2024. 4. 2. 19:48ㆍ딥러닝 모델: 파이토치
♣ 언어모델(Language Model)
언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당하는 모델을 의미한다.
언어 모델을 만드는 방법은 크게 1) 통계를 이용한 방법 과 2) 인공 신경망을 이용한 방법으로 구분할 수 있다.
최근에는 통계를 이용한 방법보다는 인공 신경망을 이용한 방법이 더 좋은 성능을 보여준다.
언어 모델은 가장 자연스러운 단어 시퀀스를 찾아내는 모델이다. 단어 시퀀스에 확률을 할당하기 위해서 가장 보편적으로 사용하는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것이다.
주어진 양쪽의 단어들로부터 가운데 비어있는 단어를 예측하는 언어 모델도 있다. 이는 문장의 가운데에 있는 단어를 비워놓고 양쪽의 문맥을 통해서 빈 칸의 단어를 맞추는 추론 문제와 비슷하다. 이 유형의 언어 모델은 BERT 챕터에서 다룬다.
언어 모델에 -ing를 붙인 언어 모델링(Language Modeling)은 주어진 단어들로부터 아직 모르는 단어를 예측하는 작업을 의미한다. 즉 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일이다.
♣ 단어 시퀀스의 확률 할당
자연어 처리에서 단어 시퀀스에 확률을 할당하는 일이 왜 필요할까? 예를 들어서 알아보자. 대문자 P는 확률을 의미한다.
1. 기계 번역(Machine Translation)
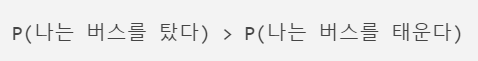
언어 모델은 위의 두 문장을 비교하여 왼쪽 문장의 확률이 더 높다고 판단한다.
2. 오타 교정(Spell Correction)

언어 모델은 위의 두 문장을 비교하여 왼쪽 문장의 확률이 더 높다고 판단한다.
3. 음성 인식(Speech Recognition)

언어 모델은 두 문장을 비교하여 오른쪽 문장의 확률이 더 높다고 판단한다.
언어 모델은 확률을 통해 보다 적절한 문장을 판단한다.
♣ 주어진 이전 단어들로부터 다음 단어 예측하기
1. 단어 시퀀스의 확률
하나의 단어를 w, 단어 시퀀스를 대문자 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은 다음과 같다.

2. 다음 단어 등장 확률
다음 단어 등장 확률을 식으로 표현한다. n-1개의 단어가 나열된 상태에서 n번째 단어의 확률은 다음과 같다.

| 기호는 조건부 확률을 의미한다. 예를 들어 다섯번째 단어의 확률은 아래와 같다.
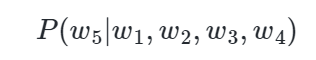
전체 단어 시퀀스 W의 확률은 모든 단어가 예측되고 나서야 알 수 있으므로 단어 시퀀스의 확률은 다음과 같다.
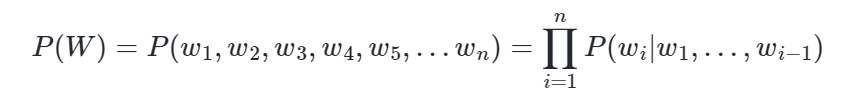
♣ 검색 엔진에서 언어 모델의 예

입력된 단어들의 나열에 대해서 다음 단어를 예측하는 언어 모델을 사용한다.
'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(10-03. N-gram 언어모델) (0) | 2024.04.06 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(10-02. 통계적 언어 모델: Statistical Language Model, SLM) (0) | 2024.04.02 |
| Pytorch로 시작하는 딥러닝 입문(09-06. 한국어 전처리 패키지) (0) | 2024.03.30 |
| Pytorch로 시작하는 딥러닝 입문(09-05. 딥 러닝을 위한 자연어 처리 전처리 실습) (0) | 2024.03.28 |
| Pytorch로 시작하는 딥러닝 입문(09-03. 정규 표현식) (0) | 2024.03.28 |