2024. 3. 30. 12:08ㆍ딥러닝 모델: 파이토치
앞서 소개한 형태소와 문장 토크나이징 도구들인 KoNLPy와 KSS(Korean Sentence Splitter)와 함께 유용하게 사용할 수 있는 한국어 전처리 패키지를 정리해보자
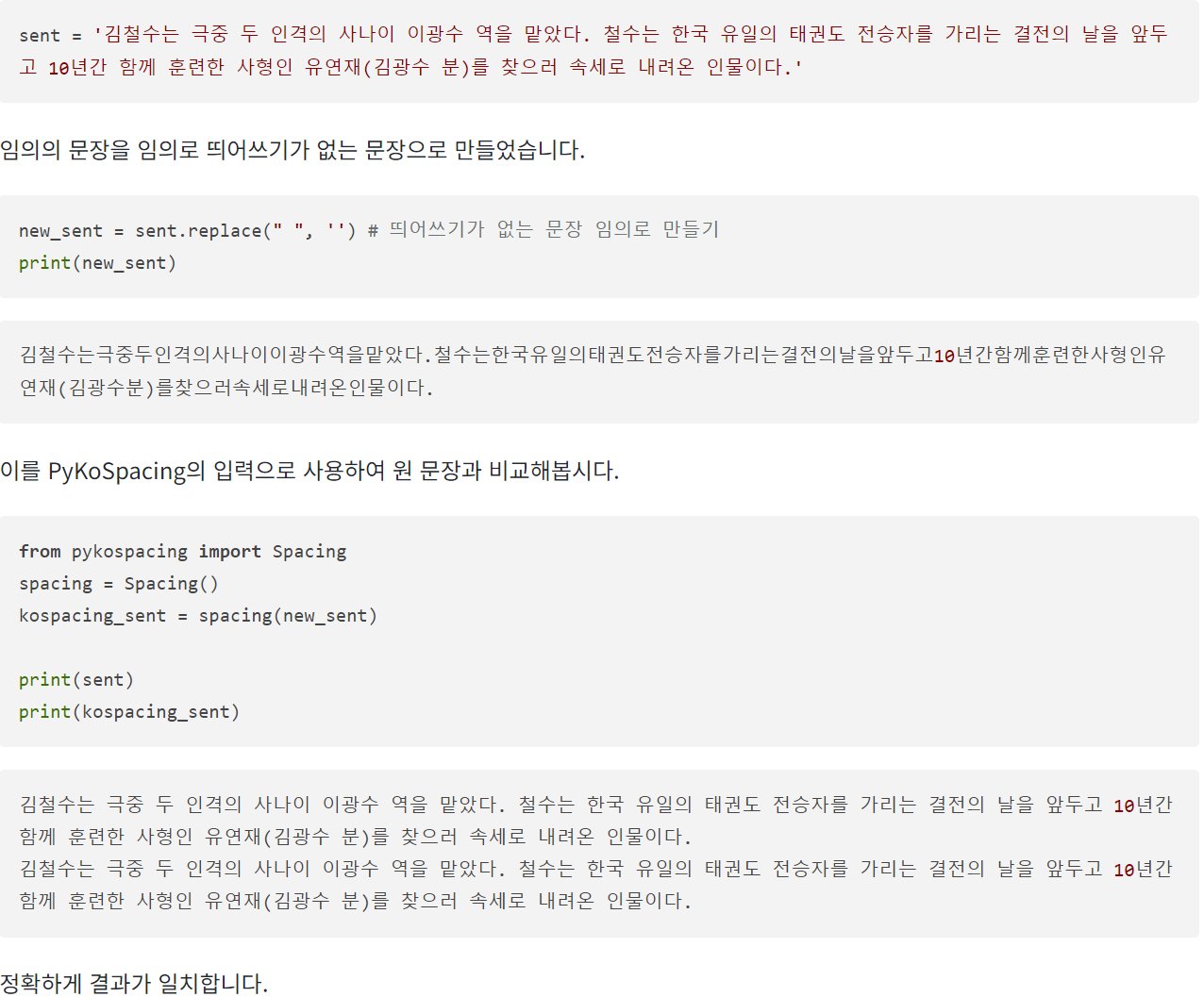
♣ PyKoSpacing
PyKoSpacing 은 띄어쓰기가 되어 있지 않은 문장을 띄어쓰기한 문장으로 변환하는 패키지이다. 대용량 코퍼스를 학습하여 만들어진 띄어쓰기 딥러닝 모델로, 준수한 성능을 가진다.

♣ Py-Hanspell
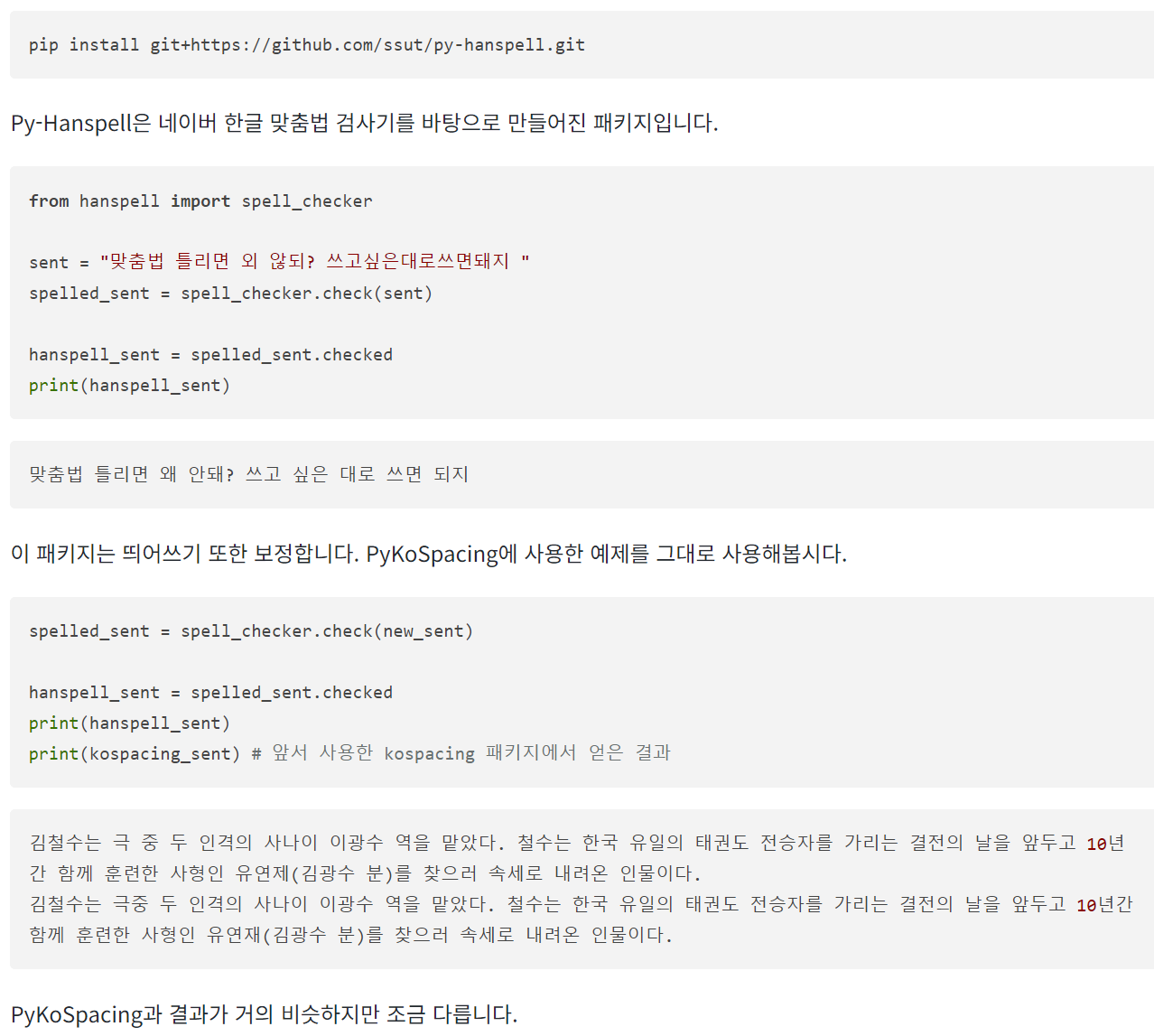
Py-Hanspell은 네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지이다. 이 패키지는 맞춤법만이 아니라 띄어쓰기도 보정한다.
https://github.com/ssut/py-hanspell/issues/41
py-hanspell spell_checker.check 사용 시 KeyError: 'result' · Issue #41 · ssut/py-hanspell
안녕하세요. chec = spell_checker.check() 사용 시 KeyError: 'result'가 반환됩니다. hanspell\spell_checker.py 내 line 62 에서 html = data['message']['result']['html'] 부분 중 ['result'] 부분에서 keyerror가 발생한 것 같습니다.
github.com
♣ SOYNLP를 이용한 단어 토큰화
sonylp는 품사태깅, 단어 토큰화 등을 지원하는 단어 토크나이저이다. 비지도 학습으로 단어 토큰화를 한다는 특징을 갖고 있으며 데이터에 자주 등장하는 단어들을 분석한다. soynlp 단어 토크나이저는 내부적으로 단어 점수 표로 동작한다. 이 점수는 응집 확률(cohesion probability)와 브랜칭 엔트로피를 활용한다.
1. 신조어 문제
기존의 형태소 분석기는 신조어나 등록되지 않은 단어의 경우 제대로 구분하지 못한다는 단점이 있었다.



에이오식스는 아이돌의 이름이고, 이짱구는 에이오식스의 멤버이며, 최애돌은 최고로 애정하는 캐릭터라는 뜻이지만 위의 형태소 분석 결과에서는 전부 분리된 결과를 보여준다. 그렇다면 텍스트 데이터에서 특정 문자 시퀀스가 함께 자주 등장하는 빈도가 높고, 앞 뒤로 조사 또는 완전히 다른 단어가 등장하는 것을 고려해서 해당 문자 시퀀스를 형태소라고 판단하는 단어 토크나이저라면 어떨까? 예를 들어 에이오식스라는 문자열이 자주 연결되어 등장한다면 한 단어라고 판단하고, 또한 에이오식스라는 단어 앞, 뒤에 '최고', '가수', '실력'과 같은 독립된 다른 단어들이 계속해서 등장한다면 에이오식스를 한 단어로 파악하는 식이다. 그리고 이런 아이디어를 가진 단어 토크나이저가 soynlp이다.
2. 학습하기
soynlp는 기본적으로 학습에 기반한 토크나이저이므로 학습에 필요한 한국어 문서를 다운로드한다.

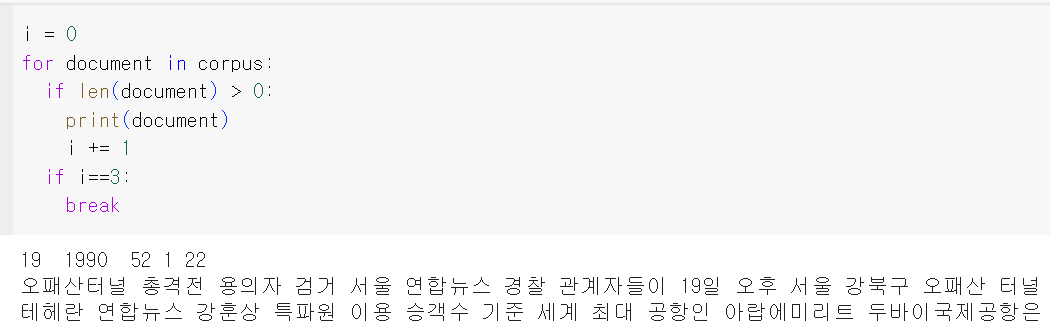
훈련 데이터를 다수의 문서로 분리한다.

총 30,091개의 문서가 존재하는데, 이 중 상위 3개의 문서만 출력해본다.
soynlp는 학습 기반의 단어 토크나이저이므로 기존의 KoNLPy에서 제공하는 형태소 분석기들과는 달리 학습 과정을 거쳐야 한다. 이는 전체 코퍼스로부터 응집 확률과 브랜칭 엔트로피 단어 점수표를 만드는 과정이다. WordExtractor.extrct( )를 통해서 전체 코퍼스에 대한 단어 점수표를 계산한다.

3. SOYNLP의 응집 확률(cohesion probability)
응집 확률은 내부 문자열(substring)이 얼마나 응집하여 자주 등장하는지 판단하는 척도이다. 응집 확률은 문자열을 문자 단위로 분리하여 내부 문자열을 만드는 과정에서 왼쪽부터 순서대로 문자를 추가하면서 각 문자열이 주어졌을 때 그 다음 문자가 나올 확률을 계산하여 누적곱을 한 값이다. 이 값이 높을수록 전체 코퍼스에서 이 문자열 시퀀스는 하나의 단어로 등장할 가능성이 높다. 수식은 아래와 같다.
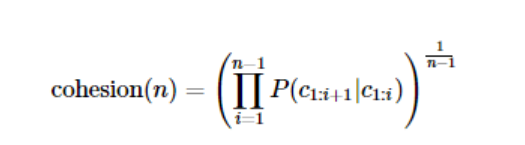
'반포한강공원에'라는 7의 길이를 가진 문자 시퀀스에 대해서 각 내부 문자열의 스코어를 구하는 과정은 아래와 같다.

실습을 통해 응집 확률을 계산해보자.

'반포한강공원'까지는 글자 수가 늘어날수록 응집 확률이 커지다가 '에'가 붙으니 응집 확률이 낮아진다. 응집도를 통해 하나의 단어로 판단하기에 가장 적합한 문자열은 '반포한강공원'이라고 볼 수 있다.
4. SOYNLP의 브랜칭 엔트로피
브랜칭 엔트로피는 확률 분포의 엔트로피값을 사용한다. 이는 주어진 문자열에서 얼마나 다음 문자가 등장할 수 있는지 판단하는 척도이다. 퀴즈를 예시로 이야기해보자. 한 문자씩 주어졌을 때, 매번 다음 문자를 맞추는 퀴즈이다.
첫 번째 문자: '디'
다음에 등장할 문자를 맞추는 것은 쉽지 않다.
두 번째 문자: '디스'
여러 가지 단어가 정답일 수 있다.
세 번째 문자: '디스플'
세 번째 문자까지 주어지면 좀 더 명확해진다.
네 번째 문자: '디스플레'
정답은 '디스플레이'
브랜칭 엔트로피를 '주어진 문자 시퀀스에서 다음 문자 예측을 할 때 헷갈리는 정도'라고 비유해보자. 브랜칭 엔트로피의 값은 완성된 단어에 가까워질수록 문맥을 이용하여 점점 정확히 예측할 수 있게 되면서 엔트로피 값이 점점 줄어든다.

'디스' 다음에는 다양한 문자가 올 수 있기 때문에 엔트로피 값이 1.63이라는 값을 가지는 반면, '디스플'이라는 문자열 다음에는 '레'가 올 것이 명백하기 때문에 0이라는 값을 가진다.
'디스플레이'로 완성된 단어의 브랜칭 엔트로피를 출력하면 갑자기 값이 증가한다. '디스플레이'라는 문자 시퀀스 다음에 조사나 다른 단어와 같이 다양한 경우가 올 수 있기 때문이다. 하나의 단어가 끝나면 그 경계 부분부터 다시 브랜칭 엔트로피 값이 증가하는 것이다.
5. SOYNLP의 L tokenizer
한국어는 띄어쓰기 단위로 나눈 어절 토큰은 주로 L 토큰 + R 토큰의 형식을 가질 때가 많다.
예를 들어서 '공원에'는 '공원 + 에' 로 나눌 수 있다. 또는 '공부하는'은 '공부+하는'으로 나눌 수도 있다. L 토크나이저는 L 토큰 + R 토큰으로 나누되 분리 기준을 점수가 가장 높은 L토큰을 찾아내는 원리를 가진다.

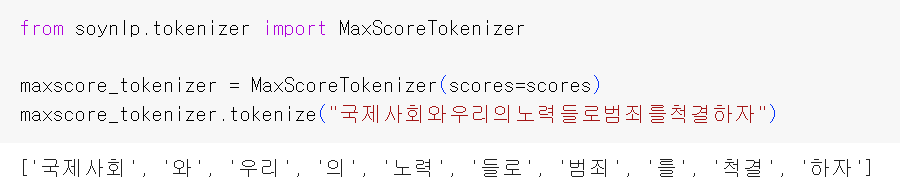
6. 최대 점수 토크나이저
최대 점수 토크나이저는 띄어쓰기가 되지 않는 문장에서 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저이다. 띄어쓰기가 되어 있지 않은 문장을 넣어서 점수를 통해 토큰화된 결과를 보자.
♣ SOYNLP를 이용한 반복되는 문자 정제
SNS나 채팅 데이터와 같은 한국어 데이터의 경우, ㅋㅋ, ㅋㅋㅋㅋ 등의 이모티콘이 불필요하게 연속되는 경우가 많은데, 이를 모두 다른 단어로 처리하는 것은 불필요하다. 반복되는 것은 하나로 정규화시키자.


♣ Customized KoNLPy
형태소 분석기를 사용하여 단어 토큰화를 해보자.

위 문장에서 '은경이'는 사람 이름이므로 제대로 된 결과를 얻기 위해서 '은', '경이'와 같이 글자가 분리되는 것이 아니라 '은경이' 또는 최소한 '은경'이라는 단어 토큰을 얻어야 한다. 이런 경우에는 형태소 분석기에 사용자 사전을 추가할 수 있다. '은경이'는 하나의 단어이기 때문에 분리하지 말라고 형태소 분석기에 알려주는 것이다.
이번 실습에는 Customized Konlpy라는 사용자 사전 추가가 매우 쉬운 패키지를 사용한다.
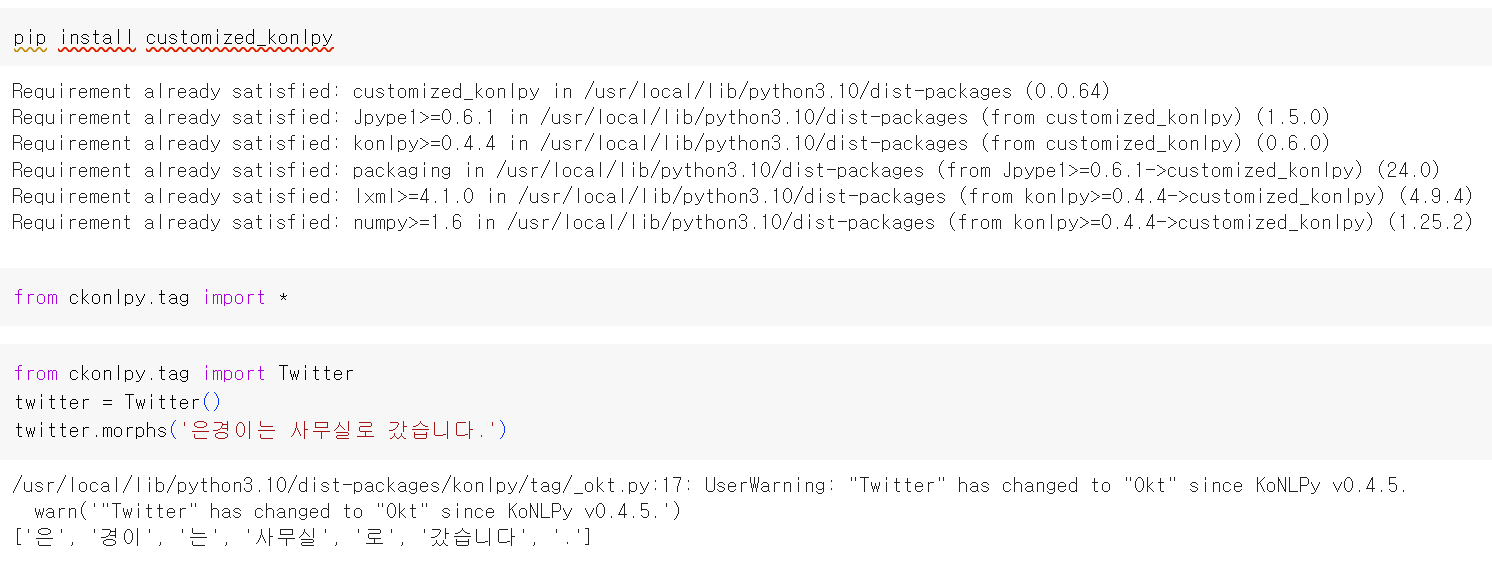
앞선 예시와 마찬가지로 '은경이'라는 단어가 '은', '경이'와 같이 분리된다. 이때 형태소 분석기 Twitter에 add_dictionary('단어', '품사')와 같은 형식으로 사전 추가를 할 수 있다.

'딥러닝 모델: 파이토치' 카테고리의 다른 글
| Pytorch로 시작하는 딥러닝 입문(10-02. 통계적 언어 모델: Statistical Language Model, SLM) (0) | 2024.04.02 |
|---|---|
| Pytorch로 시작하는 딥러닝 입문(10-01. 언어모델이란?) (0) | 2024.04.02 |
| Pytorch로 시작하는 딥러닝 입문(09-05. 딥 러닝을 위한 자연어 처리 전처리 실습) (0) | 2024.03.28 |
| Pytorch로 시작하는 딥러닝 입문(09-03. 정규 표현식) (0) | 2024.03.28 |
| Pytorch로 시작하는 딥러닝 입문(09-02. 불용어) (0) | 2024.03.27 |