2023. 12. 8. 21:48ㆍ딥러닝 모델: fastai
♣ 픽셀: 컴퓨터 영상 처리의 기본 토대
- MNIST 샘플 데이터셋 다운로드하기

- ls 메서드를 사용하여 해당 디렉터리의 내용 확인하기
ls 메서드는 fastai에서 제공하는 L 클래스 객체를 반환함. L 클래스는 목록과, 목록의 개수를 함께 출력하는 유용한 기능을 포함함.

MNIST는 학습과 검증(또는 테스트용) 데이터셋을 별도의 폴더로 분리해서 보관하는 일반적인 머신러닝 데이터셋의 구조
- 학습 데이터셋의 폴더 내용 확인하기

'train' 폴더 안에 3과 7 폴더가 들어있음
- 3, 7 폴더 안의 내용 확인하기(항상 파일 출력 순서가 같도록 sorted 메서드로 정렬)
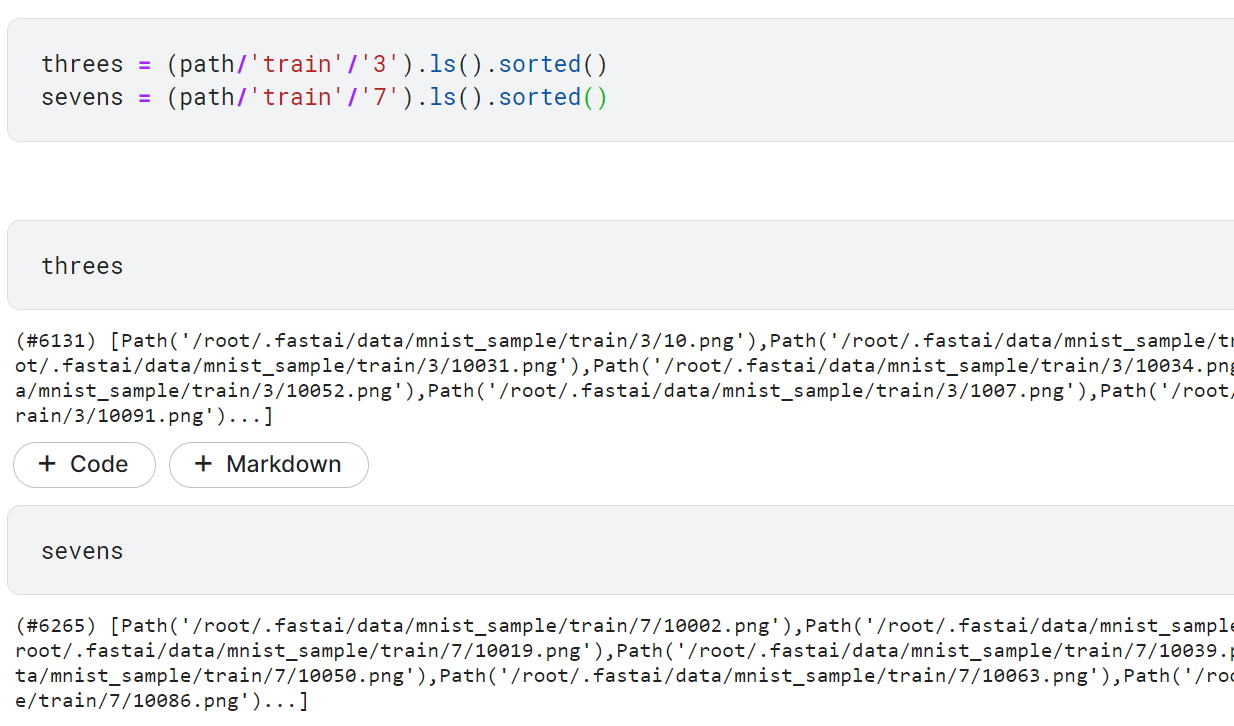
- 폴더 안의 이미지 확인하기

Image 클래스는 파이썬 영상 처리 라이브러이(PIL)이 제공함. PIL은 이미지를 열고, 조작하고, 출력할 때 가장 널리 사용하는 파이썬 패키지임.
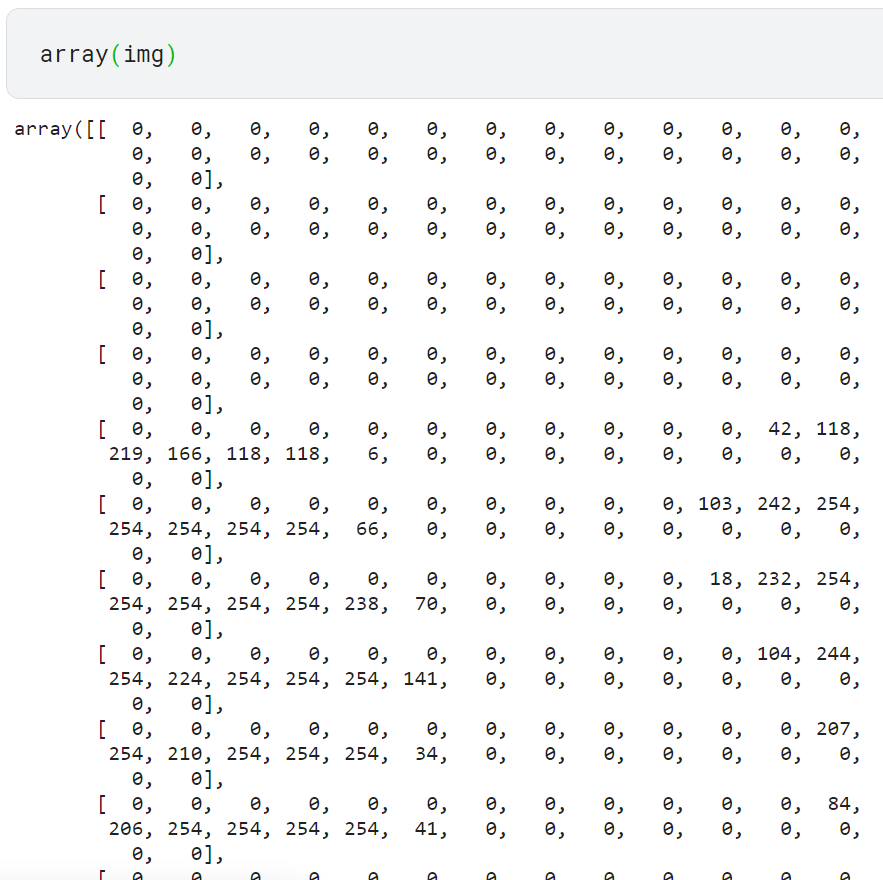
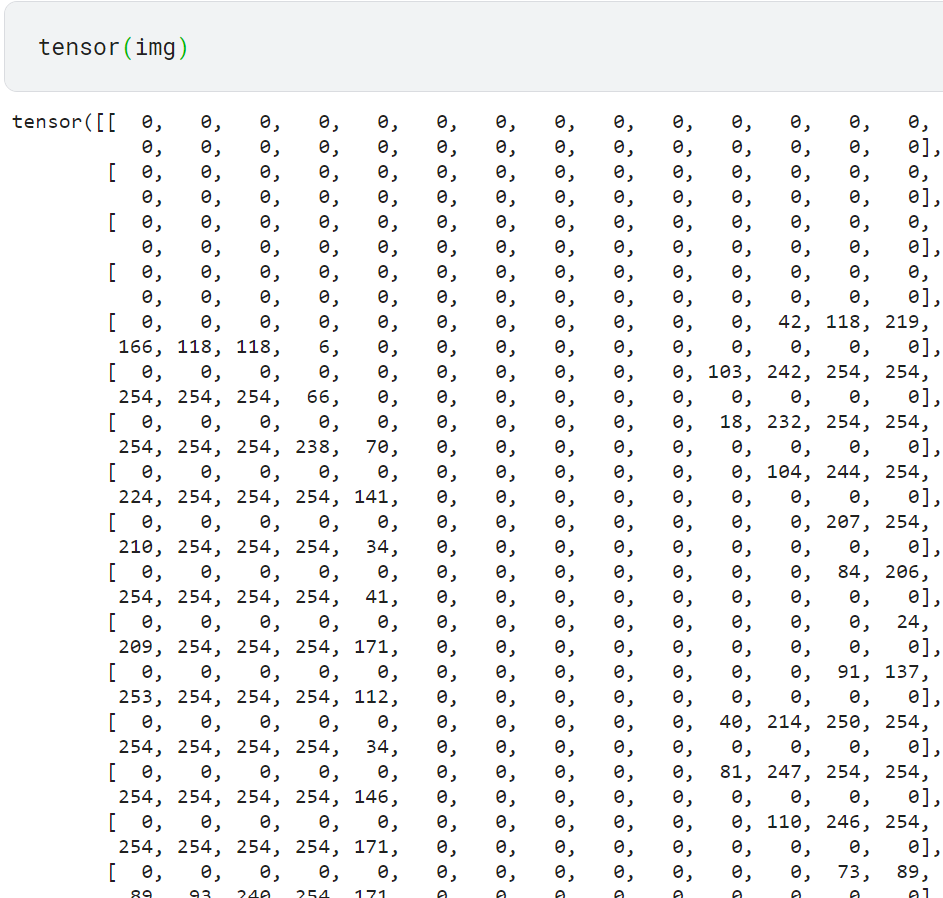
- 이미지를 숫자로 변환하기
이미지를 구성하는 숫자를 확인하려면 이미지를 넘파이 배열 혹은 파이토치 텐서로 변환해야 함
- 넘파이 사용
-텐서 사용
- 이미지를 pandas 데이터 프레임으로 숫자의 값에 따라 색상 그라데이션 입히기


♣ 3과 7을 구별하는 모델 만들기 첫 번째 시도: 픽셀 유사성
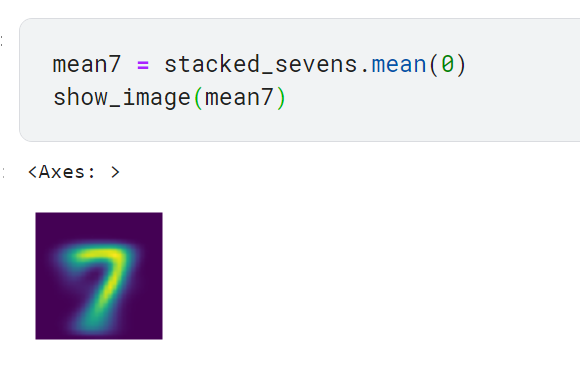
숫자 3과 7 각각에 대한 모든 이미지의 평균 픽셀값을 구함. 두 숫자에 대해 얻은 평균 픽셀값 = 이상적인 3과 7
과 7을 구별하는 모델
새로운 이미지가 이상적인 두 이미지 중 어느 쪽에 가까운지 계산하여 분류할 수 있음.
- 각 이미지에 대한 텐서 목록으로 구성된 리스트 생성하기

- 리스트가 제대로 만들어졌는지 이미지 검사하여 확인하기
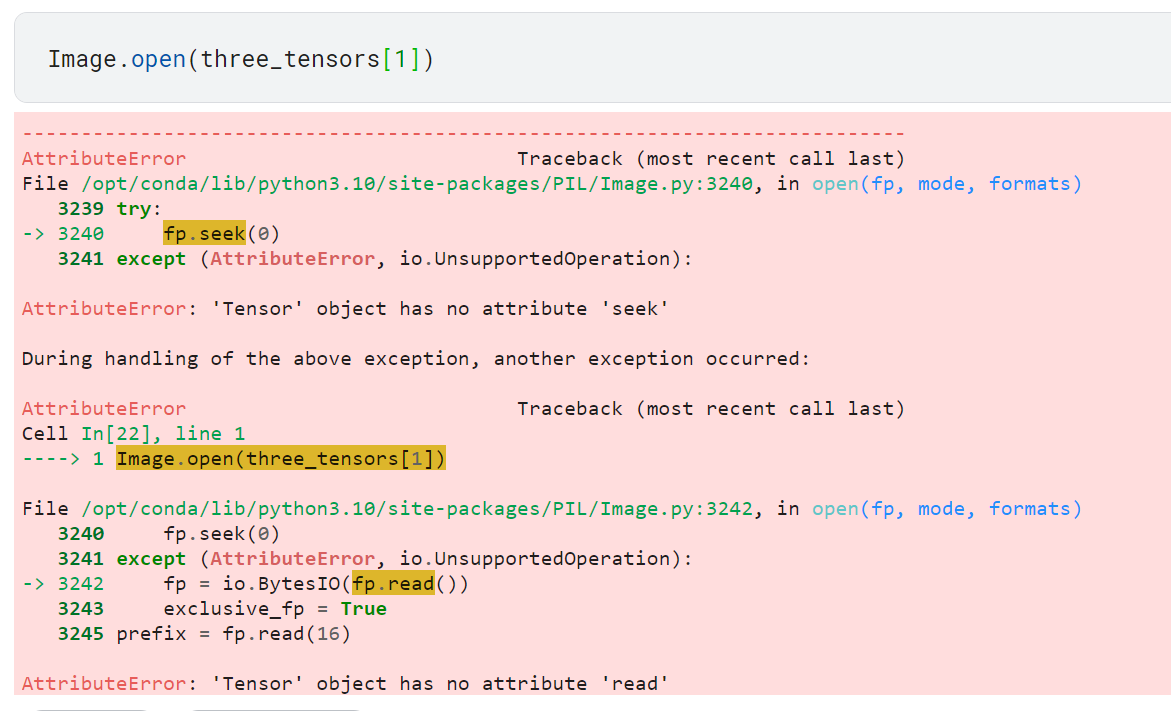
PIL 패키지의 Image가 아니라 tensor 형식으로 담긴 이미지를 출력해야 하므로 fastai가 제공하는 show_image 함수 사용
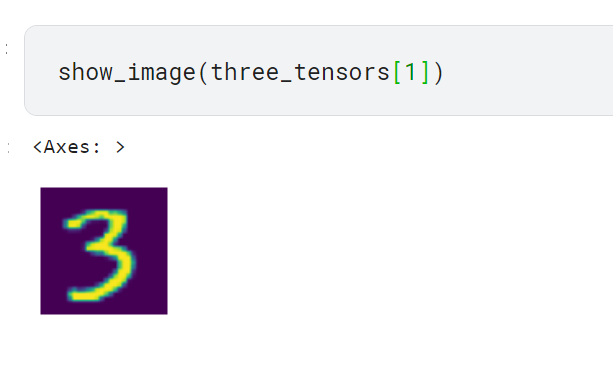
Image.open을 사용하면 이미지가 제대로 열리지 않음
- 텐서 이미지를 쌓아올리고, 부동소수로 표현하기

3 이미지는 6131장이고, 너비 28픽셀, 높이 28픽셀임.
- 텐서의 차원(축의 개수) 알아보기
- stacked 사용

- ndim 속성 사용

- 평균적인 이미지 만들기(평균 픽셀값으로 구성된 이미지 한 장)

0번째 차원은 이미지를 색인하는 차원임.
- 이상적인 숫자와 선택한 이미지와의 거리 결정하기
임의로 선택한 이미지

- 계산방법1: 차이의 절댓값에 대한 평균을 구하는 방법. L1 노름 또는 평균절대차라고 함
- 계산방법2: 차이의 제곱에 대한 평균의 제곱근을 구하는 방법. L2 노름 또는 평균제곱근오차라고 함
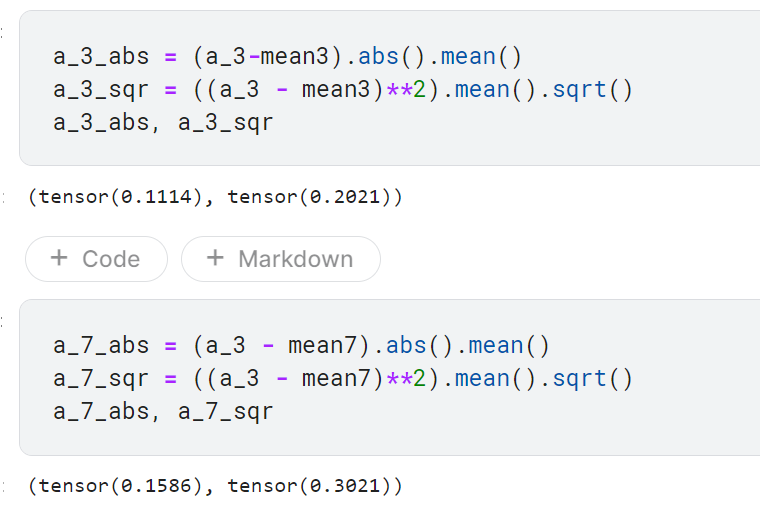
a_3 이미지를 이상적인 숫자 3, 이상적인 숫자 7과의 거리를 각각 비교했을 때 이상적인 숫자 3과의 차가 더 작음.
따라서 a_3 이미지를 7이 아닌 3이라고 예측할 수 있음.
- 손실함수
파이썬은 위의 두 가지 방법(L1, L2)에 대한 손실함수를 제공함. 각 손실함수는 torch.nn.functional에서 찾을 수 있음
l1_loss 를 이용하여 이상적인 3의 평균 이미지와 가까운지 이상적인 7의 평균 이미지와 가까운지 계산하기

mse_loss를 이용하여 이상적인 3의 평균 이미지와 가까운지 이상적인 7의 평균 이미지와 가까운지 계산하기(L2는 평균제곱근 오차니까 mse_loss 사용)

*float()를 쓰든 안 쓰든 결과값에는 차이가 없다.
♣ 브로드캐스팅으로 평가지표 계산하기
평가지표: 데이터셋에 표기된 올바른 레이블과 모델이 도출한 예측을 비교해서 모델이 얼마나 좋은지 평가하는 단일 숫자
보통 정확도(accuracy)를 분류 모델 평가지표로 사용함.
검증용 데이터셋을 대상으로 평가지표를 계산함. -> 학습용 데이터셋에서만 잘 작동하는 과적합을 피하기 위함.
MNIST에는 이미 검증용 데이터가 valid 디렉토리로 분류되어 있음.
- 검증용 데이터로 3과 7에 대한 텐서 만들기(픽셀유사도를 이용한 첫 번째 모델을 평가하기 위해 사용할 텐서)

- 임의로 입력된 이미지가 3인지 7인지 판단하는 함수 만들기
평균절대오차를 계산하는 간단한 함수 mnist_distance

위에서 사용한 l1_loss의 결과와 값이 같음.
전체 이미지에 대한 평가지표를 계산하려면 검증용 데이터셋 내 모든 이미지와 이상적인 숫자 3 이미지의 거리를 계산해야 함. 검증용 데이터셋을 담은 텐서 valid_3_tens에 반복 접근하여 한 번에 개별 이미지 텐서에 접근하는 방법이 있음
- 하지만 이보다 더 나은 방법을 소개!

위에서 쌓은 검증용 데이터 3 이미지를 mnist_distance에 넣어 mean3와 계산하면 모든 이미지에 대해 측정한 거리를 담는 벡터가 반환됨. valid_3_tens는 3차원이고, mean3는 2차원인데 이러한 계산이 가능한 이유는 '브로드캐스팅' 때문임
브로드캐스팅은 더 낮은 차원의 텐서를 더 높은 차원의 텐서와 같은 크기로 자동 확장함. 이후 파이토치가 차원이 같은 두 텐서에 로직을 적용함. 즉 2차원 텐서인 mean3에 복사본 이미지가 1010장 있다고취급하여 검증용 데이터셋 내의 각 이미지와 복사본 이미지에서 뺄셈을 수행함.
뺄셈을 수행하여 얻은 텐서의 모양은 [1010, 28, 280]임. 이미지의 수가 1010이고 너비와 높이가 각각 28px임

이 값에 abs().mean((-1, -2))를 실행하면 1차원의 값을 구할 수 있음. 그래서 valid_3_dist의 shape가 torch.Size([1010)]
mean((-1, -2))에서 -1과 -2는 각각 이미지의 가로, 세로 차원을 의미함. 이 코드는 이미지 텐서의 가로와 세로의 모든 값에 대한 평균을 구하는 작업을 수행함. 두 차원에서 평균을 구한 결과로 얻는 텐서에는 이미지 색인을 담당한 첫 번째 차원만 남음.

is_3 함수는 불린값을 반환하는데, 이를 float() 처리하면 True는 1.0, False는 0.0으로 변환됨.

브로드캐스팅 덕분에 검증용 데이터셋의 모든 숫자 3 이미지도 is_3 함수 적용 가능.
- 검증용 데이터셋으로 3과 7을 구별하는 모델 평가하기

accuracy_3s는 검증용 데이터셋 중 3으로 분류된 이미지들이 평균 이미지 7보다 평균 이미지 3에 가까울 확률을 나타냄. 즉 3인 검증용 이미지가 실제로 3으로 분류될 확률
accuracy_72는 검증용 데이터셋 중 3으로 분류된 이미지들이 평균 이미지 3보다 평균 이미지 7에 가까울 확률을 나타냄.
즉 7인 검증용 이미지가 실제로 7로 분류될 확률
하지만 이 픽셀 유사성을 따지는 모델에서 만족하지 말고, 실제로 무언가를 학습하는 시스템을 시도해보자!
♣ 확률적 경사하강법
아서 사무엘이 묘사한 머신러닝:
'현재 할당된 모든 가중치의 유효성을 자동으로 검증하는 수단이 있으며 성능을 최대화하는 방향으로 할당된 가중치를 수정해나가는 매커니즘'
위의 픽셀 유사성을 따지는 모델은 파라미터 조정을 하지 않기 때문에 아서 사무엘이 묘사한 머신러닝과는 맞지 않음
특정 이미지와 '이상적인 이미지' 사이의 유사도를 찾는 대신, 개별 픽셀마다 가중치를 설정하고 숫자를 표현하는 검은색 픽셀의 가중치를 높이는 방법을 생각해보자.
<구체적인 단계>
- 가중치를 초기화(initialize)
- 현재 가중치로 이미지가 3 또는 7인지 예측(predict)
- 예측한 결과로 모델이 얼마나 좋은지 계산(손실 측정)
- 가중치 갱신 정도가 손실에 미치는 영향을 측정하는 그레이디언트(gradient) 계산
- 위에서 계산한 그레이디언트로 가중치의 값을 한 단계 조정
- 2번째 예측 단계로 돌아가서 과정을 반복
- 학습 과정을 멈춰도 좋다는 판단이 설 때까지 계속해서 반복

<각 단계의 일반적인 접근법>
- 초기화
파라미터의 값을 무작위로 초기화함. 임의의 값으로 설정할 수도 있지만 사전에 학습된 모델로부터 설정할 수도 있음(전이 학습). 하지만 임의로 선정한 값이나 하전에 학습된 모델이 우리가 원하는 특정 문제에서 좋은 성능을 보일 가능성은 작음. 모델은 더 나은 가중치를 학습해야 함.
- 손실
모델의 성능이 좋을 때 낮은 값을 반환하는 함수 필요(일반적으로 적은 손실은 좋고, 큰 손실은 나쁨)
- 가중치 단계 갱신
가중치를 약간씩 조정하고 손실의 변화를 관찰. 올바른 방향을 찾으면 잘 작동하는 크기를 찾을 때까지 좀 더 크거나 작은 크기로 바꾸는 시도를 함. 하나씩 진행하면 느리므로 미적분학을 사용하여 그레이디언트를 계산하여 방향을 즉시 알아냄. 크기를 조금씩 바꾸는 방식을 사용하지 않아도 개략적으로 가중치를 얼마나 갱신해야 하는지를 알 수 있음
- 훈련 종료
모델을 학습할 에포크 횟수를 정하여 적용함. 숫자 분류 모델 예제에서는 모델의 정확도가 높아지다가 낮아지는 시점까지, 또는 사정상 시간이 부족한 시점까지 계속해서 학습을 수행함.
<확률적 경사하강법 간단한 예시>
1. 손실 함수 정의(여기서 x는 함수의 가중치 파라미터라고 가정)

2. 손실 함수 그래프 그리기

3. 임의의 파라미터 값(-1.5)을 선택하고, 손실값(-1.5**2) 계산

4. 파라미터를 약간씩 크거나 작게 조정했을 때 일어나는 일 살펴보기
기울기 방향에 따라서 가중치를 조금씩 바꿈. 그 후 다시 손실을 계산하고 가중치를 조정하는 과정을 반복하다 보면 결국 2차 함수 곡선의 가장 낮은 부분에 도달하게 됨.
<그레이디언트 계산>
그레이디언트는 모델이 더 나아지려면 갱신해야 할 가중치의 정도를 알려줌.
그레이디언트 = y의 변화량 / x의 변화량 => 즉 파라미터 값의 변화로 함숫값의 변화를 나눔.
<학습률을 사용해 단계 밟아나가기>
그레이디언트로 파라미터의 조절 방식을 결정할 때, 학습률이라는 작은 값을 그레이디언트에 곱하는 기본적인 아이디어에서 출발함. 학습률의 값은 대부분 0.001과 0.1 사이의 값이 선택됨.
때로는 학습 과정을 여러 번 시도하여 가장 좋은 모델의 결과를 도출한 학습률을 선택하기도 함.
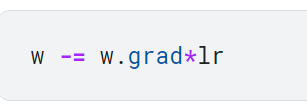
학습률을 선택하고 나면 간단한 함수를 사용해서 파라미터를 조정
학습률이 너무 작으면 많은 단계를 수행해야 하고, 학습률이 너무 크면 손실이 더 심해지는 결과를 초래할 수 있음
<SGD를 활용한 시작부터 끝까지를 보여주는 예제>
*가장 높은 지점으로 올라가는 롤러코스터의 속도를 측정하는 상황
시간에 따른 속력의 변화 정도를 예측하는 모델 만들기. 20초 동안 수작업으로 속력을 측정해서 다음 형태를 띤 그래프를 얻는다고 가정
-시간

- 시간에 따른 스피드를 측정한 그래프

- 입력 time과 그 외의 모든 파라미터 params가 있는 함수 정의하기

다르게 이야기하면 데이터에 가장 잘 들어맞는 2차 함수라는 제한된 함수를 찾는 문제를 다룬다고도 볼 수 있음
가장 적합한 2차 함수를 찾는 문제는 가장 적합한 a, b, c 값을 찾으면 해결됨
- 손실함수 정하기

<위의 일곱 단계 다루기>
- 가중치를 초기화(initialize)
- 현재 가중치로 이미지가 3 또는 7인지 예측(predict)
- 예측한 결과로 모델이 얼마나 좋은지 계산(손실 측정)
- 가중치 갱신 정도가 손실에 미치는 영향을 측정하는 그레이디언트(gradient) 계산
- 위에서 계산한 그레이디언트로 가중치의 값을 한 단계 조정
- 2번째 예측 단계로 돌아가서 과정을 반복
- 학습 과정을 멈춰도 좋다는 판단이 설 때까지 계속해서 반복
1단계: 파라미터 초기화
파라미터를 임의의 값으로 초기화하고 requires_grad 메서드를 사용하여 파이토치가 파라미터의 그레이디언트를 추적할 수 있도록 함

requires_grad_ 메서드는 변수에 일종의 태그를 붙이고, 파이토치가 태그 정보를 활용하여 기존의 텐서에 추가 연산이 발생하더라도 모든 연산을 추적하여 그레이디언트를 계산하는 방법을 기억함.
2단계: 예측 계산
함수에 입력과 파라미터를 넣어서 예측을 계산하기

예측과 실제 타깃의 유사도를 그래프로 확인하는 간단한 함수 만들기
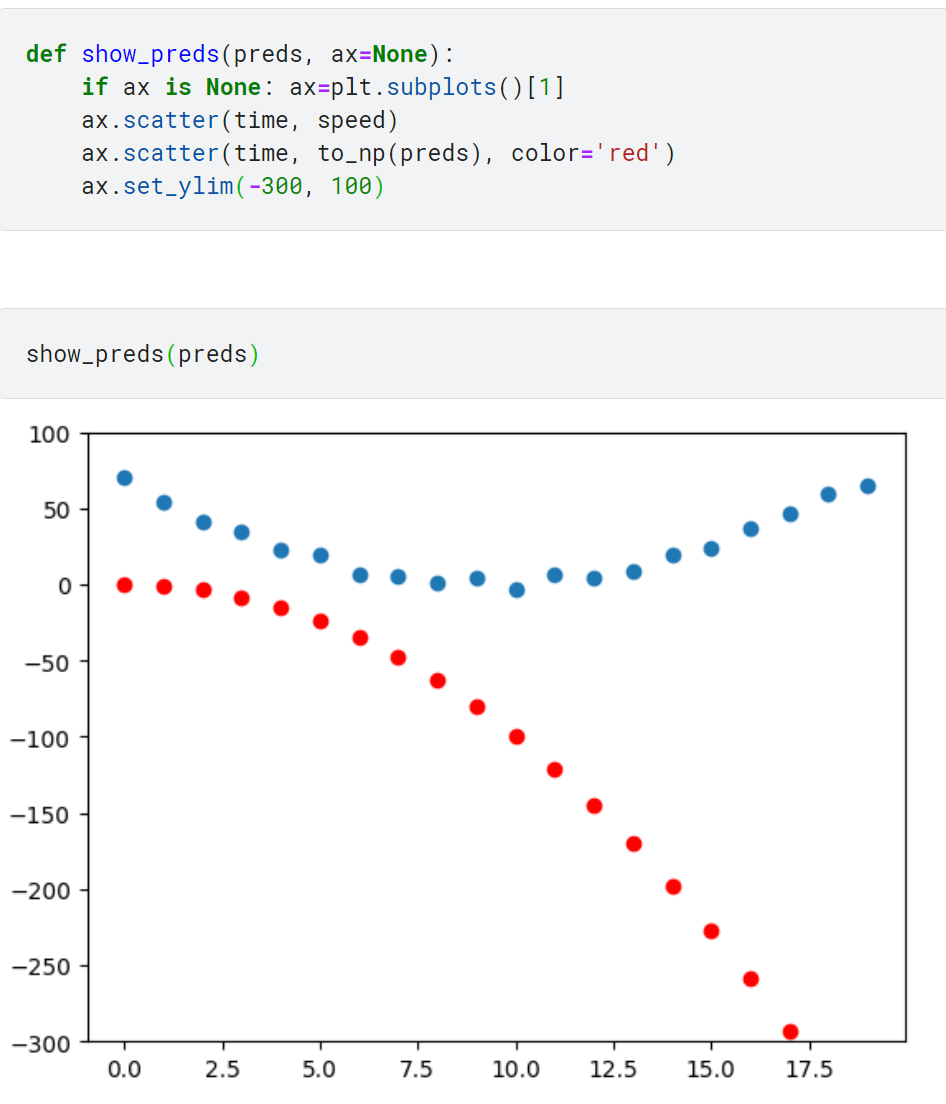
타깃과 예측이 완전히 다름.
3단계: 손실 계산

이제 계산된 손실값을 줄여서 성능을 높이는 것이 목표임
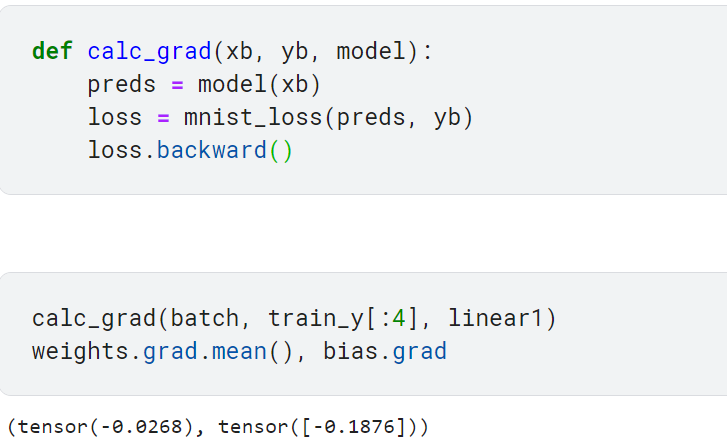
4단계: 그레이디언트 계산
파라미터 값이 바뀌어야 하는 정도를 추정하는 그레이디언트 계산하기
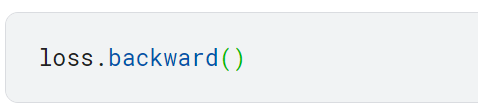
backward 메서드를 호출하여 그레이디언트 계산함

그레이디언트를 계산한 후, 텐서의 grad 속성으로 실제 계산된 그레이디언트 알기
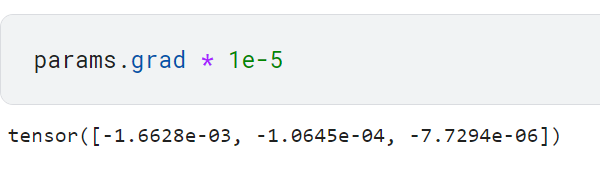
계산된 그레이디언트로 파라미터값을 개선하기 위해 학습률 선택

5단계: 가중치를 한 단계 갱신하기
계산된 그레이디언트에 기반하여 파라미터 값 갱신

손실이 개선되었는지 확인하고 파라미터가 개선된 2차 함수 그리기

위와 같은 과정을 수차례 반복해야 하므로 모든 과정을 담은 함수를 만듦.

6단계: 과정 반복하기
반복 과정에서 성능이 많이 향상되면 더 좋은 결과를 기대할 수 있음
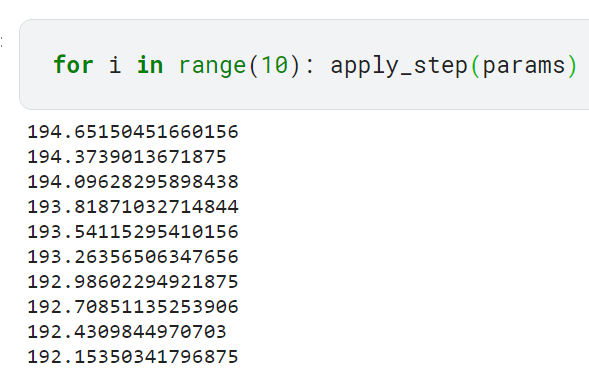
기대한 대로 손실이 점점 낮아짐. 이 과정을 2차 함수로 나타내기

7단계: 학습 종료
10번의 에포크 후 학습 종료.
실전에서는 학습용과 검증용 데이터셋에 대한 손실 및 평가지표를 주시하면서 학습 종료 시점을 결정해야 함.
♣ MNIST 손실 함수
- 이미지를 담은 독립변수 x를 단일 텐서로 엮어 행렬의 목록(3차원 텐서) 만들고, 이를 다시 벡터의 목록(2차원 텐서)으로 바꾸기

- 각 이미지에 맞는 레이블 만들기. 숫자 3에는 1, 숫자 7에는 0

- 파이토치의 Dataset은 (x, y) 튜플을 반환하기를 요구함. 파이썬의 zip 함수를 list와 함께 사용하여 Dataset 구성하기


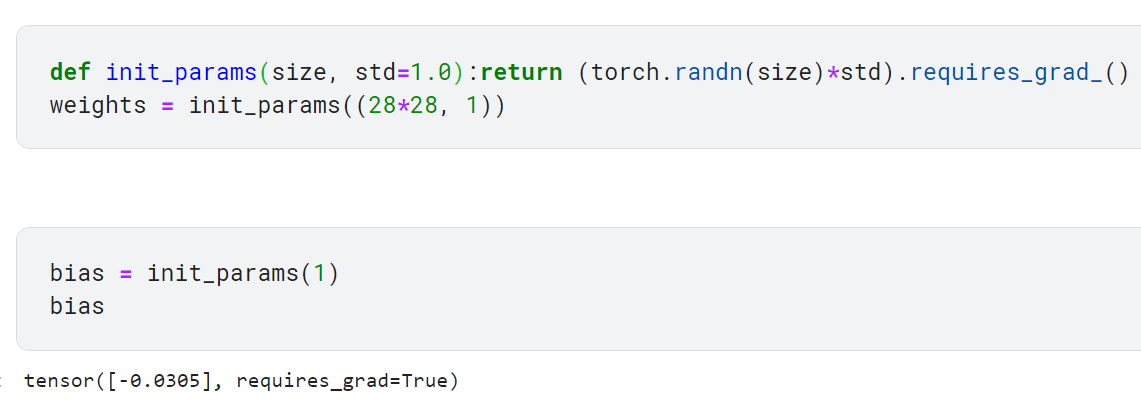
- 각 픽셀에 임의로 초기화된 가중치(weight)와 편향(bias) 만들기(7단계 중 초기화 단계)
직선 방정식은 y = w*x+b 형태임. 이처럼 가중치만이 아니라 편향도 추가하자. 가중치와 편향을 모두 통틀어서 파라미터라고 함.
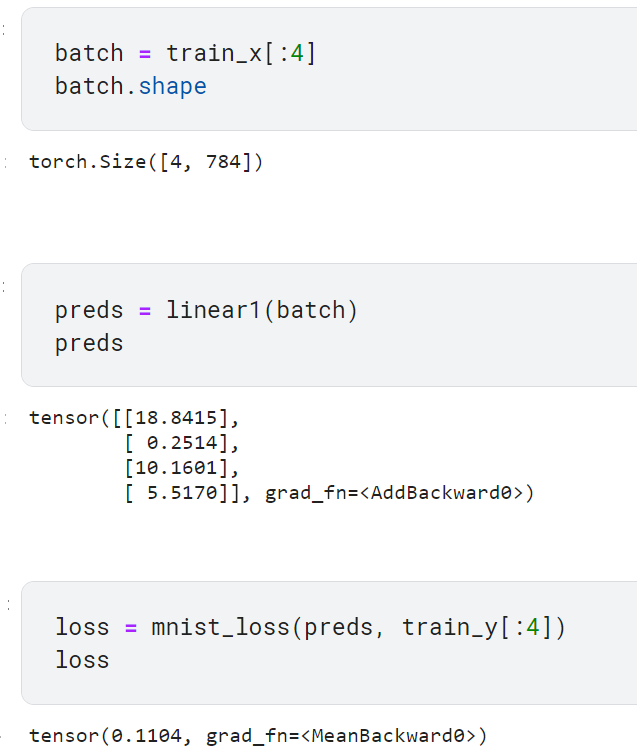
- 단일 이미지에 대한 예측 계산하기

각 이미지의 예측 계산에 파이썬의 for 반복문을 사용할 수도 있지만 속도가 매우 느림. 모든 행에 대해 w*x를 계산하는 행렬 곱셈을 사용하면 빠르게 계산이 가능함
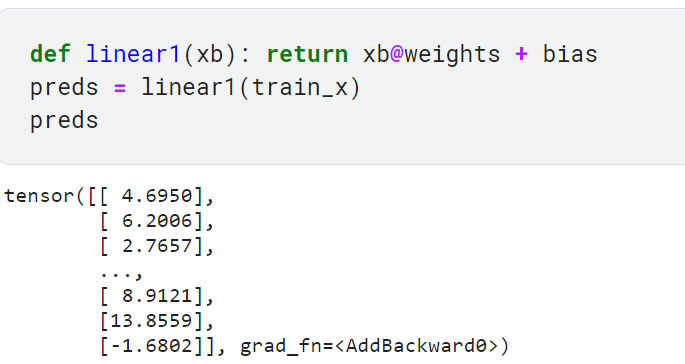
batch@weights+bias는 모든 신경망의 가장 기본인 두 방정식 중 하나임(다른 하나는 활성화 함수)
- 정확도 검사하기
예측이 숫자 3 또는 7인지를 판단하려면 출력값이 0.5보다 큰지를 검사해야 함.

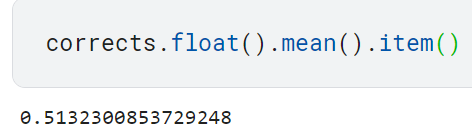
- 가중치 하나를 약간 바꿨을 때 정확도에 일어나는 변화 실험

- 손실 함수 예시 만들기

trgts: 타깃값. 3인 이미지는 1, 7인 이미지는 0임
prds: 예측값. 3에 가깝다고 판단하면 1에 가까운 값을, 7에 가깝다고 판단하면 0에 가까운 값을 받음
첫 번째 이미지는 3이기 때문에 0.9로 잘 예측했고, 두 번째 이미지는 7인데 0.4이니 약간의 신뢰도를 가지고 예측함. 마지막 이미지는 3인데 0.2로 틀리게 예측함.

손실함수. torch.where(a, b, c)는 [b[i] if a[i] else c[i] for i in range(len(a))] 형식의 리스트 컴프리헨션과 같은 작업 수행.
이 함수는 타깃값이 1일 때 예측이 1과 떨어진 정도를, 타깃값이 0일 때는 예측이 0과 떨어진 정도를 측정하고, 이렇게 구한 모든 거리의 평균을 구함.

위에서 만든 타깃값과 예측값을 torch.where 함수에 넣어서 계산. 이 함수는 정확한 예측의 신뢰도가 더 높을 때, 부정확한 예측의 신뢰도가 낮을 때 낮은 값을 반환함. 즉 손실 함수의 값이 낮을수록 좋음.
계산된 손실은 스칼라값이어야 하므로 mnist_loss 함수는 각 손실의 평균을 반환함.

- 시그모이드
mnist_loss는 예측이 항상 0과 1 사잇값이라고 가정함. 그렇다면 실제로도 값이 0과 1 사이가 되도록 강제하자.
이를 위해 항상 0과 1 사이의 숫자를 출력하는 시그모이드 함수 소개

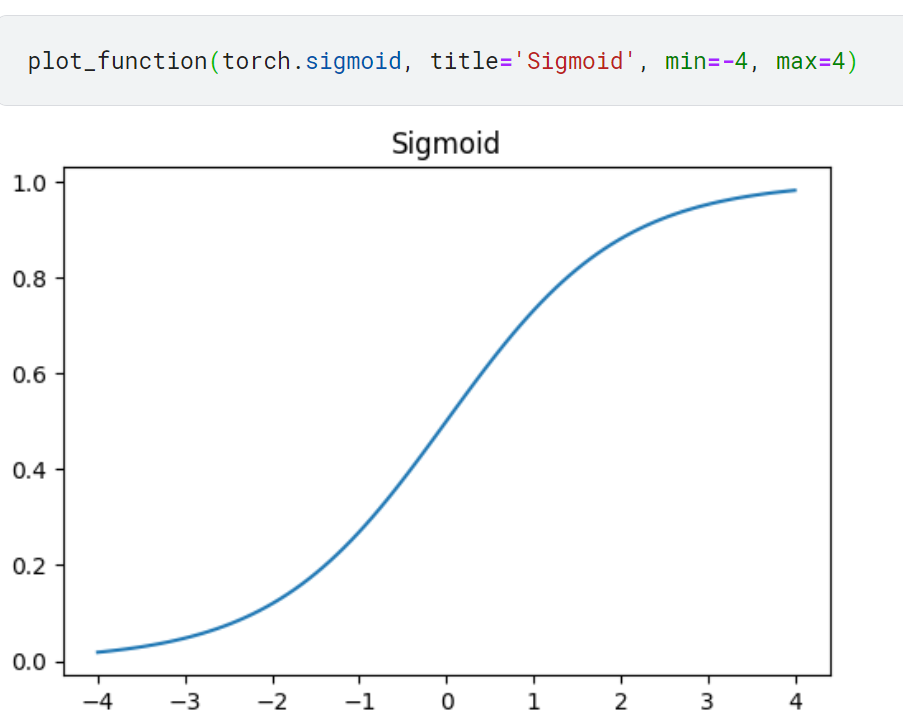
입력값은 음수부터 양수까지 제한이 없지만 출력값은 0과 1 사이임.

mnist_loss에서 예측값이 항상 0과 1 사이가 되도록 시그모이드 함수 적용하기
<손실 함수는 왜 필요할까?>
이미 정확도라는 평가지표가 있는데 왜 손실을 정의해야 할까?
평가지표는 사람의 이해를 돕고, 손실은 자동화된 학습을 이끌어간다는 점이 주된 차이임. 따라서 손실은 유의미한 미분이 있는 함수여야 함. 넓고 평평하거나 급작스러운 변화 구간이 있어선 안 되며 적당히 매끄러운 형태를 띠어야 함.
- SGD와 미니배치
미니배치학습: 한 번에 일정 개수의 데이터에 대한 손실의 평균 계산. 미니배치에 포함된 데이터 개수를 배치 크기(batch size)라고 함. 배치 크기가 클수록 손실 함수로 계산되는 그레이디언트가 더 정확하고 안정적으로 추정되지만 계산은 오래 걸림. 모델을 빠르고 정확히 학습시키는 적당한 배치 크기를 고를 수 있어야 함.
다양한 데이터로 학습을 시도하면 더 나은 일반화를 얻을 수 있음. 일반적으로 매 epoch에 순차적으로 데이터셋을 소비하는 단순한 방식 대신 미니배치가 생성되기 전에 임의로 데이터셋을 뒤섞는 방식을 사용. 파이토치와 fastai는 임의로 데이터셋을 뒤섞은 다음 미니배치를 만드는 DataLoader 클래스를 제공함.
DataLoader는 파이썬이 제공하는 모든 컬렉션을 주어진 배치 크기 단위로 분할된 여러 배치에 접근하는 반복자로 만듦
<DataLoader를 만드는 예시>

파이토치는 독립변수와 종속변수 쌍을 다루는 Dataset이라는 컬렉션 클래스를 제공함.
<Dataset 예시>

<DataLoader로 Dataset을 넣어서 배치 목록 얻기>

독립변수와 종속변수 쌍을 표현한 텐서의 배치 목록을 얻음
♣ 모든 것을 한 자리에!
- 파라미터 초기화


- DataLoader 생성하기(훈련용 데이터셋 이용)


- DataLoader 생성하기(검증용 데이터셋 이용)
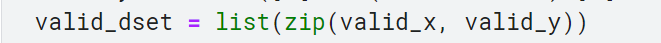

- 크기가 4인 미니배치를 만들어서 간단히 검사하기
- 그레이디언트 계산하기

- 지금까지의 내용을 하나로 정리하여 적용하기
- 한 epoch에서 수행되는 간단한 학습 루프 만들기

- 배치 단위의 평균 정확도를 계산하는 함수
검증용 데이터셋으로 정확도를 확인하여 학습이 얼마나 잘 이뤄지는지 확인


- 한 epoch 동안 모델을 학습시킨 다음 정확도가 개선되는지 확인하기

- epcoh를 여러 번 더 반복하기

- 옵티마이저 만들기
지금까지 작성한 기본 코드를 파이토치에서 제공하는 모듈로 대체해보자
<linear1 함수를 파이토치의 nn.Linear 모듈로 대체하기>
nn.Linear는 앞에서 만든 init_params 및 linear의 작동을 하나로 수행함. 단일 클래스 내에 가중치와 편향이 모두 저장됨.


앞절에서 만든 linear1 모델을 nn.Linear로 만들 수 있음

파이토치의 모든 모듈은 학습할 수 있는 파라미터의 존재를 자체적으로 알고 있음. parameters 메서드를 이용하면 파라미터 목록에 접근할 수 있음

위에서 접근한 파라미터 정보는 옵티마이저를 정의하는 데 활용할 수 있음

모델의 파라미터를 넣어서 옵티마이저 객체 생성

학습 루프 간소화

학습 루프 및 검증용 데이터셋의 정확도를 구하는 과정을 포함한 함수 정의


fastai가 제공하는 SGD 클래스는 방금 만든 BasicOptim 클래스와 정확히 같은 방식으로 작동함.
위랑 같은 과정을 거쳐보자.

fastai는 train_model 함수 대신 사용할 수 있는 Learner.fit도 제공함.
Learner.fit을 사용하려면 우선 Learner를 생성해야 함. 그리고 Learner를 생성하려면 DataLoaders를 만들어야 함.
DataLoaders는 학습용과 검증용 DataLoader에서 쉽게 생성 가능

vision_learner 같은 편리성 함수를 사용하지 않고 Learner를 생성하려면 이 장에서 만든 모든 요소를 Learner의 생성 인자로 전달해야 함. 즉, 기본적으로 DataLoaders, 모델, 최적화 함수(모델의 파라미터), 손실 함수가 지정되어야 하며 추가로 출력을 원하는 평가지표도 함께 지정 가능함.

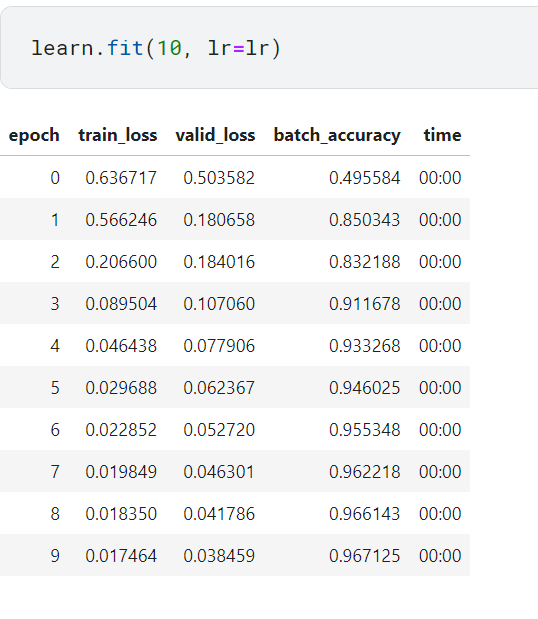
Learner 객체에 포함된 fit 메서드 호출하기
♣ 비선형성 추가
지금까지는 선형 분류 모델을 다루었으나 좀 더 복잡한 일을 다루기 위해서는 분류 모델을 복잡하게 바꿔야 함.
두 선형 분류 모델(계층) 사이에 비선형을 추가. 이 형태가 바로 신경망임.
간단하게 신경망을 정의한 코드

simple_net은 두 선형성과 그 사이에 존재하는 max 함수만으로 구성됨.
w1과 w2는 가중치 텐서이며, b1과 b2는 편향 텐서임. 이런 파라미터는 앞에서 배운 것처럼 임의로 초기화됨
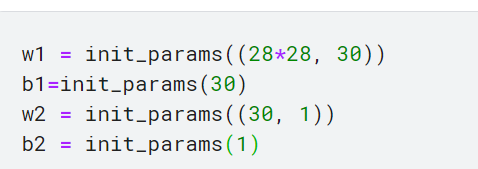
w1은 출력 활성이 30개 있음. w2는 w1과 맞물릴 수 있게 입력 활성이 30개임.
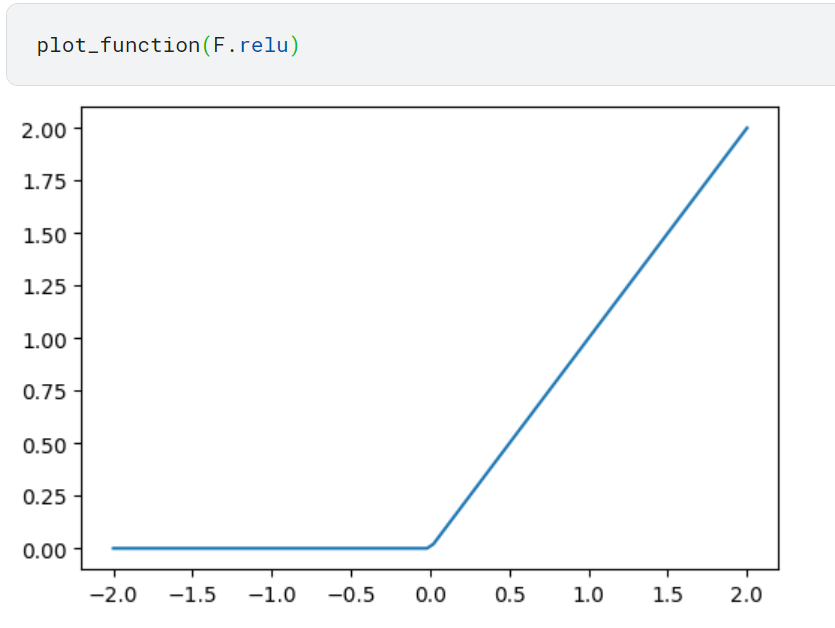
res.max(tensor(0.0)) 함수는 ReLU 라고도 알려져 있음. 모든 음숫값을 0으로 교체하는 함수(확률이 마이너스인 것은 의미가 없으니까). 파이토치에서는 이 함수를 F.relu로 제공함.
한 선형 계층 다음에 또 다른 선형 계층을 배치하는 것에는 큰 의미가 없음. 순차적으로 배치된 여러 선형 계층을 다른 종류의 파라미터로 구성된 하나의 선형 계층으로 대체할 수 있기 때문임.
하지만 선형 계층들 사이에 max와 같은 비선형 함수를 넣으면 각 선형 계층이 서로 분리되어 각각 자신만의 유용한 일을 할 수 있게 됨.
3개의 계층을 표현한 코드(첫 번째, 세 번째는 선형계층이며 두 번째는 비선형성 또는 활성화 함수임)

nn.Sequentail은 인자로 나열된 계층을 순차적으로 호출하는 모듈을 생성함.
nn.ReLU는 F.relu 함수와 정확히 같은 일을 하는 파이토치 모듈임.
모델에 포함될 수 있는 함수 대부분에는 같은 일을 하는 대응 모듈이 있음.
보통 F를 nn으로 바꾸고 일부 문자를 대문자로 바꿔서 대응 모듈을 찾을 수 있음.
nn.Sequential을 사용할 경우, 함수 대신 모듈을 사용해야 함. 그리고 모듈은 클래스이므로 상기 코드의 nn.ReLU() 처럼 인스턴스를 만들어야만 함.
nn.Sequential은 모듈이므로 파라미터를 관리함. 즉 nn.Sequentail에 포함된 모든 모듈에 있는 파라미터 목록을 얻을 수 있음.
linear보다 약간 더 깊은 모델을 만들었으니 학습률을 낮추고 epoch 횟수는 높여서 모델을 학습시키기
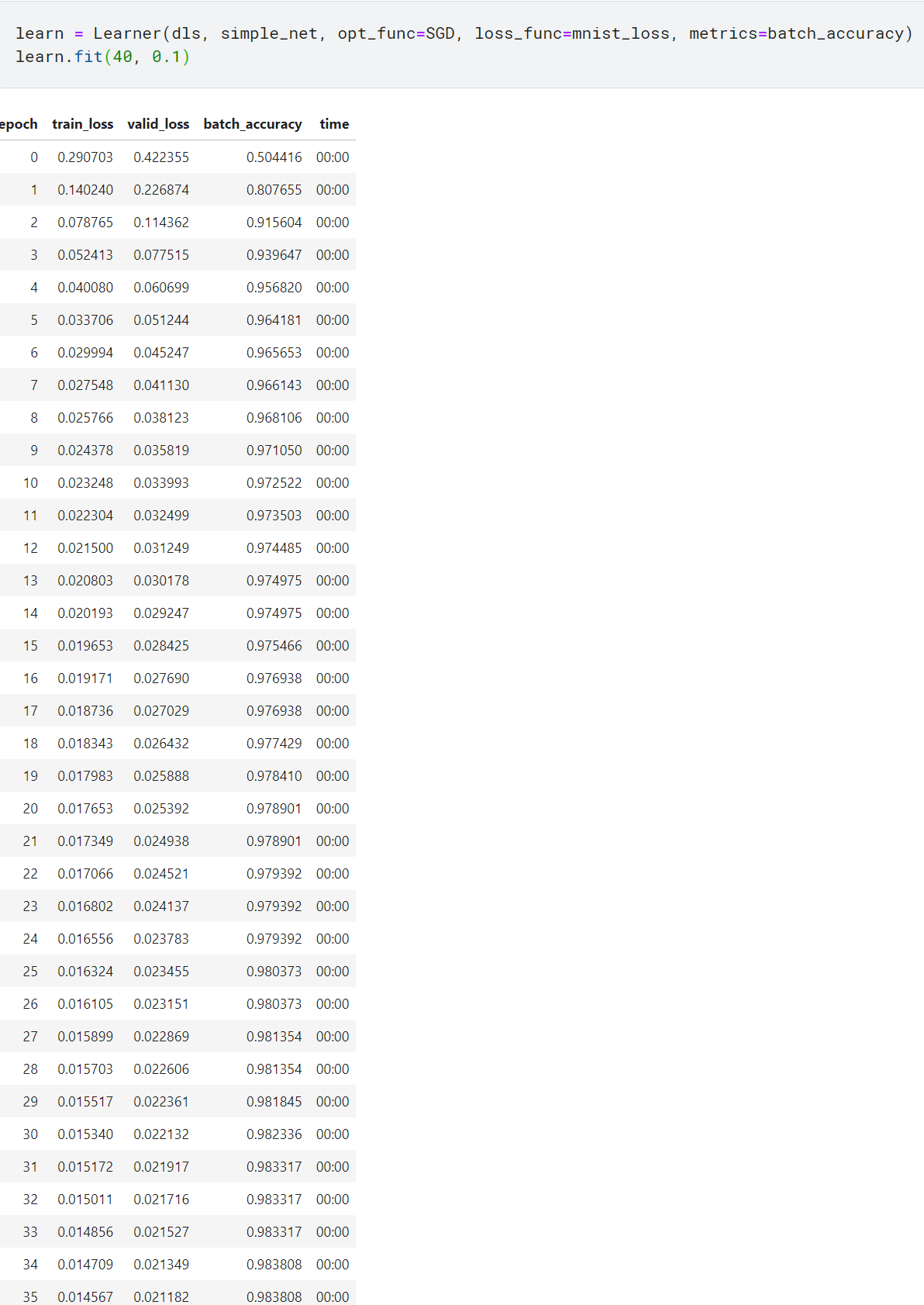
학습 과정은 learn.recorder에 기록됨. 위의 출력 결과를 담은 테이블은 values 속성에 저장됨. 이 속성값에 접근하여 학습 과정에 따른 정확도 그래프 그리기

마지막에 기록된 정확도를 출력할 수도 있음

♣ 해당 코드
https://www.kaggle.com/code/polljjaks/handwriting/edit/run/154995400
handwriting
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com
'딥러닝 모델: fastai' 카테고리의 다른 글
| Chapter 6. 그 밖의 영상 처리 문제 (0) | 2024.01.07 |
|---|---|
| Chapter 5. 반려동물의 품종 분류하기 (0) | 2023.12.17 |
| 이미지 분류 연습하기 (0) | 2023.12.04 |
| fastai 라이브러리 (0) | 2023.08.15 |
| DataLoader 만들기 비교 (0) | 2023.08.10 |