2023. 7. 12. 16:40ㆍCNN
♣♣ 완전연결계층(Fully-connected multi-layered neural network: MLNN) vs CNN
기존에는 완전연결계층을 이용하여 이미지를 분류함
완전연결계층 = 한 층의 모든 뉴런이 다른 층의 모든 뉴런과 연결되어 있는 형태. 2차원의 흑백 이미지를 1차원 배열로 평탄화시킨 후 연산 작업을 진행함.
Affine계층: 한 층의 모든 뉴런이 다음 층의 모든 뉴런과 연결된 계층(완전연결된 계층)
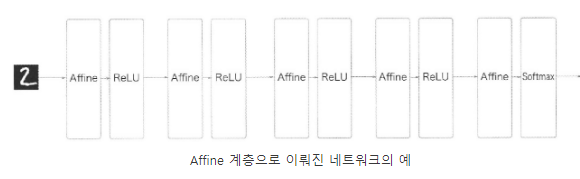
완전연결신경망에서는 Affine 계층 뒤에 ReLU나 sigmoid 계층이 이어짐. 마지막 계층에서는 Affine 계층에 이어 Softmax 계층에서 최종 결과를 출력함.
CNN 계층

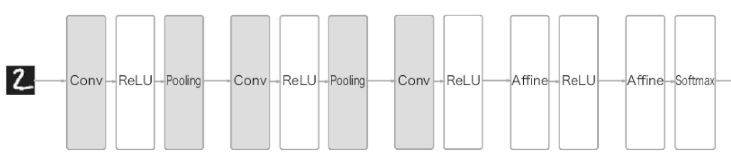
합성곱계층(Conv)과 풀링(Pooling 계층이 추가됨. Affine-ReLU 연결이 Conv-ReLU 로 바뀜. 다만 출력에 가까운 층에서는 Affine-ReLU 구성을 사용할 수 있음.
♣ 완전연결계층의 문제점
완전연결계층은 데이터의 형상을 무시함. 이미지는 3차원인데 입력할 땐 평평한 1차원 데이터로 바꿔야 함.
평탄화 작업(Flatten)을 통해 2차원 배열을 1차원 배열로 펼치면 이미지 데이터의 형상이 훼손됨
이 문제를 해결하기 위해 CNN이 제시됨. 합성곱은 형상을 유지함. 이미지를 3차원 데이터로 입력 받고, 다음 계층에도 3차원 데이터로 전달함.
♣ 13.1 합성곱의 마법
특징 공학(feature engineering)
- 이미지의 맥락에서 '특징'은 시각적으로 구별되는 속성
- 각 이미지에서 선의 위치 정보를 추출하여 특징으로 사용할 수 있음
- 이미지에서 선을 찾기 위해 합성곱을 사용함
- 합성곱은 커널(Filter라고도 부름. 작은 행렬)을 적용함.
- 커널이 합성곱 계층에서의 가중치에 해당함.
- 커널을 적용하여 유사한 이미지의 영역을 강조하는 특성 맵(feature map)을 출력하여 다음 계층으로 전달
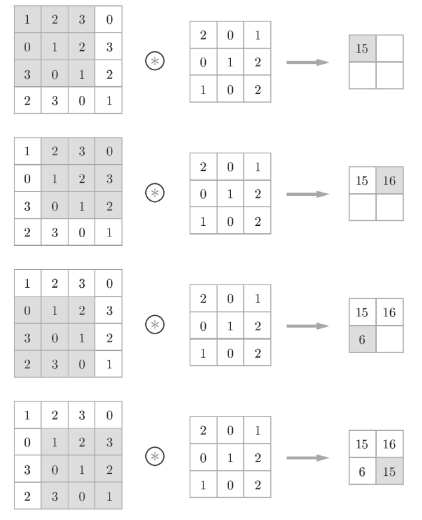
- 합성곱 연산은 이미지에서 선택된 블록의 각 요소와 커널의 각 요소를 곱해서 더
- 커널의 각 가중치 집합은 다른 종류의 결과를 생성함.

- df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')
DataFrame df의 스타일에 더 나은 시각화를 제공함.
font-size':'6pt': DataFrame의 글꼴 크기를 6pt로 설정. 큰 DataFrame의 경우 텍스트를 더 작게 표시하여 시각화를 향상시킴
.background_gradient('Greys'): DataFrame에 배경 그라디언트를 적용함. DataFrame셀의 값들이 회색조 색상으로 변환됨. 어두운 색은 낮은값, 밝은 색은 높은 값에 해당함.

- 해당 row와 col에 해당하는 픽셀이 블록의 가운데 가도록 배열
♣ 13.1.1 합성곱 커널의 매핑
여기서는 합성곱 함수를 만들지 않고 파이토치가 제공하는 구현체를 활용. 파이썬에서 구현할 때보다 훨씬 더 빠르게 연산을 처리함.
커널(필터)로 입력 데이터의 특징맵(Feature map)을 추출할 때 중요하게 작용하는 요소: 패딩, 스트라이드
커널의 크기가 커지면 특징맵의 크기가 작아짐
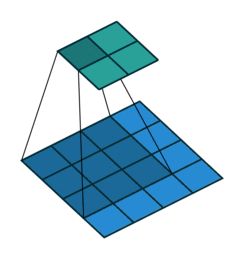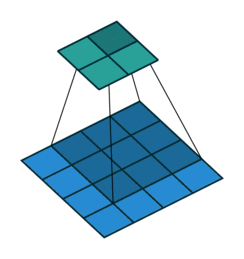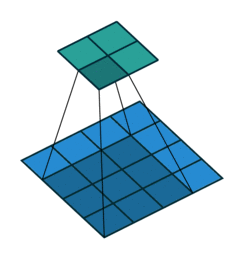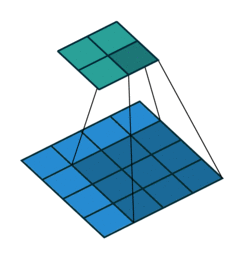
- 위의 이미지에서 커널이 3*3이면 특성맵의 크기는 2*2
- 위의 이미지에서 커널이 2*2이면 특성맵의 크기는 3*3
특징맵의 크기가 작아질수록 모서리에 있는 이미지 데이터의 정보가 사라지게 됨. 이를 조절해주는 값 = 패딩
패딩: 출력 데이터의 공간적 크기를 조절하기 위해 사용하는 파라미터
입력 데이터의 크기와 출력 데이터의 크기를 같게 하는 zero-padding 또는 same-padding을 주로 사용함
적절한 패딩을 사용하면 활성맵의 크기를 원본 이미지와 같게 만들 수 있음.
스트라이드: 입력 데이터에 커널을 적용할 때 이동할 칸을 조절하는 파라미터. 입력 데이터가 너무 큰 경우, 연산량을 줄이기 위한 목적으로 사용
입력 데이터와 커널을 연산할 때 기본적으로 한 칸씩 이동하면서 연산함. 이때 스트라이드 값을 1이라고 함
하지만 스트라이드값을 크게 하기보다는 대부분 스트라이드 값을 1로 하고 나중에 Pooling 계층을 통해 이미지의 크기를 줄이는 sub-sampling 과정을 거침.
스트라이드값을 크게 할 경우 패딩 값을 조절하는 것과 마찬가지로 데이터의 특징 일부를 잃어버릴 수 있기 때문임
2픽셀만큼 이동할 경우 스트라이드2 합성곱이라고 함. 스트라이드2 합성곱은 출력의 크기를 줄이는 데 유용함.
스트라이드1 합성곱은 크기를 그대로 유지한 채 새로운 계층을 추가하는 데 유용함.
실제로 3*3 크기의 커널, 1만큼의 패딩, 1만큼의 스트라이드 조합을 가장 보편적으로 사용함.
♣ 13.1.2 파이토치의 합성곱
직접 합성곱 함수를 만들지 않고 파이토치가 제공하는 구현체 활용. 직접 구현할 때보다 빠르게 연산을 처리함
F.conv2d로 접근하여 사용
파이토치는 동시에 여러 이미지에 합성곱을 적용함. 즉 한 번에 일괄적으로 여러 이미지를 다룰 수 있음
파이토치가 여러 커널을 동시에 적용함.

- input: 입력 텐서의 모양(minibatch, in_channels, iH, iW) => 랭크가 4인 텐서. 4가지 정보 담김
*iH, iW = 이미지의 높이와 너비(예시 28, 28)
*in_channels = 이미지의 단일 기본 색상. 일반적인 풀컬러 이미지는 세 개의 채널(빨, 초, 파)로 구성
- weight: 커널의 모양(out_channels, in_channels, kH, kW) => 랭크가 4인 텐서. 4가지 정보 담김
*kH, kW = 커널의 높이와 너비(3, 3)

xb, yb는 validation set으로부터 뽑은 data batch임. xb는 input batch를, yb는 output batch를 의미함.
즉 yb는 input data인 xb에 해당하는 target값이나 label임.
xb.shape를 보면 torch.Size([64, 1, 28, 28])로, 각각의 요소들이 batch_size, channels, height, width를 나타냄. => 위에서 이야기한 input의 형태
batch size는 64이고(즉 이미지가 64장 들어있음) 흑백이기 때문에 channel은 1임.
각각의 이미지 크기는 28*28 픽셀임
F.conv2d에 전달된 커널은 랭크4인 텐서여야 함 => [features_out, channels_in, rows, columns]
위의 edge_kernels의 shape은 3개 랭크 가짐 torch.Size([4, 3, 3])
edge_kernels는 weight에 해당하므로 (out_channels, in_channels, kH, kW)로 랭크4를 가져야 함
커널의 입력 채널 수(이미지의 단일 기본 색상, 여기서는 이미지가 흑백이라서 1임) 1을 삽입해야 함

완성한 edge_kernels를 conv2d에 전달하기

batch_features.shape은 (batch_size, num_kernels, output_height, output_width)를 나타냄.
- 미니배치에 이미지 64장 들어있음. input의 batch_size와 같음.
- num_kernels: edge_kernels에서 커널이 4개임
- 각 이미지 크기 26*26
input 이미지의 크기가 28*28이었는데 output의 크기는 왜 26*26이 되었을까?
3*3 커널로 featuremap을 만들다보니 2개 픽셀이 탈락한 것.
show_image(batch_features)는 [0, 0], [0, 1], [0, 2], [0, 3], [1, 0].....[63, 3]까지 간다. 즉 4개 채널에서 64개의 이미지를 모두 합성곱 계산하였고 이미지들을 한 층씩 가져오는 것으로 보인다.
3차원 합성곱 연산은 데이터와 필터를 직육면체 블록이라고 생각하면 이해가 쉬움
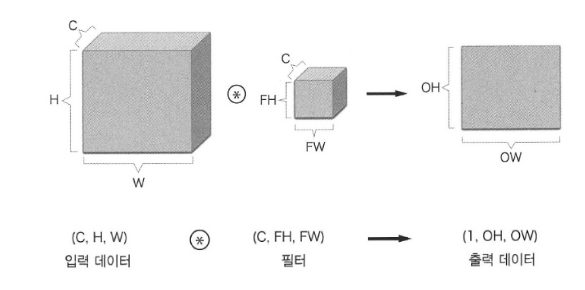
다수의 채널이 있을 때는 kernel도 여러 개 사용

FN: 출력채널 수
C: 입력채널 수
FH: 높이
FW: 너비
편향까지 적용하면?
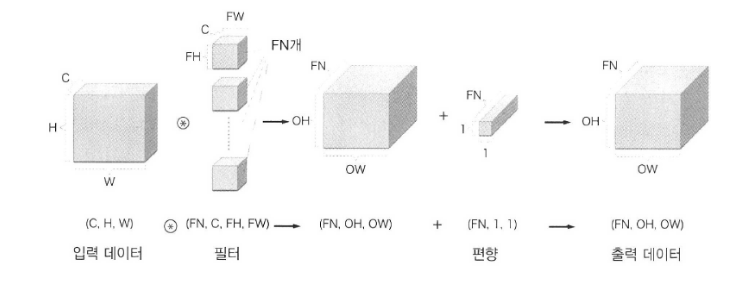
♣ 13.2 첫 번째 합성곱 신경망
합성곱 계층을 사용하면 합성곱 신경망(CNN)을 만들 수 있음
♣ 13.2.1 CNN 만들기
기본 신경망 구성
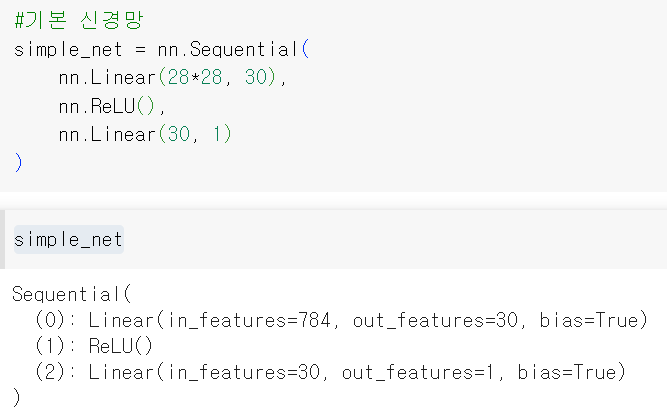
0: 첫 번째 레이어. input의 size가 784, output의 size는 30. output size는 숨겨진 layer 안의 뉴런의 수를 의미함. 각각의 뉴런이 output value를 생산함. (지금까지 합성곱에서 이야기하던 output channel이나 feature map의 크기와는 다름)
1: 두 번째 레이어. ReLU 활성함수를 이용하여 비선형성을 높임. 음수값을 모두 0으로 대체함.
2: 세 번째 레이어. 이전 layer로부터 이어지기 때문에 input의 size가 30, output의 size는 1이 됨. 즉 final layer에서의 뉴런이 1인 것.
즉 세 개 layer로 구성된 선형적 신경망임
합성곱 신경망 구성(선형 대신 합성곱 계층을 사용한 구조)

0: 첫 번째 합성곱 레이어. in_channel이 1(흑백 이미지겠지), size 3*3 필터 30개 사용. padding은 1픽셀씩. stride=(1, 1)은 한 번 이동할 때 수평, 수직으로 전부 1픽셀씩 갔다는 뜻임
1: 두 번째 레이어. 활성함수 ReLU가 신경망의 비선형성을 높임
2: 세 번째 레이어. 앞선 레이어의 30개 채널로부터 output을 받음. 3*3 크기의 kernel을 1개 사용. output channel도 1이라서 하나의 output이 생김.
* 또는 앞의 숫자는 input의 채널 수, 뒤의 숫자는 output의 채널 수를 의미하기도 함. 보통은 위와 같은 구조에 pooling 같은 기술이나 추가적인 레이어를 많이 사용함.
*입력의 크기가 28x28임을 지정하지 않아도 됨. 선형 계층에서는 모든 픽셀에 대응하는 가중치로 구성된 가중치 행렬이 필요해서 픽셀 개수를 알아야 했음. 하지만 합성곱에서는 각 픽셀에 가중치가 자동으로 적용되므로 입력의 크기를 몰라도 됨.

padding이 1이어서 28에서 양쪽으로 2를 더해서 픽셀 크기가 30이 됨. 30 - 3(커널의 길이) + 1= 28 이므로 합성곱을 지났음에도 불구하고 xb의 모양이 [64, 1, 28, 28]
함수를 이용하여 이미지를 이진분류할 수 있는 CNN 만들기

ni = number of input channels
nf = number of output channels(number of filters)
act = ReLU 활성함수를 적용할지 안 할지를 결정.
act = True 이면 합성곱레이어(res)와 ReLU 함수의 순차적인 조합이 return됨.
반대로 act=False이면 ReLU함수의 적용 없이 합성곱만 return 됨.

- conv(1, 4) => input channel이 1이고 output channel이 4인 합성곱 레이어. stride가 2이기 때문에 input의 공간적 차원을 1/2로 줄임.
- conv(16, 32) => 공간적 차원이 1X1까지 줄어듦.
- conv(32, 2, act=False) => 32개 channle을 2개 channel까지 줄임. 이 합성곱 다음에는 활성 함수를 적용하지 않음.
마지막 레이어인 conv(32, 2, act=False)에서 input의 채널은 32인데 output의 채널은 2임. 즉 최종적으로 2차원의 벡터값을 output으로 내보내는 것. 따라서 torch.Size는 배치 크기 64와 2차원의 벡터값을 의미함. 숫자가 3인지 7인지 구별하는 binary classification 이기 때문에 output channel이2임.
또한 input의 크기는 계속 줄어들지만 channel의 수는 계속 늘어남. feature map의 수가 4배 줄어드는데, 한 번에 계층의 처리 용량을 너무 많이 줄이고 싶지 않아서 특징(channel)의 개수는 늘려나간 것.
커널와 output channels의 관계
합성곱 신경망 (CNN)의 문맥에서, 레이어의 커널 수는 해당 레이어에서 사용되는 필터 또는 특징 탐지기의 수를 의미함
각각의 커널은 입력 데이터에서 특정한 패턴이나 특징을 감지하는 역할을 담당함.
레이어의 커널 수는 일반적으로 해당 레이어의 출력 채널 수와 동일함. CNN에서 각각의 커널은 입력 데이터와 합성곱하여 개별적인 출력 채널을 생성함. 각 채널은 해당 커널이 포착한 입력 데이터의 서로 다른 특징 또는 측면을 나타냄.
예를 들어, 3개의 색상 채널 (RGB)을 가진 입력 이미지가 있다고 가정하면 64개의 커널을 가진 합성곱 레이어는 64개의 출력 채널을 생성함. 각각의 커널은 입력 이미지와 독립적으로 합성곱을 수행하며, 입력으로부터 다른 특징을 나타내는 64개의 특징 맵 (출력 채널)을 생성함. 즉 feature map의 개수도 output channels의 수와 같음.
여러 개의 커널과 출력 채널을 가지는 것은 CNN이 입력 데이터로부터 다양하고 계층적인 특징을 학습하고 추출할 수 있도록 해주며, 더 복잡한 패턴을 포착하고 표현 능력을 향상시킴
64개의 커널로부터 얻은 64개의 특징 맵은 각각 독립적으로 풀링 연산을 거치게 됨. 풀링 연산은 각 특징 맵의 공간적인 차원을 개별적으로 줄여주며, 이를 통해 64개의 풀링된 특징 맵이 생성됨.. 각 풀링된 특징 맵은 해당하는 원본 특징 맵의 다운샘플링된 요약 버전
Learner 모델 만들기(CNN을 이용하여 모델 만들기)


input의 크기는 64*1*28*28. 각 축이 배치 크기(batch), 채널 수(channel), 높이(height), 너비(width)를 의미함
최종 Conv2d layer는 64*2*1*1 을 출력함. 이 중 필요 없는 1*1 축은 Flatten이 제거함.
모델을 이용하여 학습하기
이 신경망은 앞서 구축한 신경망보다 구조가 깊으니 더 많은 학습률과 더 많은 에포크 수를 설정.

♣ 13.2.2 합성곱 연산 이해하기
CNN 모델의 첫 번째 convolutional layer 살피기
입력은 64x1x28x28임.

첫 번째 convolutional layer의 가중치 살피기


torch.Size([4, 1, 3, 3]) 이므로 4*1*3*3 = 36 => 4는 output channel(kernel)의 수. 1은 input channel 임. 3x3은 kernel의 크기를 의미함. 따라서 torch.Size([4, 1, 3, 3])은 각 커널이 9개의 가중치를 가지고 있는데, 커널이 4개니까 4x3x3 개의 가중치를 가지고 있는 것이 됨. input 채널이 여러 개가 되면 그것도 곱해야 함. input image가 grayscale이면 input channel이 1이지만 만약 RGB image라면 input channel이 3이 됨. 즉 이미지가 어떤 정보를 가지느냐에 따라 input channel의 수가 달라짐. (다시 말해, 각 RGB 이미지는 세 개의 별개 입력 채널(R, G, B)로 분할되며, 각 채널은 해당하는 필터 세트와 개별적으로 처리됨. 이 프로세스를 통해 네트워크는 각 색상 채널마다 특정한 기능을 캡처할 수 있음)
하지만 위의 summary를 보면 첫 번째 계층에 파라미터가 40개 존재한다고 함.
첫 번째 convolutional layer의 편향(bias) 확인. 채널마다 하나의 편향이 있음.

가중치 36 + 편향 4 = 40
♣ 13.2.3 수용 영역
수용영역(receptive fields): 계층 계산에 관련된 이미지 영역. 필터를 통해서 보는 영역
합성곱 계층의 단점: 한정된 크기의 필터로만 데이터를 읽어옴.
수용 영역을 늘리면 문제를 해결할 수 있음.
윈도우를 통해 생성된 feature map 여러 개를 동시에 계산하기
♣ Pooling
특징을 뽑아내는 과정
feature map들의 feature map을 만드는 작업. 가로, 세로 방향의 공간을 줄이는 연산
Pooling 레이어는 컨볼루션 레이어의 출력 데이터를 입력으로 받아서 출력 데이터(Activation Map)의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용함(convolution layer의 계산 결과인 feature maps를 pooling함)
Pooling의 목적
- input의 크기 줄이기: 텐서의 크기를 줄이는 역할
- overfitting 조절: input 사이즈가 줄어들면서 불필요한 parameter의 수를 줄임. 훈련데이터에만 높은 성능을 보이는 과적합을 방지할 수 있음
- 이미지의 특징을 더 잘 뽑아냄
Pooling 이전 단계
- convolution layer에서 커널 이용하여 feature map 계산하기
- 그 계산결과를 활성함수를 이용해서 비선형성 부여하기
Pooling의 종류
- Max pooling: 정해진 크기 안에서 최대값을 추출
- Min pooling: 최소값을 추출
- Mean pooling: 정해진 크기 안의 값들의 평균 추출
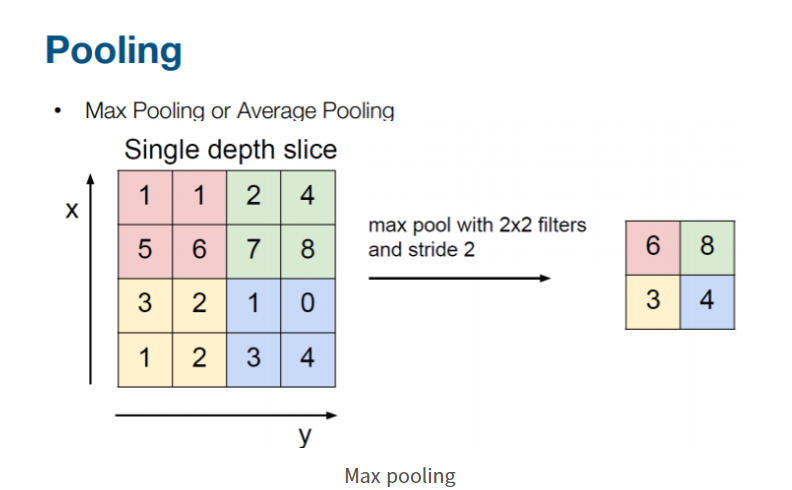
Pooling 레이어는 Convolution 레이어와 비교하여 다음과 같은 특징을 가짐
- 학습대상 파라미터가 없음
- Pooling 레이어를 통과하면 행렬의 크기 감소
- Pooling 레이어를 통해서 채널 수 변경 없음
♣ 13.3 컬러이미지 다루기
- 합성곱층에 입력: RGB 이미지를 합성곱층에 입력할 때, 이미지의 세 가지 색상 채널(R, G, B)이 별개의 입력 채널로 처리됨.
- 커널: 합성곱층에 세 개의 커널이 있고 각 커널의 크기가 3x3이라면, 입력 이미지 위를 움직이는 세 개의 필터가 있다는 것을 의미함.
- 커널에 대한 가중치: 각 커널마다 실제로는 가중치가 세 개의 세트로 구성됩니다. 각 가중치 세트는 하나의 입력 채널(R, G, B)에 해당함. 가중치 세트는 각각의 입력 채널에 커널을 적용하기 위해 사용됨.
- 합성곱 연산: 각 커널은 각각의 입력 채널과 별도로 합성곱됨. 이를 통해 입력 이미지에 세 개의 커널을 각각 적용한 결과, 세 개의 별개 특성 맵(R, G, B 채널 각각)이 생성됨
- 특성 맵 결합: 이러한 별개의 특성 맵(R, G, B)은 원소별로 함께 결합됨. 이 결합은 세 특성 맵에서 대응하는 원소를 합산하여 이루어지며, 서로 다른 채널에서 나온 정보를 효과적으로 결합함.
- 출력 채널 별 최종 특성 맵: 이 시점에서 여전히 여러 개의 출력 채널(커널 수와 동일한 수, 이 경우 세 개)이 남아 있음. 각 출력 채널은 이제 R, G, B 채널에서 나온 특성 맵을 결합하여 만든 단일 특성 맵을 가지게 됨.
- 출력 채널 결합: 총 세 개의 출력 채널(필터)이 있다면, 각 채널에서 나온 개별 특성 맵이 함께 결합되어 최종 출력을 형성함. 이것이 합성곱층에서 생성된 최종 특성 맵임.
따라서, 예, 이 합성곱층의 가중치 텐서는 실제로 네 개의 차원을 가질 것임: 출력 채널 x 입력 채널 x 커널 크기 x 커널 크기. 이렇게 하여 합성곱층은 다양한 입력 채널에서 특징을 추출하고 결합하여 최종적으로 의미 있는 특성을 출력하는 것이 가능해짐.
♣ 13.4 학습의 안정성 개선하기
숫자 10개를 모두 인식하는 모델 만들기
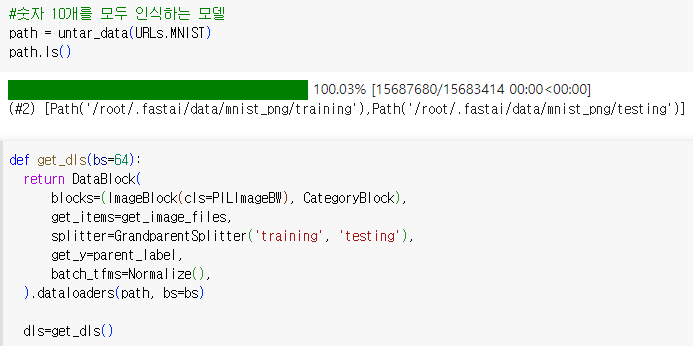
-splitter는 dataset을 어떻게 자를지 결정하는 parameter. 여기서는 training, testing 데이터셋으로 나뉠 것
실제 모양 파악

♣13.4.1 안정성 개선 방법1: 보다 큰 커널 사용하기
신경망 모델 생성. kernel은 5*5 픽셀로 사용. 첫 번째 layer에서 3*3 커널보다 더 큰 커널을 사용함

- 5*5 kernel 사용
- 10개 숫자로 분류하는 것이기 때문에 마지막 layer의 output channel이 10임
3*3 kernel VS 5*5 kernel
- 수용 영역: 5x5와 같은 큰 커널은 3x3 커널에 비해 더 큰 수용 영역을 가지고 있음. 따라서 더 많은 맥락 정보를 포착할 수 있으며 입력 데이터에서 더 큰 패턴이나 구조를 감지할 수 있음.
- 특징 추출: 큰 커널은 픽셀 사이의 공간적인 관계를 더 많이 포착할 수 있으므로 더 복잡한 특징 추출이 가능함. 입력에서 정교하거나 대규모의 특징을 감지해야 하는 작업에 유용할 수 있음.
- 매개 변수 효율성: 경우에 따라 큰 커널을 사용하는 것이 매개 변수 효율적일 수 있음. 5x5 커널 한 개는 여러 개의 3x3 커널을 쌓는 것보다 더 적은 매개 변수를 필요로 함. 이는 모델의 크기를 줄이고 계산 속도를 높일 수 있음
*하지만 큰 커널 크기는 네트워크의 깊이가 깊어질수록 계산 복잡성과 메모리 요구 사항을 증가시킬 수 있음. 또한, 다른 커널 크기의 효과는 특정 데이터셋과 작업에 따라 다를 수 있음
신경망 모델 학습
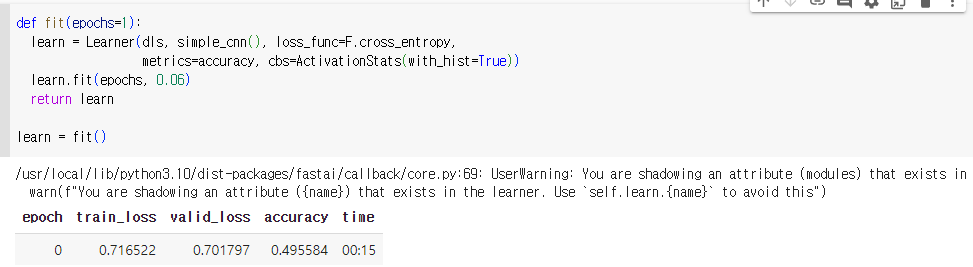
- 결과를 보면 accuracy가 꽤 낮음
- ActivationStats는 학습 기간 중의 활성에 대한 그래프를 그리는 편리한 기능 제공
activation_stats.plot_layer_stats 메서드를 사용하여 idx 번째 계층의 활성에 대한 평균과 표준편차 그래프, 0에 가까운 활성의 비율 그래프 그리기

- 일반적으로 학습 중 모델 계층들의 활성은 일관되거나, 최소한 평균과 표준 편차가 매끄러워야 함
- 활성값이 0에 가깞다면 문제가 있음. 0을 곱하면 0이 되므로 아무런 계산도 이루어지지 않기 때문임. 또한 한 계층에서 0이 발생하면 그 다음 계층에서는 일반적으로 더 많은 0이 발생함.
- 즉 신경망이 깊어질수록 학습이 잘 되지 않으며 문제가 악화됨.
따라서 안정적으로 학습하기 위해서는 아래와 같은 것들이 필요함
♣13.4.2 안정성 개선 방법2: 배치 크기 늘리기
배치 크기를 늘리는 것은 학습을 더 안정적으로 만드는 한 가지 방법
더 큰 배치는 한 번에 계산해야 하는 데이터가 더 많다는 뜻이므로 더 정확한 그레이디언트를 찾을 수 있음
단점은 배치 크기가 클수록 에포크당 배치 수가 적으므로 모델이 가중치를 갱신할 기회가 줄어듦

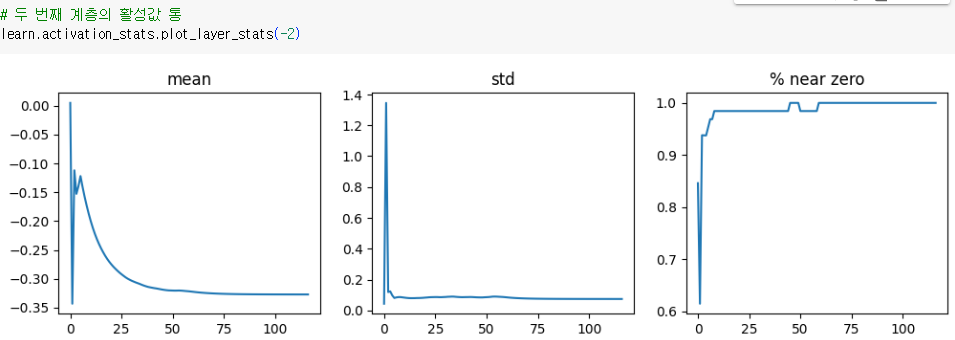
- 여전히 활성값이 0에 가까움. 학습의 안정성을 개선하는 다른 방법 필요
♣13.4.3 원 사이클 학습법
높은 학습률로 학습을 시작하면 갑자기 학습이 범위를 벗어날 수 있음. 또한 학습이 끝날 때까지 높은 학습률을 유지하면 손실의 최소 지점을 놓칠 수 있음. 하지만 그 외의 기간에는 높은 학습률을 주어서 학습이 빠르게 이루어지게 할 수 있음.
=> 학습률을 낮게 시작해서 높게 끌어올린 다음, 다시 낮은 값으로 바꾸기
- 웜업(warm up): 학습률을 최솟값에서 최댓값으로 끌어올리는 단계
- 어닐링(냉각, annealing): 다시 학습률을 최솟값으로 떨어뜨리는 단계
- 원 사이클 학습법(cycle training): 웜업과 어닐링을 결합한 접근법
작은 학습률로 시작하여 손실이 크게 벗어나지 않도록 한 다음, 점진적으로 학습률을 높여 옵티마이저가 점진적으로 파라미터의 더 부드러운 영역을 찾아내도록 함
파라미터의 부드러운 영역을 찾은 뒤 해당 영역 내에서 가장 좋은 부분을 찾아야 함. 즉 학습률을 다시 작게 만들어야 함.
원 사이클 학습법의 이점
- 더 큰 학습률로 학습하므로 학습 시간이 짧음
- 더 큰 학습률로 학습하면 과적합 정도가 줄어듦. 일반화가 더 잘됨
원 사이클 학습법은 fastai의 fine_tune 메서드가 기본적으로 사용하는 접근법이기도 함.

위의 배치 크기를 늘렸을 때보다 더 좋은 정확도가 나옴.
전체 학습의 학습률과 모멘텀 확인하기

fit_con_cycle 메서드에서 조정할 수 있는 인잣값
- lr_max: 사용할 학습률의 최댓값
- div: 시작 학습률을 얻는 데 lr_max를 나누는 수
- div_final: 종료 학습률을 얻는 데 lr_max를 나누는 수
- pct_start: 웜엄에 사용할 배치의 비율(전체 배치 개수 중 사용할 비율)
- moms: (mom1, mom2, mom3)의 튜플. mom1은 초기 모멘텀, mom2는 최소 모멘텀,mom3는 최대 모멘텀임
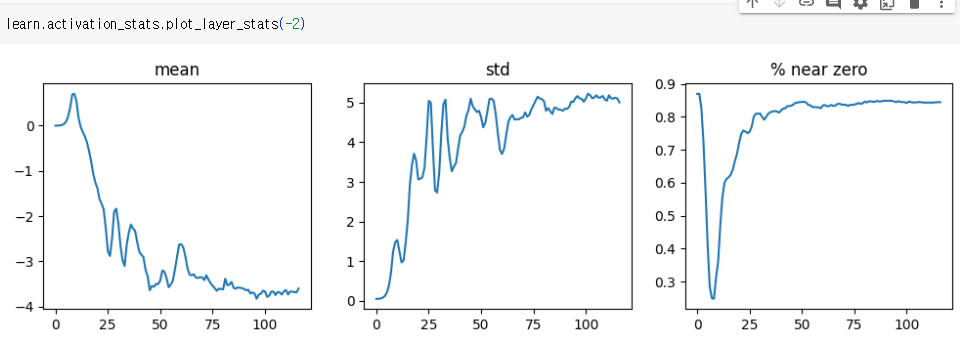
0에 가까운 가중치의 비율이 여전히 꽤 높지만 앞에서보다 훨씬 좋아짐.
color_dim 메서드를 호출하여 더 자세히 확인하기

색상의 강도는 각 히스토그램 구간 내 활성의 개수를 의미함.
위의 그림은 전형적인 '나쁜 학습'을 나타냄. 맨 왼쪽의 진한 파란색은 거의 모든 활성이 0에서 시작함을 나타냄. 하단의 밝은 노란색은 거의 0에 가까운 활성을 나타냄. 처음 몇 번의 배치에서 0이 아닌 활성의 개수가 기하급수적으로 증가함. 하지만 증가한 다음 다시 0이 됨(다시 짙은 파란색이 깊게 나타나고 아패에 밝은 노란색이 나타나는 부분). 즉 학습이 다시 처음으로 돌아가 버린 것처럼 보임. 학습이 진행되면서 정도는 줄지만 계속해서 활성값이 커졌다 줄어들었다를 반복함(짙은 파란색이 나타났다가 사라지길 반복). 그런 후에야 0이 아닌 값들로 안정화된 활성이 전체 범위에 걸쳐서 확산함.
-> 기하급수적인 증가와 하락의 주기는 거의 0에 가까운 활성을 유발하여 학습 속도가 느리고 나쁜 결과를 초래하는 경향이 있음.
처음부터 학습을 부드럽게 시작하기 위한 방법: 배치 정규화 사용
♣13.4.4 배치 정규화
정규화를 모델 구조의 한 부분으로 사용하고 미니배치별로 정규화 수행. 배치 정규화를 사용하면 훨씬 큰 학습률을 사용할 수 있을 뿐 아니라 초기화에 관한 걱정을 덜 수 있음
배치 정규화는 계층 활성의 평균과 표준 편차의 평균을 구해서 활성을 정규화함.
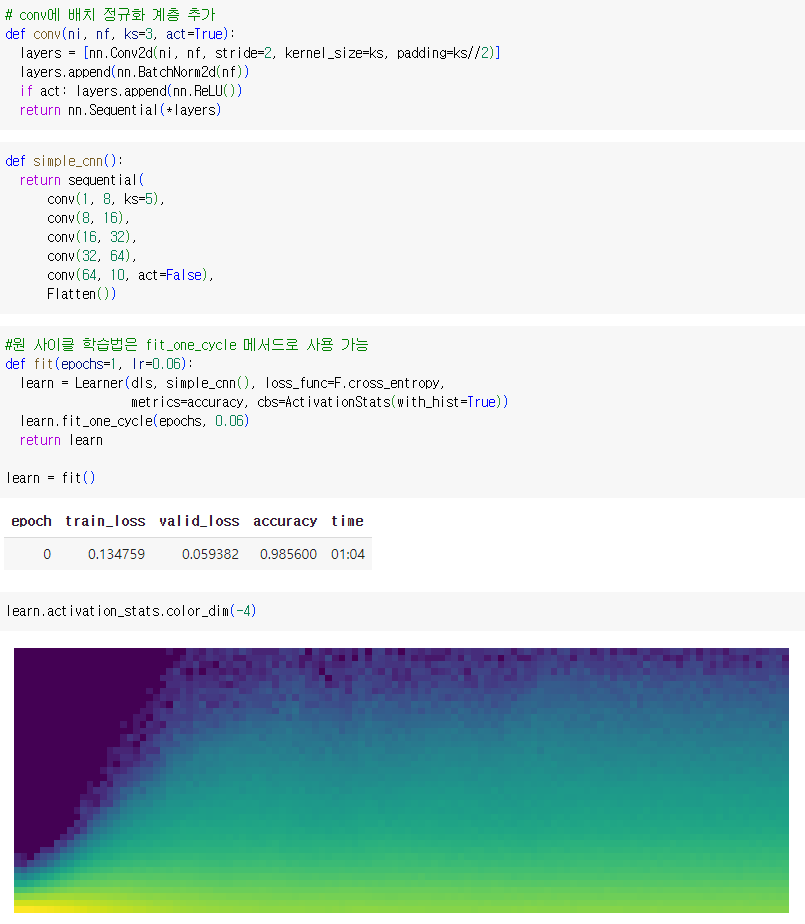
급작스러운 추락 없이 활성값이 부드럽게 발전됨. 배치 정규화 계층이 있는 모델은 그렇지 않은 모델보다 일반화가 더 잘되는 경향이 있음. 배치 정규화가 학습 과정에 임의성을 약간 추가하기 때문인 것으로 보임.각 미니배치에는 다른 미니배치와는 다소 다른 평균과 표준 편차가 있기 때문에 활성은 매번 다른 값으로 정규화됨.
학습률을 높게 잡아서 학습을 진행해보자
☎ 참고 자료
- 합성곱 계층: https://dsbook.tistory.com/72
합성곱 계층, Convolution Layer
합성곱 신경망, Convolutional Neural Network (CNN) 완전 연결 계층, Fully connected layer (JY) Keras 사용해보기 1. What is keras? 케라스(Keras)는 텐서플로우 라이버러리 중 하나로, 딥러닝 모델 설계와 훈련을 위한
dsbook.tistory.com
- 합성곱 신경망 교재
- Pooling: https://supermemi.tistory.com/entry/CNN-pooling%EC%9D%B4%EB%9E%80-tfkeraslayersMaxPool2D
[ CNN ] pooling이란? (tf.keras.layers.MaxPool2D)
pooling (tf.keras.layers.MaxPool2D) Pooling 이란. CNN에서 pooling이란 간단히 말하자면 특징을 뽑아내는 과정이라고 할 수 있다. 먼저 CNN의 pooling 이전의 진행 과정을 간단히 살펴보자. CNN이라는 게 결국 이
supermemi.tistory.com
- Pooling: http://taewan.kim/post/cnn/
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
- CNN의 전체적인 모습
https://haystar.tistory.com/25
딥러닝독학! (4) 합성곱 신경망 CNN - 밑바닥부터시작하는딥러닝
드디어 CNN을 다루는구나...... 겨울방학 프로젝트에 접하기만 하고 어떻게 돌아가는건지, 다루는건지 이해하지 못했었다. 가장 재밌..진 않고 파악하고 싶었던 딥러닝중에 하나이다. 참고로 이책
haystar.tistory.com
'CNN' 카테고리의 다른 글
| (논문)A guide to convolution arithmetic for deep learning (0) | 2023.08.07 |
|---|