2024. 2. 21. 21:44ㆍ딥러닝 모델: 파이토치
♣ 미니배치와 배치 크기
앞에서 배운 선형회귀에서는 데이터의 양이 굉장히 적었다. 만약 데이터가 수십만개 이상이라면 전체 데이터에 대해서 경사 하강법을 수행하는 것은 매우 느릴 뿐 아니라 많은 계산량이 필요하다. 메모리의 한계로 계산이 불가능한 경우도 생긴다. 그렇기 때문에 전체 데이터를 더 작은 단위로 나누어서 해당 단위로 학습하는 개념이 등장하였는데, 이 단위를 미니 배치(Mini Batch)라고 한다.

위의 그림은 전체 데이터를 미니 배치 단위로 나누는 것을 보여준다. 미니 배치 학습을 하게 되면 미니 배치만큼만 가져가서 미니 배치에 대한 비용(cost)를 계산하고, 경사 하강법을 수행한다. 그리고 다음 미니 배치를 가져가서 경사 하강법을 수행하고, 마지막 미니 배치까지 이를 반복한다. 이렇게 전체 데이터에 대한 학습이 1회 끝나면 1 epoch가 끝나게 된다.
epoch는 전체 훈련 데이터가 학습에 한 번 사용된 주기를 의미한다.
미니배치 학습에서는 미니배치의 개수만큼 경사하강법을 수행해야 전체 데이터가 한 번 전부 사용되어 1 epoch가 된다.
미니배치의 개수는 미니배치의 크기를 몇으로 하느냐에 따라서 달라지는데 미니배치의 크기를 배치 크기(batch size)라고 한다.
전체 데이터에 대해서 한 번에 경사하강법을 수행하는 방법을 '배치 경사 하강법'이라고 부른다.
반면, 미니배치 단위로 경사하강법을 수행하는 방법을 '미니배치 경사하강법' 이라고 부른다.
- 배치 경사하강법은 경사하강법을 할 때 전체 데이터를 사용하므로 가중치 값이 최적값에 수렴하는 과정이 매우 안정적이지만 계산량이 너무 많이 든다.
- 미니배치 경사하강법은 경사하강법을 할 때 전체 데이터의 일부만을 보고 수행하므로 최적값으로 수렴하는 과정에서 값이 조금 헤매기도 하지만 훈련 속도가 빠르다.
- 배치 크기는 보통 2의 제곱수를 사용한다(2, 4, 8, 16, 32...) 그 이유는 CPU와 GPU의 메모리가 2의 배수이므로 배치크기가 2의 제곱수일 때 데이터 송수신의 효율을 높일 수 있기 때문이다.
♣ 이터레이션

위의 그림은 epoch와 배치크기, 이터레이션의 관계를 보여준다. 이터레이션은 한 번의 epoch 내에서 이뤄지는 매개변수인 가중치 W와 b의 업데이트 횟수이다. 전체 데이터가 2000일 때 배치 크기를 200으로 한다면 이터레이션의 수는 총 10개이다. 즉 한 번의 epoch 당 매개변수 업데이트가 10번 이루어진다는 것을 의미한다.
♣ 데이터 로드하기(Data Load)
파이토치에서는 데이터를 좀 더 쉽게 다룰 수 있는 도구로서 데이터셋(Dataset)과 데이터로더(DataLoader)를 제공한다. 이를 사용하면 미니배치 학습, 데이터 셔플, 병렬 처리까지 간단히 수행할 수 있다.
- Dataset(torch.utils..data.Dataset): mini-batch를 구성할 각 data sample을 하나씩 불러오는 기능 수행
- DataLoader(torch.utils.data.DataLoader): Dataset에서 불러온 각 data sample들을 모아서 mini-batch로 구성하는 기능 수행. Data sample 들을 병렬적으로 불러오고 데이터 셔플 등의 작업을 간단하게 수행할 수 있음.
기본적인 사용 방법은 Dataset을 정의하고, 이를 DataLoader에 전달하는 것이다.
텐서를 입력받아 Dataset의 형태로 변환하는 TensorDataset을 사용해보자. TensorDataset은 텐서를 감싸는 Dataset이다. 길이와 인덱싱 방식을 정의함으로써 텐서의 첫 번째 차원을 따라서 반복, 인덱싱 및 슬라이스하는 방법도 제공한다.
1. Dataset과 DataLoader 임포트하기

2. 텐서 형태로 데이터 정의하기(TensorDataset은 기본적으로 텐서를 입력으로 받는다.)

3. 위의 데이터를 TensorDataset의 입력으로 사용하여 dataset 저장하기

dataset을 사용하지 않으면 data sample을 하나씩 불러오기 위해 아래와 같은 미니 배치를 별도로 반복해야 한다.

이제는 dataset을 사용하여 x와 y를 동시에 가져올 수 있다.
4. DataLoader 만들기
파이토치의 데이터셋을 만들었다면 데이터로더를 사용할 수 있다. 데이터로더는 기본적으로 두 개의 인자를 받는다.
데이터셋과 미니배치의 크기이다. 추가적으로 많이 사용되는 인자로 shuffle이 있다. shuffle=True를 선택하면 epoch 마다 데이터셋을 섞어서 데이터가 학습되는 순서를 바꾼다. 모델이 데이터셋의 순서에 익숙해지는 것을 방지하기 위해shuffle=True 옵션을 주는 것을 권장한다.
dataset에서 가져온 datasample을 dataset[i*bs : i*bs+bs]를 사용하여 미니배치를 구성하는 대신 DataLoader는 미니배치를 자동적으로 제공한다. (이 내용이 헷갈리면 참고자료 2번을 보시오)

5. 모델과 옵티마이저 설계하기

6. 훈련하기

위의 코드를 보면 batch_idx, samples가 나온다. 이 값들을 확인해보자
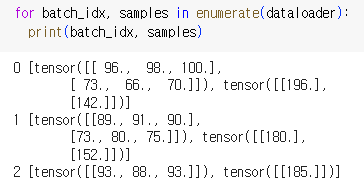
dataloader를 만들 때 batch_size=2였으므로 데이터가 두 개씩 묶여서 하나의 미니배치가 되었다. 여기서 입력값은 x_train에, 출력값은 y_train에 할당된다.
epoch를 20번 실행한다는 것은 3조각으로 잘린(2, 2, 1) 미니배치를 총 20번 학습한다는 의미이다.

따라서 한 번의 epoch 당 3번의 출력이 나온다.
학습 결과를 보면 cost의 값이 점차 작아진다. epoch를 더 늘려서 훈련하면 cost의 값이 더 작아질 수도 있다.
* 파이토치 가이드에서의 다른 예시


여기서는 epoch를 돌릴 때 batch_idx와 samples를 가져오지 않고 xb, yb만 직접 가지고 왔다.
7. 임의의 값을 넣어 예측값 확인하기

♣ 참고 자료
03-06 미니 배치와 데이터 로드(Mini Batch and Data Load)
이번 챕터에서 배우는 내용은 선형 회귀에 한정되는 내용은 아닙니다. 이번 챕터에서는 데이터를 로드하는 방법과 미니 배치 경사 하강법(Minibatch Gradient Descen…
wikidocs.net
https://tutorials.pytorch.kr/beginner/nn_tutorial.html
torch.nn 이 실제로 무엇인가요?
저자: Jeremy Howard, fast.ai. Rachel Thomas, Francisco Ingham에 감사합니다. 번역: 남상호 이 튜토리얼을 스크립트가 아닌 노트북으로 실행하기를 권장합니다. 노트북 (.ipynb) 파일을 다운 받으시려면, 페이지
tutorials.pytorch.kr
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(03-08. 벡터와 행렬 연산 복습하기) (0) | 2024.02.24 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(03-07. 커스텀 데이터셋, transform 약간, ToTensor) (0) | 2024.02.24 |
| Pytorch로 시작하는 딥러닝 입문(03-05. 클래스로 파이토치 모델 구현하기) (0) | 2024.02.21 |
| Pytorch로 시작하는 딥러닝 입문(03-04 nn.Module로 구현하는 선형 회귀: 다중선형회귀) (0) | 2024.02.14 |
| Pytorch로 시작하는 딥러닝 입문(03-04 nn.Module로 구현하는 선형 회귀: 단순선형회귀, optimizer) (0) | 2024.02.14 |