 약 6천만 개의 파라미터를 가짐)

베이스라인에서 사용한 Adam에 가중치 감쇠를 추가한 AdamW 옵티마이저를 이용함

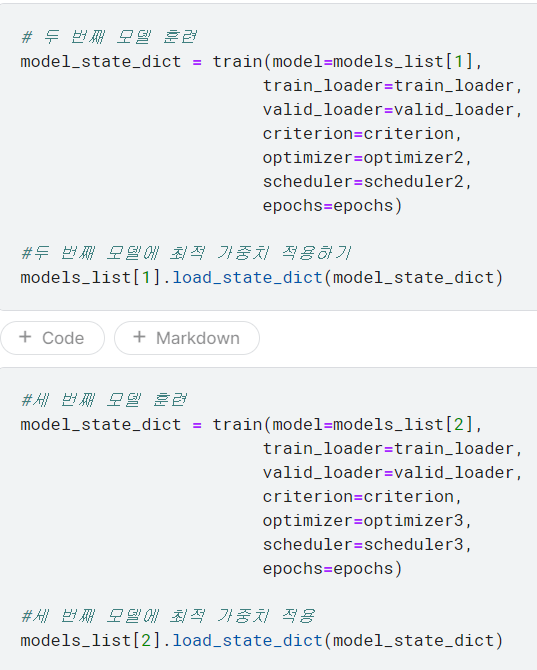
*모델 훈련 및 성능 검증: 위에서 정의했던 train 함수를 이용하여 세 개 모델을 순차적으로 훈련시키기

* 훈련을 마친 세 모델로 각각 예측하고, 이어서 세 모델의 예측 결과를 앙상블하기. 앙상블 예측값과 실젯값을 비교해서 최종 평가 점수 산출


* 앙상블의 원리: 세 예측값을 모두 합친 뒤 3으로 나누고, np.round 함수로 반올림함. 이렇게 하면 과반수가 예측한 값을 최종 예측값으로 결정하게 됨
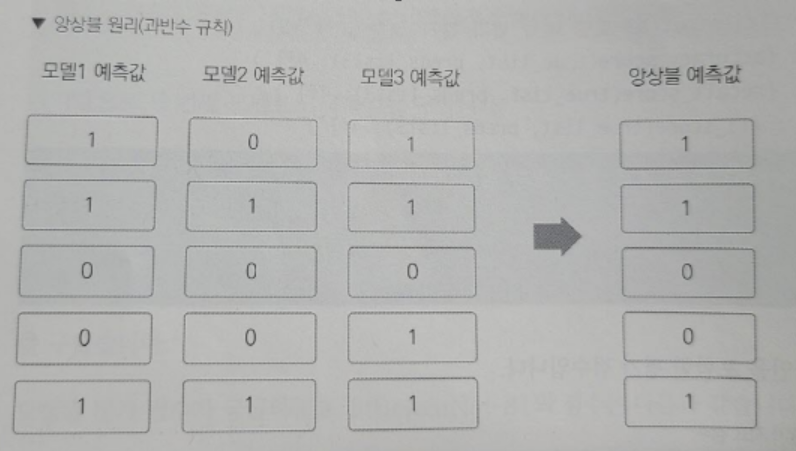
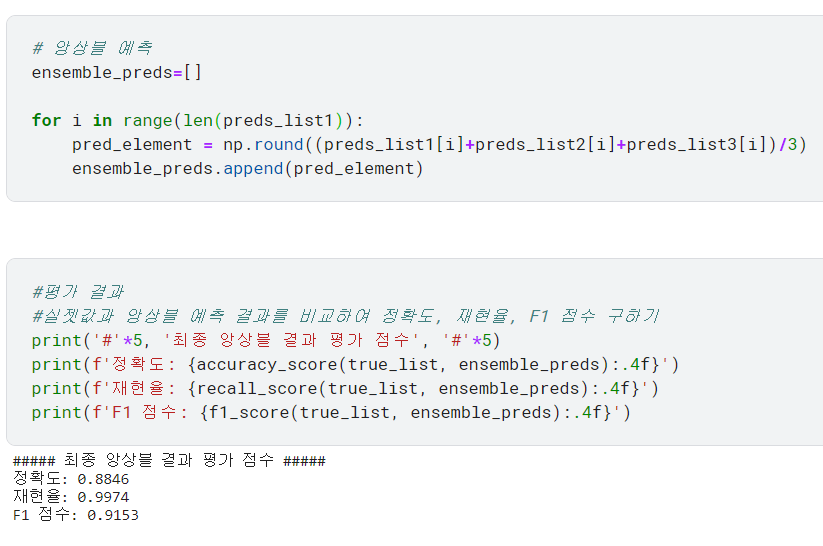
교재에서는 앙상블의 평가 점수가 훨씬 높았는데 내가 돌려보니 꼭 그렇지도 않다. 데이터는 같을텐데 왜 그런걸까?
♣ 전체 코드
https://www.kaggle.com/code/polljjaks/chest-xray/edit/run/151370869
chest xray
Explore and run machine learning code with Kaggle Notebooks | Using data from Chest X-Ray Images (Pneumonia)
www.kaggle.com
'EfficientNet' 카테고리의 다른 글
| EfficientNet (1) | 2023.11.04 |
|---|---|
| Plant Pathology 2020 (0) | 2023.11.03 |