2023. 12. 4. 21:49ㆍ딥러닝 모델: fastai
♣ 이미지 데이터 수집하기

♣ DataLoaders 만들기
다운로드한 데이터를 DataLoaders 객체로 만들기
DataLoaders: 전달받은 여러 DataLoader 객체를 목적에 맞게 학습용과 검증용으로 나누어 저장하는 클래스
*DataLoaders: fastai가 제공하는 여러 DataLoader를 저장하는 클래스. 개수 제한 없이 원하는만큼 DataLoader를 저장할 수 있지만 보통 학습용과 검증용으로 두 개를 저장함.
다운로드한 데이터로 DataLoaders를 만들려면 적어도 다음과 같은 네 가지 정보 필요함
1. 작업 데이터 유형
2. 데이터 목록을 가져오는 방법
3. 각 데이터에 레이블을 지정하는 방법
4. 검증용 데이터셋을 만드는 방법
<DataLoaders 클래스 정의하기>

DataLoaders 클래스를 만들기 어려울 경우, fastai에서 유연하게 사용할 수 있는 '데이터블록'이라는 시스템 제공
데이터블록 API를 사용해 DataLoaders 생성에 관련된 모든 단계를 사용자의 상황에 맞게 정의할 수 있음
<DataBlock API 사용하여 DataLoaders 생성하기>
- DataBlock 객체 생성

- blocks = (ImageBlock, CategoryBlock)
독립변수(예측에 사용되는 입력 데이터)와 종속변수(독립변수를 활용해 예측할 대상)의 데이터 유형을 tuple 형태로 지정
본 예제에서는 독립변수= 각각의 이미지/ 종속변수= 각 이미지의 범주
- get_items = get_image_files
DataLoaders에 제공되는 데이터는 '실제 데이터가 위치한 파일 경로'임. 즉 파일 경로 목록을 가져오는 방법을 명시함
fastai가 제공하는 get_image_files 함수는 인자로 주어진 경로에 포함된 모든 이미지 목록을 찾아서 반환함
- splitter = RandomSplitter(valid_pct=0.2, seed=42)
시드를 이용해서 데이터 나누기를 고정(여기서는 훈련 데이터와 검증 데이터로 나눔)
- get_y = parent_label
fastai에서 제공하는 parent_label 함수는 파일이 저장된 폴더명을 가져옴. 여기서는 이미지를 곰의 유형과 같은 이름의 폴더에 가지고 있기 때문에 parent_label로 레이블(종속변수 y)를 구할 수 있음
아래 코드를 사용하여 parent_label을 이용하면 폴더의 이름을 잘 가지고 오는 것을 확인할 수 있음

- item_tfms=Resize(128)
모델에 주입할 여러 이미지를 텐서로 구성하려면 모든 이미지의 크기가 같아야 함. 따라서 이미지의 크기를 똑같이 맞추는 변형(transform)이 필요함. 요소 변형 인자에는 이미지, 범주 등 개별 요소를 변형하는 방법을 지정할 수 있음.
Resize는 이미지의 크기를 바꿈. 이때 너비나 높이 중 더 작은 쪽을 기준으로 나머지를 잘라내는 작업(crop)이 기본임.
- dataloaders 메서드 호출하여 DataLoaders 생성

fastai에는 DataLoader에 show_batch 메서드 구현해둠. 하나의 배치 요소 중 일부를 화면에 출력하는 기능.
이를 사용하여 데이터블록 API가 구성한 데이터를 모델에 주입하기 전에 미리 확인할 수 있음

변형에서 Resize를 사용하면 이미지를 잘라내면서 중요한 세부 사항이 유실될 수 있음.
대안: 이미지 찌그러뜨리기, 너비나 높이 중 더 큰 쪽을 기준으로 맞춘 뒤 빈 곳을 0으로 채우거나 이미지 늘려 채우기

- ResizeMethod.Squish
이미지를 찌그러뜨리거나 늘린 것. 비현실적으로 변형되어 모델이 실제와는 다른 형태를 학습할 수 있음.
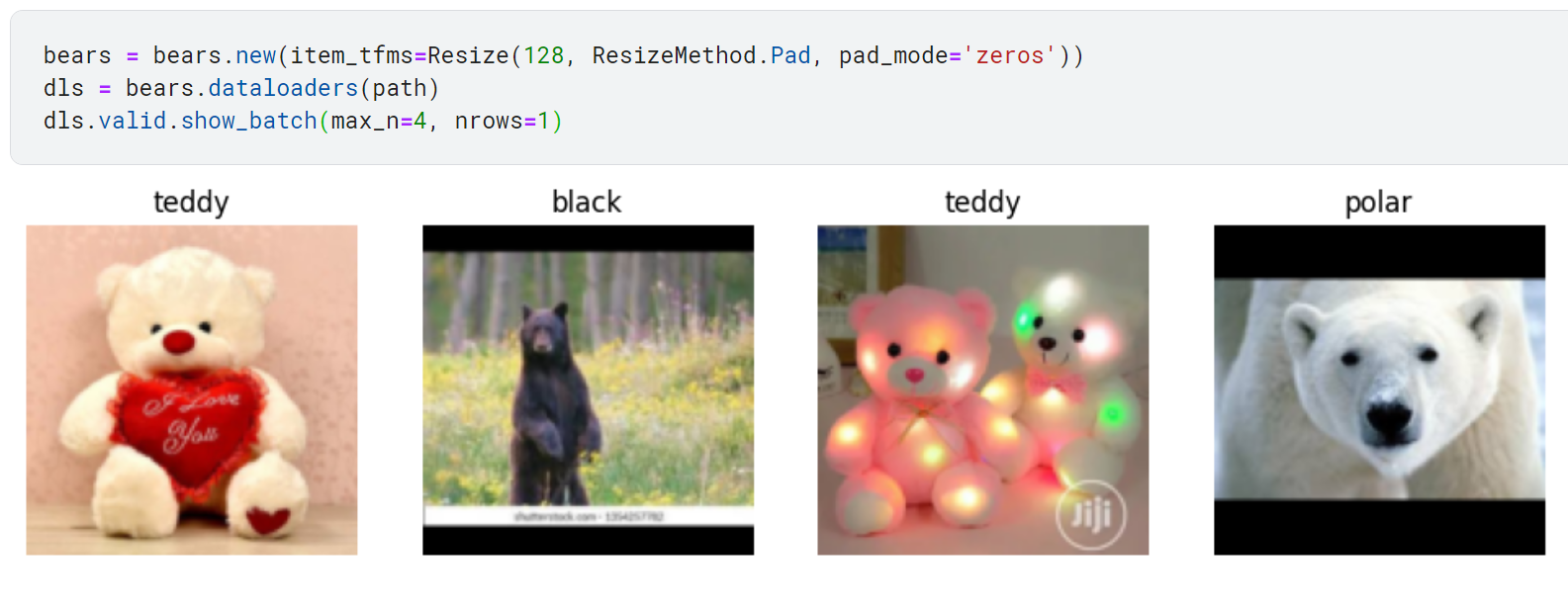
- ResizeMethod.Pad
빈 곳을 검은색으로 패딩 처리함. 이러한 패딩 처리는 불필요한 빈 공간을 만들어내어 모델의 계산 처리에 큰 낭비가 발생.
실제 필요한 이미지 부분에 대한 유효해상도가 낮아지는 결과 초래.
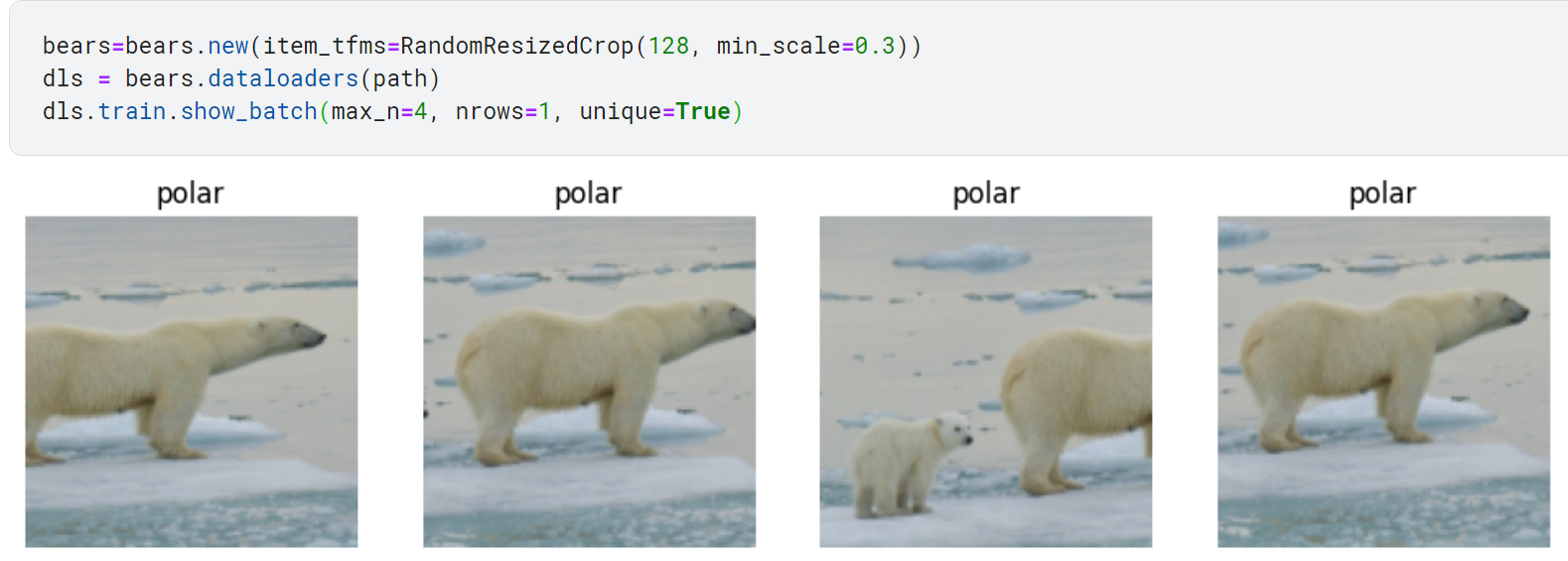
- RandomResizedCrop
실전에서는 이미지의 특정 부분을 무작위로 선택하여 잘라내는 방식을 보편적으로 사용함. 즉 epoch 마다 무작위로 각 이미지의 다른 부분을 선택함. 이 방식은 모델이 각 이미지의 서로 다른 위치에 드러난 특징에 집중하여 다양성을 인식할 수 있는 방향으로 학습 기회를 제공함.
min_scale 인자는 매번 이미지의 얼마나 많은 영역을 선택할지 결정함.
show_batch 메서드에서 인자값 unique=True를 활성화하면 동일 이미지에 반복해서 적용되는 RandomResizedCrop 변형이 만드는 서로 다른 이미지를 확인할 수 있음.
♣ 데이터 증강
입력 데이터를 임의 로 변형해 새로운 데이터를 생성하는 기법.
변형된 결과들은 서로 다른 개체를 만들지만, 데이터 자체의 의미를 바꿔서는 안 됨.
회전(rotation), 뒤집기(flip), 원근 뒤틀기(perspectivs warping), 명도 바꾸기(brightness), 채도 바꾸기(contrast) 등이 있음

aug_transforms 함수를 이용하여 자연스러운 사진에 잘 작동하는 것으로 알려진 표준적인 데이터 증강 목록을 사용할 수 있음
Resize 변형으로 모든 이미지의 크기를 똑같이 맞추고 나면 GPU가 배치마다 병렬로 연산을 수행하므로 시간이 절약됨
- batch_tfms
데이터블록 API에서 제공하는 인자로 GPU에서 배치 단위로 적용할 변형을 지정함.
aug_transforms에 mult=2를 설정하여 기본값보다 두 배로 조정된 데이터 증강을 적용함. aug_transform에는 회전, 뒤틀기, 명도 등을 얼마나 변형할지 미리 정의해두는데, mult 값은 미리 정의된 변형의 정도에 곱해짐.
*mult 인자가 없을 때와 이미지를 비교해보

♣ 모델 훈련과 훈련된 모델을 이용한 데이터 정리
- dataloaders 만들기

RandomResizedCrop 변형과 디폴트값으로 구성된 aug_transforms를 활용하여 모델을 학습시킬 예정.
- Learner 객체를 만들고 미세 조정하기
- 오차행렬을 이용하여 error 파악하기
오차행렬: fastai가 제공하는 모델의 결과를 파악하는 여러 방법 중 하나.
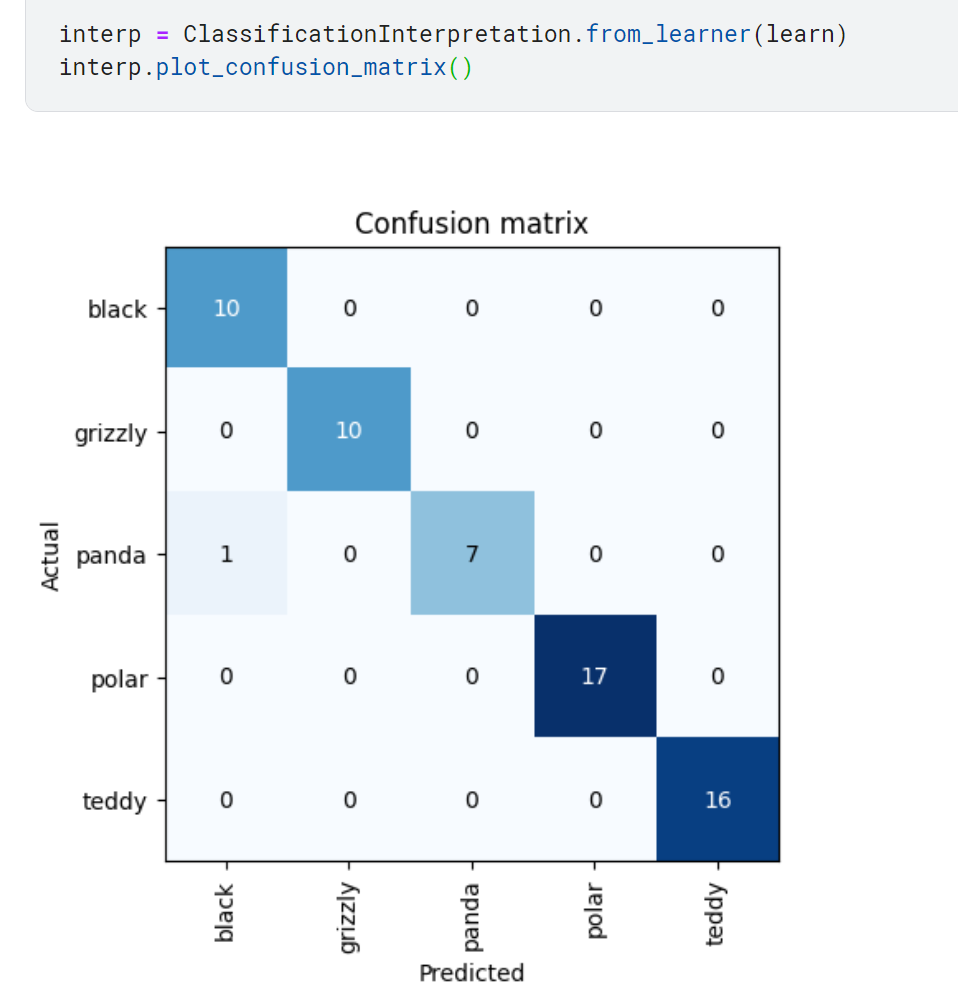
모델이 올바르게 분류한 이미지는 대각선에, 잘못 분류한 이미지는 그 외의 위치에 표시됨.
오차 행렬에 표시된 결과는 검증용 데이터셋에 대한 것임.
plot_top_losses 메서드는 가장 손실이 높은 이미지를 보여줌.

위의 interp에서 틀린 이미지가 1개여서 plot_top_losses를 보면 예측이 틀린 이미지가 한 개임.
순서: 예측된 범주, 실제 범주(타깃 레이블), 손실, 확률 정보
fastai는 간단히 데이터를 정리할 수 있는 ImageClassifierCleaner를 제공함. 여기서 범주별, 학습/검증용 데이터셋별로 가장 손실이 큰 순서대로 정렬된 이미지를 확인할 수 있음

- 위의 cleaner에서 delete를 선택한 이미지를 삭제하는 방법

- 위의 cleaner에서 레이블 변경을 선택한 모든 이미지를 알맞은 범주의 디렉터리로 옮기는 방법
♣ 모델을 온라인 애플리케이션으로 전환하기
모델은 두 부분으로 구성됨: 모델의 구조와 파라미터
구조와 파라미터를 모두 저장하는 것이 가장 쉽게 모델을 저장하는 방식임.
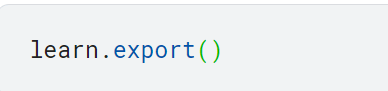
모델의 export 메서드를 사용하여 모델의 구조 및 파라미터를 모두 파일로 쉽게 저장할 수 있음
또한 export 메서드는 DataLoaders 생성 방법의 정의까지 저장함. 그렇지 않으면 데이터의 변형 방법을 다시 정의해야 함.

fastai가 파이썬의 표준 클래스 Path에 추가한 ls 메서드를 사용하여 해당 파일이 생성되었는지 확인함

- load_learner
load_learner 함수를 사용하면 파일로 저장된 모델을 이용하여 추론용 Learner 객체를 생성할 수 있음.
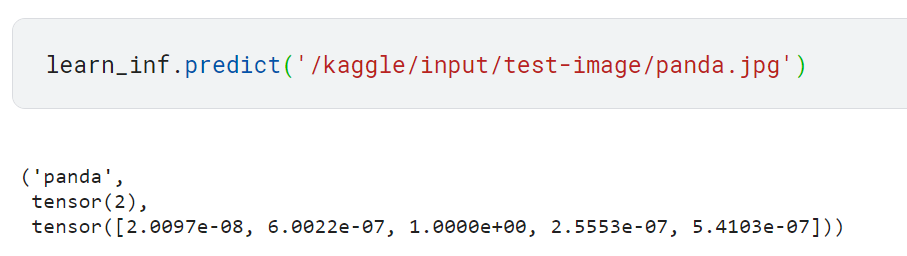
- predict
test 이미지를 한 장 가져와서 라벨 추론하기
predict 메서드는 세 가지를 반환함. 첫 번째는 예측한 범주, 두 번째는 예측한 범주의 색인 번호, 마지막은 범주별 확률
색인 번호와 범주별 확률 순서는 DataLoaders의 vocab에 저장된 모든 범주 목록의 순서에 따라 결정됨.
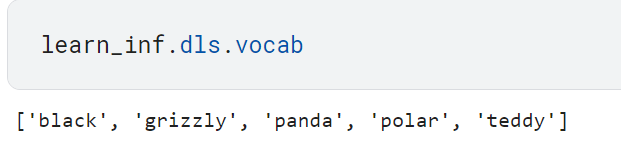
Learner의 dls 속성을 활용해서 DataLoaders에도 접근 가능함. tensor(2)는 위에서 'pandas'에 대응함을 확인.
범주별 확률 목록을 살펴보면 거의 1에 가까운 확신으로 'pandas'라고 예측함.
♣ 해당 코드
https://www.kaggle.com/code/polljjaks/notebookc8aa597ff7/edit/run/153717199
notebookc8aa597ff7
Explore and run machine learning code with Kaggle Notebooks | Using data from Bear dataset
www.kaggle.com
'딥러닝 모델: fastai' 카테고리의 다른 글
| Chapter 6. 그 밖의 영상 처리 문제 (0) | 2024.01.07 |
|---|---|
| Chapter 5. 반려동물의 품종 분류하기 (0) | 2023.12.17 |
| chapter4. 숫자 분류기 예시(숫자 3과 7의 손글씨 이미지 분류) (1) | 2023.12.08 |
| fastai 라이브러리 (0) | 2023.08.15 |
| DataLoader 만들기 비교 (0) | 2023.08.10 |