2024. 3. 28. 21:10ㆍ딥러닝 모델: 파이토치
자연어 처리는 일반적으로 토큰화, 단어 집합 생성, 정수 인코딩, 패딩, 벡터화의 과정을 거친다. 여기서는 이러한 전반적인 과정에 대해 이해한다.
♣ 토큰화(Tokenization)
주어진 텍스트를 단어 또는 문자 단위로 자르는 것을 토큰화라고 한다. 영어의 경우, 토큰화를 사용하는 도구로서 대표적으로 spaCy와 NLTK가 있다.
우선 영어에 대해 토큰화 실습을 해보자.

1. spaCy 사용하기


2. NLTK 사용하기
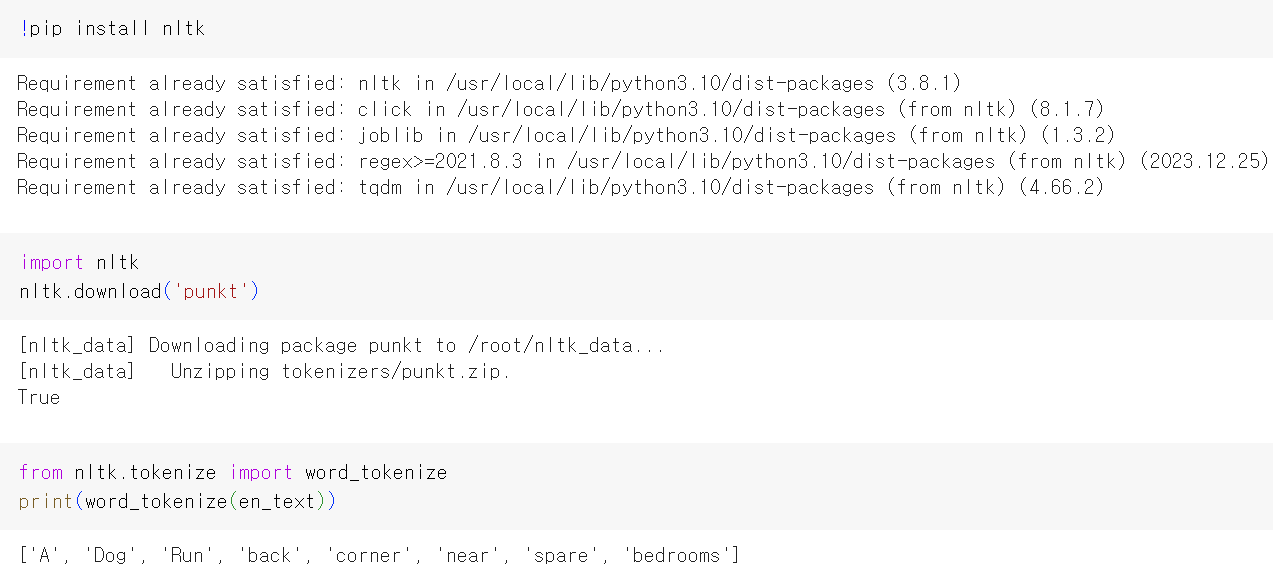
3. 띄어쓰기로 토큰화

영어의 경우, 띄어쓰기 단위로 토큰화를 해도 단어들 간 구분이 상당히 명확하기 때문에 토큰화 작업이 수월하다. 하지만 한국어의 경우에는 토큰화 작업이 훨씬 까다롭다. 한국어는 조사, 접사 등으로 인해 단순 띄어쓰기 단위로 나누면 같은 단어가 다른 단어로 인식되어서 단어 집합(vocabulary)의 크기가 불필요하게 커지기 때문이다.
*단어 집합 = 중복을 제거한 텍스트의 총 단어의 집합(set)
4. 한국어 띄어쓰기 토큰화

위의 예제에서 '사과'란 단어가 총 4번 등장했는데 모두 '의', '를', '가', '랑' 등이 붙어있어서 이를 제거하지 않으면 전부 다른 단어로 인식하게 된다.
5. 형태소 토큰화
위와 같은 상황을 방지하기 위해 한국어는 보편적으로 '형태소 분석기'로 토큰화를 한다. 여기서는 형태소 분석기 중에서 mecab을 사용한다.


앞선 예와 다르게 '의', '를', '가', '랑' 등이 전부 분리되어 '사과'라는 단어를 하나의 단어로 처리할 수 있다. 지금까지는 단어 또는 형태소 단위로 토큰화를 했지만 이보다 더 작은 문자 단위로 토큰화를 수행하는 경우도 있다.
6. 문자 토큰화

♣ 단어 집합(Vocabulary) 생성
단어 집합이란 중복을 제거한 텍스트의 총 단어의 집합을 의미한다. 실습을 위해 깃허브에서 '네이버 영화 리뷰 분류하기' 데이터를 다운로드한다. 네이버 영화 리뷰 데이터는 총 20만 개의 영화 리뷰를 긍정 1, 부정 0으로 레이블링한 데이터이다.
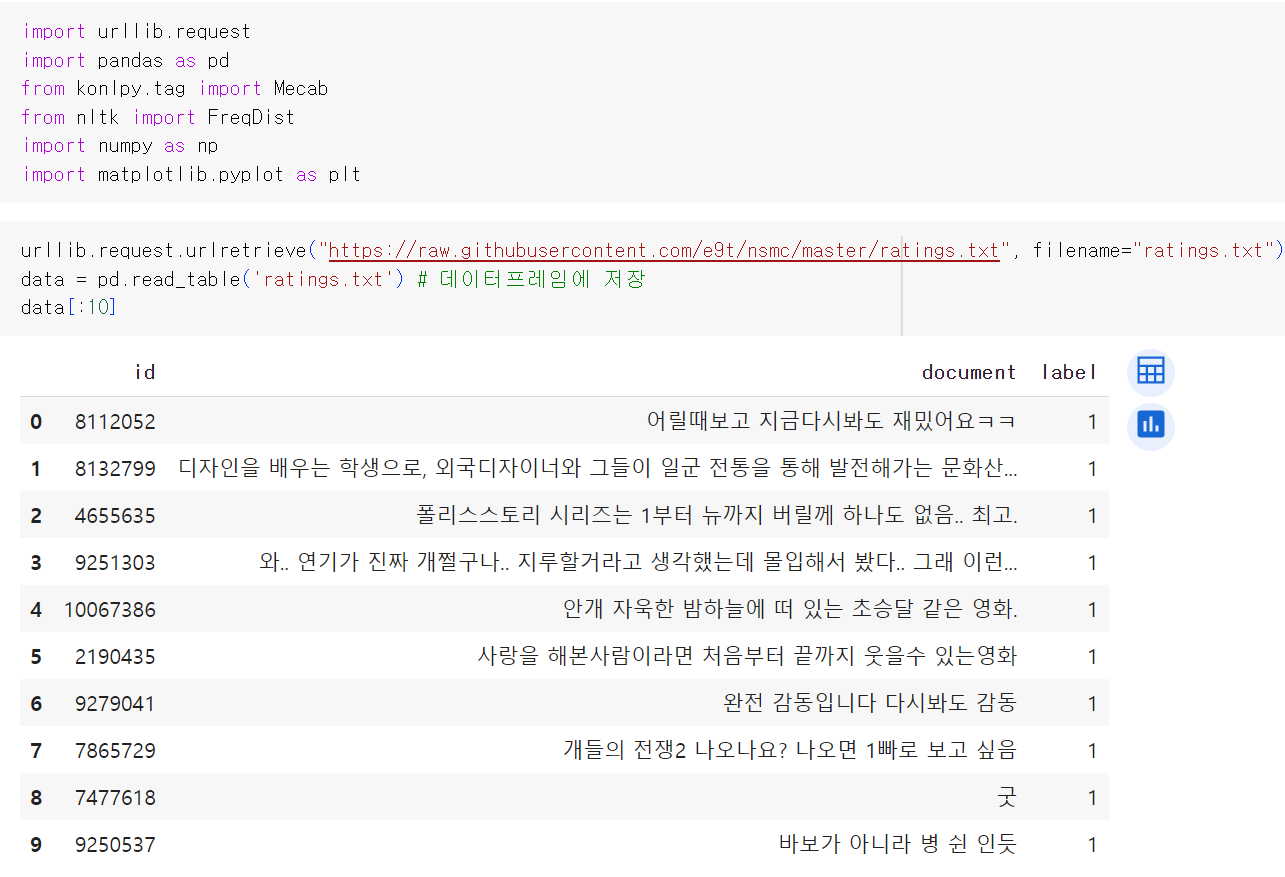

정규 표현식을 통해서 데이터를 정제한다.
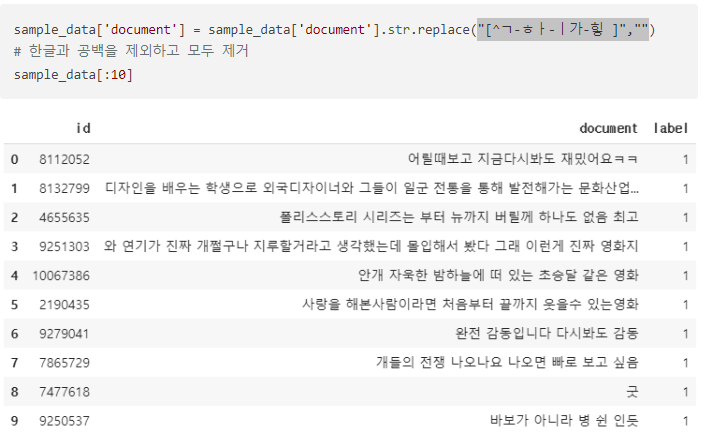
토큰화를 수행한다. 토큰화 과정에서 불용어를 제거하기 위해 불용어를 우선 정의한다. 형태소 분석기는 mecab을 사용한다.

이제 단어 집합을 만들어 보자. NLTK에서는 빈도수 계산 도구인 FreqDist( )를 지원한다.

단어를 키(key)로, 단어에 대한 빈도수가 값(value)로 저장되어 있다. vocab에 단어를 입력하면 빈도수를 리턴한다.

'재밌'이라는 단어가 총 10번 등장했다. most_common( )은 상위 빈도수의 단어만을 리턴한다. 이를 사용하여 등장 빈도수가 높은 단어들을 원하는 개수만큼만 얻을 수 있다.

단어 집합의 크기가 500으로 줄어든 것을 확인할 수 있다.
♣ 각 단어에 고유한 정수 부여
enumerate( )는 순서가 있는 자료형(list, set, tuple, dictionary, string)을 입력으로 받아서 인덱스를 순차적으로 함께 리턴한다. 인덱스 0과 1은 다른 용도로 남겨두고 나머지 단어들은 2부터 501까지 순차적으로 인덱스를 부여해보자.

이제 기존의 훈련 데이터에서 각 단어를 고유한 정수로 부여하는 작업을 진행한다.

♣ 길이가 다른 문장들을 모두 동일한 길이로 바꿔주는 패딩
길이가 다른 리뷰들을 모두 동일한 길이로 바꿔주는 패딩 작업을 진행해보자. 앞서 단어 집합에 패딩을 위한 토큰인 'pad'를 추가했다. 패딩 작업은 정해준 길이로 모든 샘플들의 길이를 맞춰주되, 길이가 정해준 길이보다 짧은 샘플들에는 'pad' 토큰을 추가하여 길이를 맞춰준다.

길이가 가장 긴 리뷰의 길이는 63이다. 모든 리뷰의 길이를 63으로 통일해보자.


단어들을 고유한 정수로 맵핑하였으니 각 정수를 고유한 단어 벡터로 바꾸는 작업이 필요하다. 단어 벡터를 얻는 방법은 크게 원-핫 인코딩과 워드 임베딩이 있는데 주로 워드 임베딩이 사용된다.
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(10-01. 언어모델이란?) (0) | 2024.04.02 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(09-06. 한국어 전처리 패키지) (0) | 2024.03.30 |
| Pytorch로 시작하는 딥러닝 입문(09-03. 정규 표현식) (0) | 2024.03.28 |
| Pytorch로 시작하는 딥러닝 입문(09-02. 불용어) (0) | 2024.03.27 |
| Pytorch로 시작하는 딥러닝 입문(09-02. 텍스트 데이터의 정제와 정규화) (0) | 2024.03.26 |