2024. 1. 22. 20:20ㆍ딥러닝 모델: fastai
♣ 데이터 확인하기

u.data 파일에 기본 테이블이 있음. u.data는 탭 문자로 구분된 문서형식에 기반한 사용자, 영화, 영화평점, 타임스탬프 열로 구성됨.
영화의 정보와 사용자의 정보를 조합하여 사용자가 아직 보지 않은 영화를 보았을 때 어떤 점수를 매길지 예측할 수 있음.
예시) 영화: 스타워즈 시리즈(SF, 액션, 고전 요소 표현) / 사용자(SF, 액션, 고전으로 각 요소별 선호하는 정도)
* 노란색 = SF, 파란색 = 액션, 붉은색= 고전
둘 조합에서 유사성 계산하기
두 벡터를 곱한 결과를 모두 더하는 연산을 점곱(dot product)이라고 함.
예시) 영화: 카사블랑카(SF, 액션, 고전 요소 표현) / 사용자(SF, 액션, 고전으로 각 요소별 선호하는 정도)
이렇듯 SF, 액션, 고전 영화 등을 나타내는 요소의 값을 '잠재 요소'라고 함.
♣ 잠재 요소 학습하기
- 1단계: 일부 파라미터를 임의로 초기화하기
이 파라미터들은 각 사용자와 영화의 일련의 잠재요소가 됨. 원하는 잠재요소의 개수는 사용자가 결정함.
- 2단계: 예측을 계산하기
각 사용자와 영화 간의 점곱을 구함. 예를 들어 사용자의 첫 번째 잠재요소는 사용자가 액션 영화를 좋아하는 정도를 표현하며, 영화의 첫 번째 잠재요소는 영화에 액션이 많은지를 표현함. 사용자가 액션 영화를 좋아하면서 동시에 영화에 액션이 많거나, 사용자가 액션 영화를 좋아하지 않는 동시에 영화에 액션이 많지 않다면 점곱의 결과가 클 것.
- 3단계: 손실 계산하기
어떤 손실 함수를 사용해도 되지만 여기서는 예측의 정확성을 합리적으로 나타내는 평균제곱오차 선택
이제 확률적 경사 하강법을 파라미터(잠재 요소)를 최적화할 수 있음. 확률적 경사 하강법을 수행하는 옵티마이저는 각 영화와 사용자 간의 매칭을 점곱으로 계산하고, 계산한 수치를 각 사용자가 각 영화에 부여한 실제 점수와 비교해 손실을 계산함. 그러면 해당 손실에 대한 미분을 계산할 수 있으며 학습률을 곱하여 가중치를 한 단계 조정해나갈 수 있음. 이 작업을 여러 번 수행하면 손실이 점점 좋아지고 추천 점수도 점점 더 정확해질 것임.
♣ DataLoaders 만들기
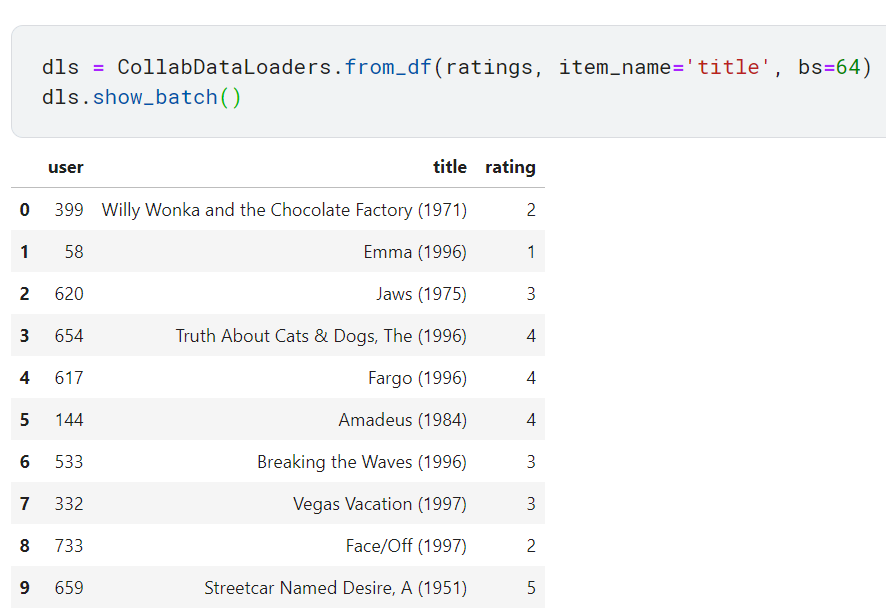
각 영화 ID에 대응하는 제목 정보 알아보기
'|'를 기준으로 잘랐을 때 0번째 col이 숫자이고, 이를 movie column에 넣음. 첫 번째 col은 영화 이름이고, 이를 title column에 넣음.
ratings 테이블과 movies 테이블 결합하기
이렇게 만든 테이블로 DataLoaders 객체를 구축할 수 있음. 협업 필터링에 특화된 DataLoaders 객체인 CollabDataLoaders는 첫 번재 열을 사용자, 두 번째 열을 항목(여기서는 영화), 세 번째 열을 점수로 사용하는 기본 작동 양식을 따름. 하지만 여기서는 영화 ID 대신 제목으로 항목을 가리키려고 함. item_name 인자에 항목으로 쓸 열의 이름을 지정해주면 됨.
*CollabDataLoaders
collabDataLoaders는 협업 필터링(Collaborative Filtering)과 관련된 데이터셋을 로드하고 데이터로더를 생성하는 데 사용됨. 협업 필터링은 사용자 간 또는 상품 간의 상호 작용을 기반으로 추천을 수행하는 기술 중 하나임. 주로 영화 추천과 같은 분야에서 많이 사용됨.
♣ 잠재요소 학습하기-초기 파라미터 설정하기

- n_users: 데이터로더에서 사용자 ID에 대한 클래스 수를 가져와서 사용자 수를 결정함
- n_movies: 데이터로더에서 영화 제목에 대한 클래스 수를 가져와서 영화 수를 결정함
- n_factors: 잠재요소 학습하기 1단계에서 나왔던 것처럼, 잠재 요소의 수를 나타내는 변수. 잠재 요소는 사용자와 영화의 특성을 나타내는데 사용되는 숨겨진 차원임. 여기서는 각 사용자 및 각 영화에 대해 5개의 잠재 요소를 사용함.
- user_factors = torch.randn(n_users, n_factors): 사용자 잠재 요소 행렬을 랜덤한 값으로 초기화함. 이 행렬은 사용자의 특성을 나타내며 크기는 (사용자 수, 잠재 요소 수)임. 사용자의 수(n_users)가 944명이므로 이 행렬의 길이도 944임.

- movie_factors = torch.randn(n_movies, n_factors): 영화 잠재 요소 행렬을 랜덤한 값으로 초기화함. 이 행렬은 영화의 특성을 나타내며 크기는 (영화 수, 잠재 요소 수)임. 영화 수(n_movies)가 1665이므로 이 행렬의 길이도 1665임

특정 영화와 사용자 조합에 대한 결과를 계산하려면 영화 및 사용자용 잠재 요소 행렬 중 해당 영화와 사용자에 대한 부분을 색인에서 찾아야만 함. 데이터프레임이나 행렬에서의 색인은 특정 행(row)이나 열(column)을 선택하는 데 사용됨. 즉, 특정 영화와 사용자에 대한 잠재 요소를 가져오기 위해서는 해당 영화와 사용자에 대한 행렬의 특정 행을 선택하는 것이 필요하다는 의미임.
예를 들어 user1과 영화 Inception 에 대한 잠재 요소를 얻고 싶다면 아래와 같이 색인을 이용할 수 있음.
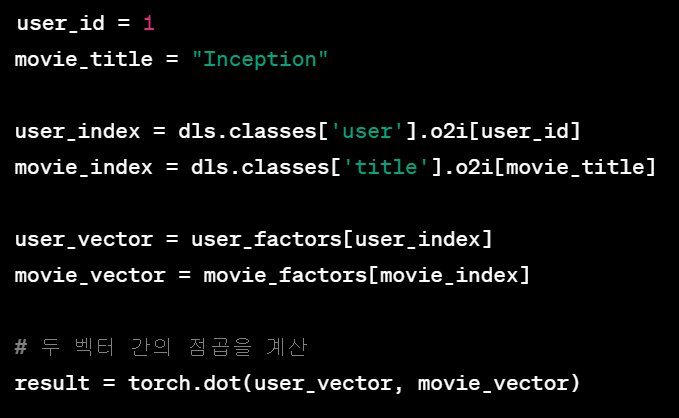
dls.classes['user'].o2i 및 dls.classes['title'].o2i는 각각 사용자 및 영화의 이름을 인덱스로 변환하는 매핑을 나타냄. 즉 사용자의 index와 영화의 index(색인)를 얻을 수 있음. 그런 다음 이러한 인덱스를 사용하여 잠재 요소 행렬에서 해당 사용자 및 영화의 행을 선택하고, 선택된 두 벡터 간의 점곱을 계산하여 결과를 얻을 수 있음.
* 사용자의 one-hot 인코딩을 생성하고, 해당 사용자에 대한 잠재 요소를 추출하는 연산을 수행하기

- one_hot_3 = one_hot(3, n_users).float(): one_hot 함수를 사용하여 사용자 ID가 3인 사용자에 대한 one-hot 인코딩 생성

944명의 사용자 중 3에 해당하는 사용자를 원-핫 인코딩으로 표현하므로 index 3에 해당하는 숫자만 1이고 나머지는 모두 0임.
-user_factors.t(): 사용자 잠재 요소 행렬을 전치(transpose)한 것. 이렇게 하면 각 행이 사용자 대신 잠재 요소에 대응하게 됨. 그런 다음 @ 연산자를 사용하여 이를 one-hot 벡터와 행렬 곱셈을 수행함.
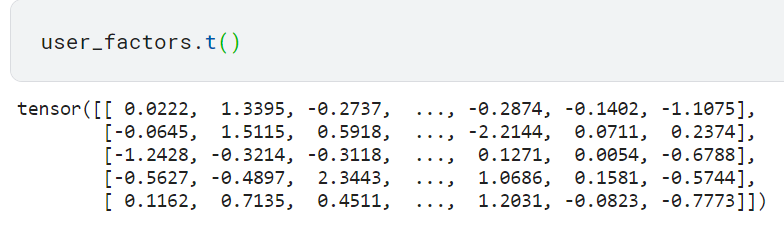
이 결과는 행렬의 세 번째 index에 해당하는 벡터와 같음.

왜냐하면 원-핫 인코딩한 사용자에서 세 번째에만 1이 들어갔는데 이를 user_factors.t()와 행렬곱하면 다섯 개 리스트에서 세 번째 값들만 나오게 되니까, 결국 이 값들이 user_factors[3]과 같음.
♣ 임베딩
딥러닝에서 범주형 데이터를 실수 벡터로 매핑하는 과정. 범주형 데이터는 예를 들어 텍스트, 카테고리, 태그, 사용자 ID, 아이템 ID 등과 같이 이산적인 값을 갖는 데이터를 의미함. 임베딩은 이러한 이산적인 값을 연속적인 실수 공간으로 변환하여 모델이 이해하고 학습할 수 있도록 돕는 역할을 함.
임베딩은 모델이 범주형 데이터에 대한 특성을 자동으로 학습하는 과정 중에 사용되며, 이를 통해 모델은 데이터의 패턴 및 관계를 더 잘 파악할 수 있게 됨. 초기에는 주로 랜덤한 값으로 초기화되지만 모델이 학습되면서 데이터에 적응하여 최적의 표현을 찾음.
♣ 밑바닥부터 만드는 협업 필터링
새로운 파이토치 모듈 만들기(모델의 구조 정의하기)

* Embedding은 딥러닝에서 사용자가 정의한 정수 기반의 인덱스를 실수 벡터로 매핑하는데 사용되는 층(layer)입니다. 이 층은 범주형 데이터를 효과적으로 신경망에 입력하기 위해 사용됩니다. Embedding 층은 주어진 정수 인덱스에 해당하는 벡터를 찾아 반환합니다. 이러한 벡터는 모델이 훈련되면서 학습되는 파라미터로, 모델은 주어진 인덱스에 해당하는 벡터를 학습하여 입력과 출력 간의 관계를 파악하게 됩니다.
Embedding 층의 구성

- num_embeddings: 총 인덱스의 개수, 즉 몇 개의 고유한 범주가 있는지를 나타냅니다.
- embedding_dim: 각 인덱스에 대해 할당된 임베딩 벡터의 차원입니다.
- padding_idx: 선택적으로 사용할 수 있는 매개변수로, 패딩에 사용되는 인덱스를 지정합니다.
따라서 주어진 코드에서 Embedding은 사용자와 영화에 대한 임베딩을 학습하는 역할을 합니다. n_users와 n_movies는 각각 사용자와 영화의 총 인덱스 개수이며, n_factors는 임베딩 벡터의 차원입니다. 각 사용자와 영화에 대한 인덱스에 해당하는 임베딩 벡터는 모델이 학습 중에 조정됩니다.
dls의 입력값과 타깃값 확인하기

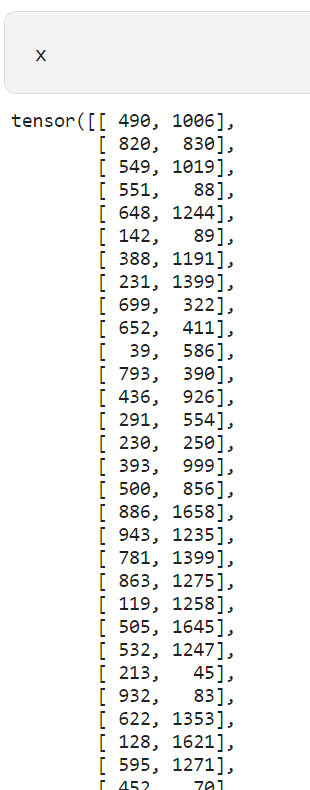
입력값인 x는 사용자 ID와 영화 ID이다. 타깃값 y는 영화 평점인 rating이다.

모델을 최적화할 Learner 만들기
이전에는 특정 애플리케이션의 모든 것을 설정하는 vision_learner 같은 특별하게 제작된 함수를 사용함. 하지만 여기서는 밑바닥부터 만들 목적이므로, 범용적으로 활용할 수 있는 Learner 클래스를 사용함.

모델 학습시키기

모델 개선하기
1. rating 예측 범위가 0~5.5가 되도록 강제하기: sigmoid_range 함수 사용

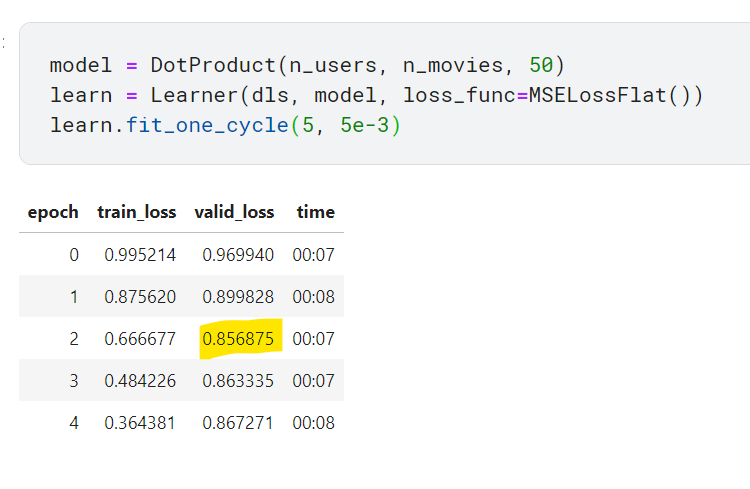
valid_loss가 작아지다가 다시 커지기 시작. 과적합의 신호로 보임.
편향 추가하기

forward 메서드:
- 입력 x로부터 사용자와 영화에 대한 임베딩을 가져옵니다.
- users와 movies는 각각 사용자와 영화에 대한 임베딩 벡터입니다.
- 편향은 각 사용자와 각 영화에 대한 편향을 고려합니다.
- (users * movies).sum(dim=1, keepdim=True): 사용자와 영화 간의 상호 작용을 계산합니다. 이 부분은 사용자와 영화에 대한 가중치를 이용한 내적(점곱) 계산입니다.
- 여기서 keepdim=True는 sum 연산을 수행할 때 결과 텐서의 차원을 원본 입력 텐서와 동일하게 유지하도록 지정합니다. 다시 말해, 연산 후에도 원본 텐서와 동일한 차원 수를 유지하며, 차원의 크기가 1로 변경됩니다.
- self.user_bias(x[:, 0]) + self.movie_bias(x[:, 1]): 사용자와 영화에 대한 편향을 더합니다.
- 최종적으로 sigmoid_range 함수를 사용하여 출력값을 지정된 범위 내로 조정합니다.

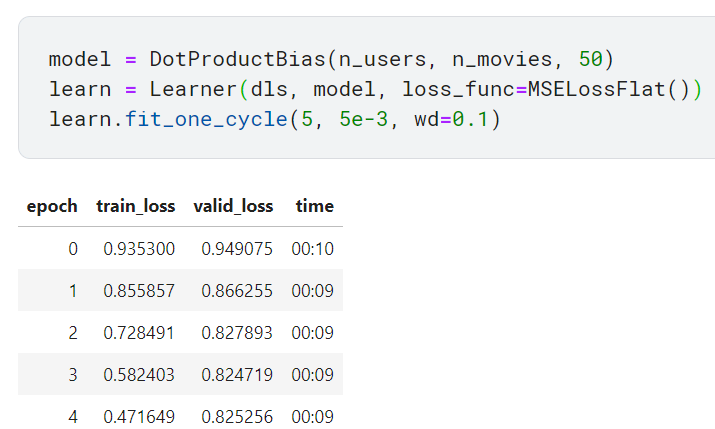
편향을 추가하자 valid_loss가 오히려 나빠짐. 과적합 때문인 것으로 보임. 과적합을 줄이기 위해 '가중치 감쇠' 사용
가중치 감쇠 사용하기(weight decay)
가중치 감쇠란 학습 과정에서 큰 가중치에 대해서는 그에 상응하는 페널티를 부과해서 과적합을 억제하는 것을 의미함.
가중치 감쇠(L2 정규화)는 손실 함수에 모든 가중치 제곱의 합을 더하는 것으로 구성됨. 이유는 과적합은 가중치 매개변수의 값이 커서 발생하는 경우가 많기 때문임. 모델이 높은 값의 파라미터(가중치)를 학습하게 두면 변화가 매우 심해서 너무 복잡한 함수로 학습용 데이터셋의 모든 데이터에 적합하게 되어버림. 가중치가 너무 커지지 않도록 제한하게 되면 모델의 학습을 방해하지만, 일반화가 더 잘 되는 상태가 됨. 따라서 그레이디언트 계산 시 가중치를 가능한 작게 만드는 것이 목표임.
가중치를 W라 하면 *L2 노름에 따른 가중치 감소는

가 되고 이 값을 손실 함수에 더한다. 여기에서 람다는 정규화의 세기를 조절하는 하이퍼파라미터다.
람다를 크게 할수록 큰 가중치에 대한 페널티가 커진다. 1/2는 위의 식의 미분 결과
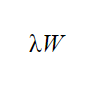
를 조정하는 상수이다.
가중치 감소는 모든 가중치 각각의 손실 함수에

을 더한다. 따라서 가중치의 기울기를 구하는 계산에서는 오차역전파법에 따른 정규화 항을 미분한
를 더한다.
* L2 노름은 각 원소의 제곱들을 더한 것에 해당한다.

fastai에서 가중치 감쇠를 사용하려면 fit 또는 fit_one_cycle 메서드 호출 시 wd 인자를 사용하면 됨

나만의 임베딩 모듈 만들기
지금까지는 실제 작동 방식을 크게 신경 쓰지 않고 Embedding을 사용했음. 이번에는 Embedding 클
래스 없이 이를 대체하는 DotProductBias를 직접 만들어서 사용.
1. 각 임베딩의 가중치 행렬 임의로 초기화하기
옵티마이저는 모듈의 parameters 메서드로 모든 파라미터를 가져올 수 있음. 하지만 모듈의 속성으로 텐서를 추가했을 때는 이 값이 parameters 메서드가 반환하는 파라미터 그룹에 자동으로 포함되지는 않음.

위의 클래스를 보면 파라미터 a를 설정했지만 파라미터 메서드를 반환했을 때 a는 존재하지 않음.
텐서를 모듈의 파라미터로 추가하려면 nn.Parameter 클래스로 래핑(wrap)해야만 함. nn.Parameter 클래스는 자동으로 requires_grad_ 메서드를 호출할 뿐, 다른 어떤 기능도 추가하지 않지만 parameters에 포함될 대상을 표시하는 마커(marker)로 사용함. 즉 nn.Parameter를 사용하여 파라미터를 설정하면 이 파라미터에 마커가 표시되어서 parameters에 포함됨.

모든 파이토치 모듈은 학습 가능한 파라미터에 nn.Parameter를 사용했기 때문에 지금까지 nn.Parameter 클래스를 명시적으로 사용할 필요가 없었음. 아래는 nn.Parameter 클래스를 명시적으로 사용하지 않은 예시임.

위의 모듈에서는 nn.Linear 클래스의 인스턴스를 생성하면서 가중치를 생성함. 명시적으로 nn.Parameter 클래스로 가중치를 감싸지 않았지만 nn.Linear 클래스는 내부적으로 가중치(weight) 매개변수를 생성할 때 nn.Parameter를 사용함. 따라서 parameters에 해당 가중치가 포함됨.

a의 가중치가 nn.parameter.Parameter 클래스의 인스턴스임을 확인.
하지만 아래와 같이 명시적으로 임의 초기화된 텐서를 파라미터로 생성할 수도 있음.

- *size: 주어진 크기에 맞게 텐서 생성
- normal_(0, 0.01): 텐서는 평균이 0, 표준편차가 0.01인 정규분포로 초기화됨
위의 파라미터 생성 함수를 이용하여 DotProductBias를 다시 만든다.
2. 초기화된 가중치를 이용하여 모듈 만들기
위에서 정의한 create_params 함수를 이용하면 아래처럼 파라미터를 만들 수 있음(n_factors=5 일 때)


♣ 임베딩과 편향의 분석
모델에서 사용하는 파라미터를 확인할 수 있음. 가장 해석이 쉬운 파라미터는 편향임.
가장 낮은 편향 벡터 값을 가지는 영화 목록 확인하기

가장 높은 편향 벡터 값을 가지는 영화 목록 확인하기

임베딩 행렬을 즉시 해석하기는 어렵지만 가장 중요한 방향성을 추출하는 주성분 분석(Principal Component Analysis, PCA) 라는 기법이 있음.
♣ fastai로 따라하기
위처럼 밑바닥부터 정의한 모델을 fastai로 구현해보자
fastai의 collab_learner 함수를 사용하면 앞에서와 정확히 같은 구조로 협업 필터링 모델을 만들고 학습시킬 수 있음

모델을 출력하여 포함된 계층들의 이름 확인하기
Embedding 층은 범주형 변수의 잠재적 특징을 포착하는 저차원 표현이다.

- Embedding(944, 50): 사용자 가중치. 994개의 고유한 임베딩을 가지고 있음.
- Embedding(1635, 30): 영화 가중치. 1635개의 고유한 임베딩을 가지고 있음.
- Embedding(944, 1): 사용자 편향
- Embedding(1635, 1): 영화 편향
편향 분석하기

- learn.model.i_bias.weight.squeeze(): 항목(영화) 편향 임베딩 값을 추출함. 각 값은 해당 영화에 대한 편향을 나타냄
♣ 임베딩 거리
만약 매우 비슷한 영화 두 개가 있다면 두 영화를 좋아하는 사용자도 매우 비슷할 것. 따라서 두 영화의 임베딩 벡터도 매우 비슷해야 함.
=> 영화 간 유사성은 대상 영화들을 좋아하는 사용자 간의 유사성으로 정의할 수 있음. 이는 두 영화의 임베딩 벡터 간의 거리가 직접적으로 유사성을 정의할 수 있음을 의미함.
위의 임베딩 거리 유사성 개념을 활용하여 <양들의 침묵>과 가장 유사한 영화 찾기

- model.i_weight.weight: 항목(영화)의 가중치 요소 추출

- o2i: 해당 영화의 인덱스를 추출하는 함수
- CosineSimilarity: 코사인 유사도 계산. distances는 모든 영화와 '양들의 침묵' 간의 코사인 유사도를 나타내는 텐서임

- distances.argsort(descending=True)[1]: 위에서 구한 유사도에서 유사도가 높은 순서대로 배열해서 그 중 첫 번째 요소가 '양들의 침묵'과 가장 비슷한 가중치를 가진 영화이다.

0번째 영화는 '양들의 침묵' 자기 자신이므로 0번째가 아니라 첫 번째 영화를 골라야 한다.

♣ 협업 필터링을 위한 딥러닝
모델의 구조를 딥러닝으로 전환하는 첫 번째 단계는 임베딩 조회 결과를 활성에 연결하는 것. 이 단계를 거치면 일반적인 방식으로 선형 계층 및 비선형 활성화 함수에 입력할 수 있는 행렬이 만들어짐.
점곱을 계싼하지 않고 임베딩 행렬을 이어 붙이므로 두 임베딩 행렬의 크기가 다를 수 있음. fastai는 주어진 데이터를 위한 임베딩 행렬에 권장되는 크기를 반환하는 get_emb_sz 함수를 제공함.

협업 필터링을 위한 딥러닝 모델 구현

구현한 클래스와 권장된 임베딩 행렬의 크기로 모델 생성

CollabNN은 앞서 만든 클래스와 같은 방식으로 Embedding 계층을 생성함. forward 메서드에서는 임베딩을 적용하고, 적용된 결과를 이어 붙인 다음 신경망에 전달함. 마지막에서는 앞서 만든 모델과 마찬가지고 sigmoid_range 함수를 적용함.
학습시키기

collab_learner 함수를 이용하여 CollabNN 모델과 같이 학습시키기
collab_learner 함수를 호출할 때 use_nn=True 인잣값을 넘겨주면 fastai의 fastai.collab이 제공하는 CollabNN과 같은 모델을 사용할 수 있음(내부적으로 get_emb_sz가 자동으로 호출됨). 또한 계층을 더 많이 쌓아올리는 간편한 방법을 제공함.

♣ 참고 자료
임베딩
Pytorch - embedding
임베딩 (Embedding) 이라는 말은 자연어처리 분야에서 (NLP) 매우 많이 등장하는 단어로 이산적, 범주형인 변수를 sparse한 one-hot 인코딩 대신 연속적인 값을 가지는 벡터로 표현하는 방법을 말합니다.
hongl.tistory.com
임베딩 계층
12-09 파이토치(PyTorch)의 nn.Embedding()
파이토치에서는 임베딩 벡터를 사용하는 방법이 크게 두 가지가 있습니다. 바로 임베딩 층(embedding layer)을 만들어 훈련 데이터로부터 처음부터 임베딩 벡터를 학습하는 …
wikidocs.net
가중치 감쇠
https://m.blog.naver.com/fbfbf1/222426175698
[DNN] 오버피팅(overfitting), 가중치 감소(weight decay), 드롭아웃(Dropout), 하이퍼파라미터
밑바닥부터 시작하는 딥러닝 책을 보고 혼자 정리한 내용입니다. 기계학습에서는 오버피팅이 문제가 되는 ...
blog.naver.com
'딥러닝 모델: fastai' 카테고리의 다른 글
| Chapter7. 최신 모델의 학습 방법 (0) | 2024.01.17 |
|---|---|
| Chapter 6. 그 밖의 영상 처리 문제 (0) | 2024.01.07 |
| Chapter 5. 반려동물의 품종 분류하기 (0) | 2023.12.17 |
| chapter4. 숫자 분류기 예시(숫자 3과 7의 손글씨 이미지 분류) (1) | 2023.12.08 |
| 이미지 분류 연습하기 (0) | 2023.12.04 |