2024. 2. 24. 10:14ㆍ딥러닝 모델: 파이토치
앞서 독립 변수 x가 2개 이상인 다중 선형 회귀를 배웠다. 이후에 배우게 될 실습인 소프트맥스 회귀에서는 종속 변수 y의 종류도 3개 이상이 되면서 더욱 복잡해졌다. 그리고 이러한 식들이 겹겹이 누적되면 인공 신경망의 개념이 된다.
사용자는 데이터와 변수의 개수로부터 행렬의 크기, 더 나아가 텐서의 크기를 산정할 수 있어야 한다.
♣ 벡터와 행렬과 텐서
벡터는 크기와 방향을 가지는 양이다. 숫자가 나열된 형상이며 파이썬에서는 1차원 배열 또는 리스트로 표현한다.
행렬은 행과 열을 가지는 2차원 형상의 구조이다. 파이썬에서는 2차원 배열로 표현한다. 가로줄을 행(row), 세로줄을 열(column)이라고 한다.
3차원부터는 주로 텐서라고 부른다. 텐서는 파이썬에서 3차원 이상의 배열로 표현한다.
♣ 텐서(Tensor)
Numpy 를 사용하여 텐서를 이해해보자
1. 스칼라
스칼라는 하나의 실수값으로 이루어진 데이터로, 0차원 텐서라고 한다.

ndim을 출력했을 때 나오는 값을 축(axis)의 개수 또는 텐서의 차원이라고 한다.
2. 1차원 텐서(벡터)
숫자를 배열한 것을 벡터라고 하며, 벡터는 1차원 텐서이다. 주의할 점은 벡터에서도 차원이라는 용어가 쓰이는데, 이는 텐서의 차원과는 다른 개념이다. 아래의 예제는 4차원 벡터이지만, 1차원 텐서이다.

벡터에서의 차원은 하나의 축에 놓인 원소의 개수를 의미하고, 텐서에서의 차원은 축의 개수를 의미한다.
3. 2차원 텐서(행렬)
행과 열이 존재하는 벡터의 배열, 즉 행렬을 2차원 텐서라고 한다.

텐서의 크기란, 각 축을 따라서 얼마나 많은 차원이 있는지를 나타낸 값이다.
4. 3차원 텐서(다차원 배열)
행렬 또는 2차원 텐서를 단위로 한 번 더 배열하면 3차원 텐서라고 부른다. 데이터 사이언스 분야를 한정으로 하면 주로 3차원 이상의 배열을 텐서라고 부른다.

자연어 처리에서 특히 자주 보게 되는 것이 이 3D 텐서이다. 아래와 같은 3개의 훈련 데이터가 있다고 해보자.

이를 인공신경망 모델의 입력으로 사용하기 위해서 각 단어를 벡터화한다. 단어를 벡터화하는 방법은 원-핫 인코딩이나 워드 임베딩이 대표적이다. 여기서는 원-핫 인코딩으로 각 단어를 벡터화한다.

훈련 데이터의 단어들을 원-핫 벡터로 바꿔서 인공신경망의 입력으로 한 번에 하용한다고 하면 다음과 같다.


이렇게 훈련데이터를 다수 묶어 입력으로 사용하는 것을 딥러닝에서는 배치(Batch)라고 한다.
♣ 벡터와 행렬의 연산
벡터와 행렬의 기본적인 연산에 대해 알아보자
1. 벡터와 행렬의 덧셈과 뺄셈
같은 크기를 가지는 두 개의 벡터나 행렬은 덧셈과 뺄셈을 할 수 있다. 이 경우에는 같은 위치의 원소끼리 연산한다.
이러한 연산을 요소별 연산이라고 한다.


행렬도 마찬가지로 계산할 수 있다.

2. 벡터의 내적과 행렬의 곱셈
벡터의 점곱(dot product) 또는 내적(inner product)에 대해 알아보자. 내적이 성립하려면 두 벡터의 차원이 같아야 하며, 두 벡터 중 앞의 벡터가 행벡터(가로 방향 벡터)이고 뒤의 벡터가 열백터(세로 방향 벡터)여야 한다. 벡터의 내적 결과는 스칼라가 된다.
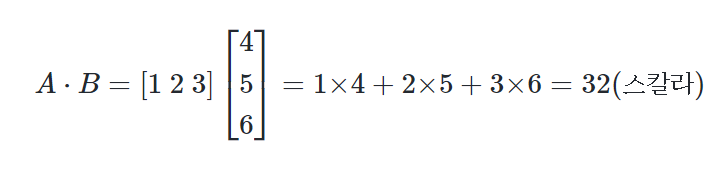
numpy를 이용하여 구현해보자.

행렬의 곱셈은 왼쪽 행렬의 행벡터(가로방향 벡터)와 오른쪽 행렬의 열벡터(서레 방향 벡터)의 내적이 결과 행렬의 원소가 되는 것으로 이뤄진다.

numpy를 이용하여 구현할 수 있다.

행렬 곱셈에서의 주요한 두 가지 조건을 기억해야 한다.
- 두 행렬의 곱 A*B가 성립하기 위해서는 행렬 A의 열의 개수와 행렬 B의 행의 개수가 같아야 한다.
- 두 행렬의 곱 A*B의 결과로 나온 행렬 AB의 크기는 A의 행의 개수와 B의 열의 개수를 가진다.
♣ 다중선형회귀 행렬 연산으로 이해하기
독립 변수가 2개 이상일 때, 1개의 종속 변수를 예측하는 문제를 행렬의 연산으로 표현할 수 있다. 다중선형회귀나 다중로지스틱회귀가 이러한 연산의 예이다.

독립 변수와 가중치의 위치를 바꿔서 표현할 수도 있다.


인공신경망도 본질적으로 위와 같은 행렬 연산이다.
♣ 샘플(sample)과 특성(feature)
훈련 데이터의 입력 행렬을 X라고 하였을 때 샘플(sample)과 특성(feature)의 정의는 다음과 같다.

머신 러닝에서는 데이터를 셀 수 있는 단위로 구분할 때 각각을 샘플(행)이라고 부르며, 종속 변수 y를 예측하기 위한 각각의 독립변수 x를 특성(열)이라고 부른다.
♣ 가중치와 편향 행렬의 크기 결정
입력과 출력의 행렬 크기를 살펴보면 가중치 행렬 w와 편향 행렬 b의 크기를 찾을 수 있다.
독립 변수 행렬을 X, 종속변수 행렬을 Y라고 했을 때 행렬 X를 입력 행렬, Y를 출력 행렬이라고 한다.

편향 행렬 b의 크기는 출력 행렬 Y와 같아야 한다. 행렬의 덧셈에 해당하는 B행렬은 Y행렬의 크기에 영향을 주지 않기 때문이다.

가중치 행렬 w에서는 행의 수가 입력 행렬 X의 열의 수와 같아야 한다.

X 행렬과 w 행렬의 곱의 결과로서 나온 행렬의 열의 크기는 출력 행렬 Y의 열의 크기와 동일하다.

이렇게 입력 행렬과 출력 행렬의 크기로부터 가중치 행렬과 편향 행렬의 크기를 추정할 수 있다면 딥러닝 모델을 구현했을 때 해당 모델에 존재하는 총 매개변수의 개수를 계산하기 쉽다. 딥러닝 모델의 총 매개변수 개수는 해당 모델에 존재하는 가중치 행렬과 편향 행렬의 모든 원소의 수이기 때문이다.
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(04-02. 파이토치로 로지스틱 회귀 구현하기) (0) | 2024.02.25 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(04-01. 로지스틱 회귀: Logistic Regression, 시그모이드 함수) (0) | 2024.02.25 |
| Pytorch로 시작하는 딥러닝 입문(03-07. 커스텀 데이터셋, transform 약간, ToTensor) (0) | 2024.02.24 |
| Pytorch로 시작하는 딥러닝 입문(03-06. 미니배치와 데이터로드) (0) | 2024.02.21 |
| Pytorch로 시작하는 딥러닝 입문(03-05. 클래스로 파이토치 모델 구현하기) (0) | 2024.02.21 |