2023. 7. 17. 22:51ㆍResNet
♣ 대회: Kaggle Fruit Classification(https://www.kaggle.com/datasets/sshikamaru/fruit-recognition)
♣ Data set 설명
- Trainig set: 16854 images
- Test set: 5641 images
- Number of classes: 33(fruits and vegetables)
- Image Size: 100*100 pixels
♣ Process

from torchvision.datasets import ImageFolder
torchvision.datasets 모듈에서 ImageFolder 클래스를 가져옴. ImageFolder 클래스는 이미지 데이터와 함께 작업하기 위해 특별히 설계된 파이토치 데이터셋 클래스임. 이 클래스는 딥러닝 모델을 훈련하기 위해 이미지 데이터를 로드하고 정리하는 과정을 간소화함
from torchvision.transforms import transforms
torchvision 라이브러리에서 transforms 모듈을 가져옴. transforms 모듈은 로드한 이미지에 적용할 수 있는 일련의 일반적인 이미지 변환 기능을 제공함(데이터 변환) 예를 들어, 이미지 크기 조정, 자르기, 정규화 등의 변환을 사용할 수 있음. 이러한 변환은 딥러닝 모델에 입력 데이터를 전달하기 전에 입력 데이터를 전처리하는 데 도움이 됨

데이터 전처리 과정을 정의하는 부분임. transforms.Compose() 함수를 사용하여 여러 개의 변환을 순차적으로 적용할 수 있음.
transforms.Resize(225)
이미지의 크기를 255로 조정하는 변환. 입력 이미지는 가로 또는 세로 중 큰 쪽의 크기가 255로 조정됨.
transforms.ToTensor()
이미지를 텐서(Tensor) 형태로 변환하는 변환. 텐서는 다차원 배열로 데이터를 표현하는데, 딥러닝 모델은 주로 텐서 형태의 입력을 다루기 때문에 이미지를 텐서로 변환해야 함. 이 변환을 적용하면 이미지의 각 픽셀 값이 0과 1 사이의 실수로 정규화된 텐서로 변환됨
transform1, 2, 3은 이러한 변환들의 조합.

- transforms.Resize(255): 이미지의 크기를 255로 조정하는 변환. 이미지의 가로 또는 세로 중 큰 쪽의 크기가 255로 조정됨
- transforms.RandomHorizontalFlip(): 이미지를 무작위로 수평으로 뒤집는 변환. 이 변환을 통해 데이터 증강(augmentation)이 수행되며, 모델의 일반화 성능을 향상시키고 오버피팅을 방지할 수 있음
- transforms.RandomVerticalFlip(): 이미지를 무작위로 수직으로 뒤집는 변환. 마찬가지로 데이터 증강을 수행함
- transforms.ToTensor(): 이미지를 텐서(Tensor) 형태로 변환하는 변환. 이미지의 픽셀 값은 0과 1 사이의 실수로 정규화된 텐서로 변환됨
- transforms.RandomErasing(p=0.5): 이미지에서 무작위로 사각형 영역을 선택하여 삭제하는 변환. 이는 모델에 노이즈를 주거나 정보를 부분적으로 가리는 것으로, 일종의 데이터 증강 기법. p=0.5는 각 이미지에 대해 사각형 영역을 삭제할 확률을 나타냄

- transforms.RandomRotation(10): 이미지를 무작위로 최대 10도까지 회전하는 변환. 이를 통해 데이터에 다양성을 부여하고 모델의 일반화 성능을 향상시킬 수 있음
- transforms.Resize(255): 이미지의 크기를 255로 조정하는 변환. 이미지의 가로 또는 세로 중 큰 쪽의 크기가 255로 조정됨
- transforms.RandomHorizontalFlip(): 이미지를 무작위로 수평으로 뒤집는 변환. 이는 데이터 증강을 위한 기법으로 사용됨
- transforms.RandomVerticalFlip(): 이미지를 무작위로 수직으로 뒤집는 변환. 마찬가지로 데이터 증강을 수행함
- transforms.ToTensor(): 이미지를 텐서(Tensor) 형태로 변환하는 변환
- transforms.RandomErasing(p=0.5): 이미지에서 무작위로 사각형 영역을 선택하여 삭제하는 변환. 데이터 증강을 위한 기법으로 사용됨.
- transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1): 이미지의 색상을 무작위로 변화시키는 변환. 밝기, 대비, 채도, 색조에 무작위한 변화를 가해 데이터에 다양성을 추가함
ImageFolder('/kaggle/input/fruit-recognition/train/train', transform=transform2)
ImageFolder 클래스를 사용하여 데이터셋을 로드함. 첫 번째 인자는 이미지 데이터가 저장된 디렉터리 경로임. 두 번째 인자인 transform은 이미지 데이터에 적용할 전처리 변환을 지정함.
두 번째 인자인 transform은 이미지 데이터에 적용할 전처리 변환을 지정함. 여기서는 앞서 정의한 transform2를 사용함.
따라서 데이터셋은 이미지 크기 조정, 무작위로 수평 및 수직 뒤집기, 텐서 변환, 사각형 영역 삭제 등의 전처리를 거쳐 훈련에 사용될 준비가 된 상태로 로드됨

random_split
데이터셋을 무작위로 훈련 및 검증 서브셋으로 분할하는 데 사용됨. 이 함수는 일반적으로 딥러닝 워크플로우에서 데이터를 훈련 및 평가를 위한 별도의 서브셋으로 분할하는 데 사용됨

classes = train_data1.classes: train_data1
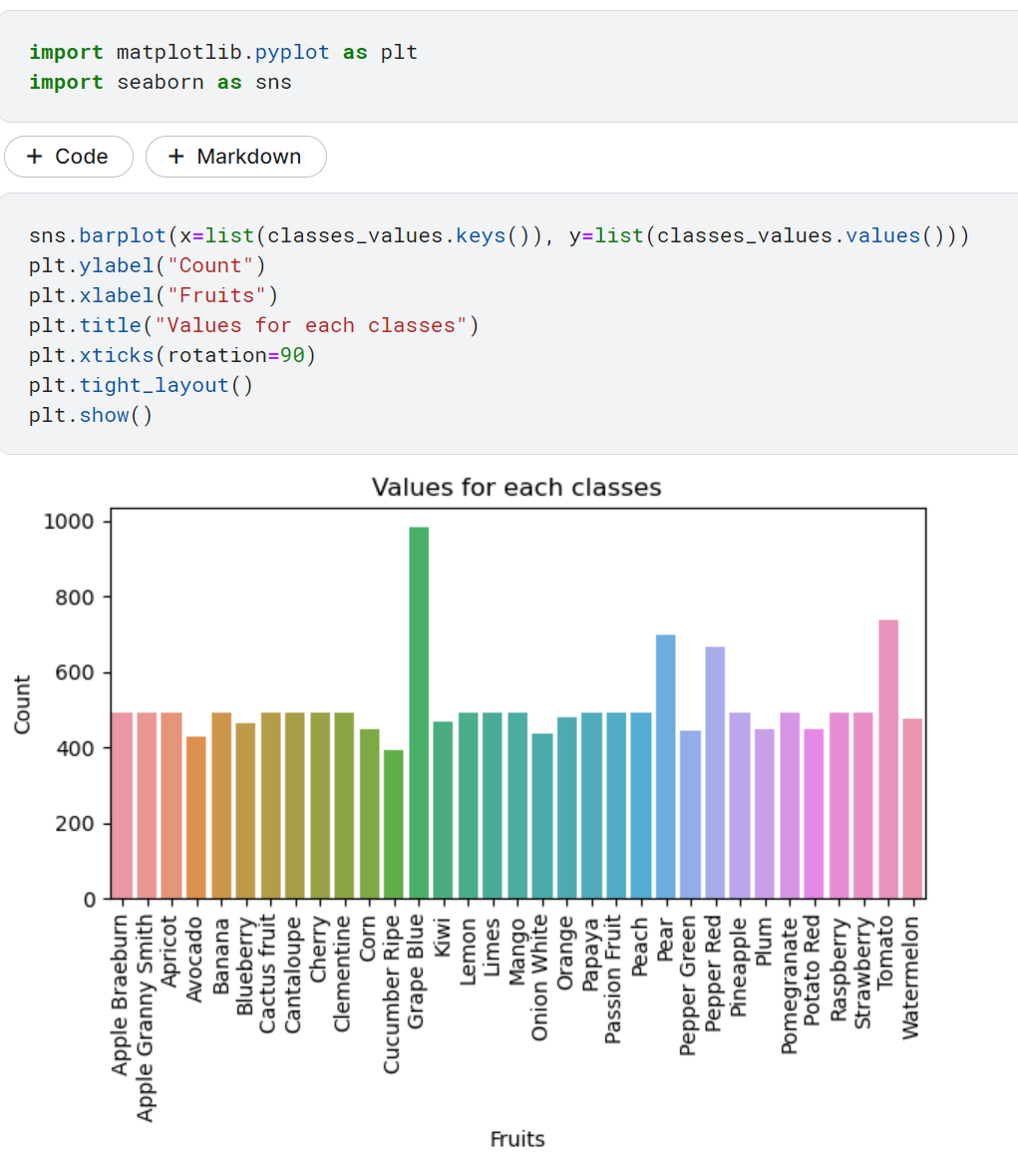
데이터셋에서 클래스 정보를 추출하여 classes 변수에 저장함. train_data1은 이미지 데이터셋 객체를 나타내며, 클래스 정보는 해당 데이터셋의 클래스 레이블로부터 추출함. 과일들의 클래스 개수는 33개
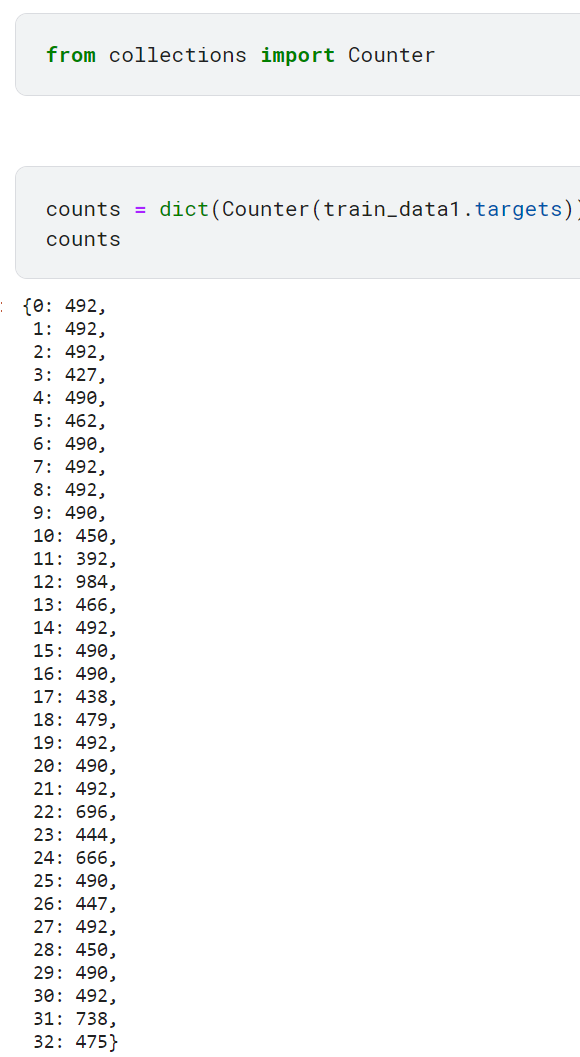
- from collections import Counter: Counter 클래스를 사용하기 위해 collections 모듈에서 Counter를 가져옴. Counter 클래스는 요소의 개수를 세는 기능을 제공함.
- counts = dict(Counter(train_data1.targets)): Counter 클래스를 사용하여 train_data1 데이터셋의 클래스 레이블(targets)에서 각 클래스의 데이터 개수를 계산함. Counter 객체의 결과를 dict() 함수를 사용하여 딕셔너리로 변환한 후, counts 변수에 저장함.
- counts: counts 변수를 출력하여 클래스별 데이터 개수를 확인함. 이 변수는 딕셔너리 형태로 클래스 레이블을 키(key)로, 해당 클래스의 데이터 개수를 값(value)로 가지고 있음.

counts.values()
counts 딕셔너리의 값(value) 부분을 반환하는 코드. counts 딕셔너리는 각 클래스의 데이터 개수를 클래스 레이블을 키(key)로 가지고 있음. counts.values()를 사용하면 이러한 데이터 개수 값들을 리스트 형태로 얻을 수 있음


train_data2에 적용한 transform2 에는 RandomErasing이 있었어서 한 군데씩 지워져 있음


- train_ratio = 0.8: train_ratio 변수에는 훈련 세트의 비율이 지정됩니다. 여기서는 전체 데이터셋의 80%를 훈련에 사용하고자 합니다.
- dataset_size = len(train_data1): train_data1 데이터셋의 크기를 dataset_size 변수에 저장합니다. len() 함수를 사용하여 데이터셋의 샘플 수를 계산합니다.
- train_size = int(train_ratio * dataset_size): train_ratio와 dataset_size를 곱하여 훈련 세트의 크기를 정의합니다. train_ratio가 0.8이므로, 전체 데이터셋 크기의 80%에 해당하는 샘플 수가 train_size로 설정됩니다. int() 함수를 사용하여 정수로 변환합니다.
- test_size = dataset_size - train_size: 테스트 세트의 크기를 dataset_size에서 train_size를 뺌으로써 정의합니다. 따라서 테스트 세트는 남은 20%의 샘플 수를 가집니다.
- train_data1, test_data = random_split(train_data1, [train_size, test_size]): random_split() 함수를 사용하여 train_data1 데이터셋을 훈련 세트와 테스트 세트로 분할합니다. 첫 번째 인자로는 분할할 데이터셋을 전달하고, 두 번째 인자로는 [train_size, test_size] 리스트를 전달하여 훈련 세트와 테스트 세트의 크기를 지정합니다. 이 함수는 데이터셋을 무작위로 분할하여 지정된 크기에 맞게 나누고, 두 개의 데이터셋을 반환합니다. 이를 train_data1과 test_data 변수에 할당합니다.

torch.utils.data.ConcatDataset
ConcatDataset은 여러 데이터셋을 연결하여 하나의 큰 데이터셋으로 만들어주는 PyTorch의 유틸리티 클래스
[ ] 안에 연결하려는 데이터셋인 train_data2와 train_data1을 리스트 형태로 전달함

import tqdm
이 줄은 tqdm 모듈을 가져옵니다. tqdm은 루프와 기타 반복 가능한 객체에 대해 빠르고 확장 가능한 진행 표시줄을 제공합니다. 코드의 실행 진행 상황을 추적하고 진행 상황을 시각적으로 표시하는 데 사용할 수 있습니다.

train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True, num_workers=2)
train_data 데이터셋을 DataLoader로 불러옵니다. DataLoader는 데이터셋을 미니배치로 나누어 모델에 공급하기 위한 유틸리티 클래스입니다. 첫 번째 인자로는 로드할 데이터셋인 train_data를 전달합니다. 두 번째 인자인 batch_size는 미니배치의 크기를 나타냅니다. 여기서는 64로 설정되어 한 번에 64개의 샘플을 모델에 전달합니다. 세 번째 인자인 shuffle은 데이터를 섞을지 여부를 결정합니다. True로 설정되면 데이터가 에포크마다 섞입니다. 네 번째 인자인 num_workers는 데이터 로딩을 병렬로 처리하는 데 사용되는 스레드(worker)의 수를 나타냅니다. 여기서는 2로 설정되어 2개의 스레드가 사용됩니다.
*torch.utils.data.DataLoader의 num_workers는 dataset의 데이터를 gpu로 전송할 때 필요한 전처리를 수행할 때 사용하는 subprocess의 수를 말한다. num_workers의 수를 늘리면 병렬처리를 통해 더 빠르게 gpu에 정보를 전달할 수 있어 성능이 좋아진다. 하지만 num_workers의 수가 너무 크면 다른 일을 수행하는 데 사용할 자원이 적어져 성능이 안 좋아질 수 있다.
♣ Model Architecture
잔차 블록은 기울기의 흐름을 개선하고 네트워크가 효과적으로 학습할 수 있도록 도와주는 역할을 함.

-ResidualBlock 클래스는 nn.Module의 하위 클래스로 정의되었으며 PyTorch에서 모든 신경망 모듈의 기본 클래스임
- _ _ init_ _ 메서드는 ResidualBlock 클래스를 초기화함. super을 사용하여 부모 클래스의 _ _init_ _ 메서드를 호출함
- 블록은 2개의 합성곱 레이어(conv1, conv2)와 배치정규화레이어(self.bn1, self.bn2), 그리고 ReLU 활성화 함수로 구성됨
- 스트라이드가 1이 아니거나 입력 채널의 수가 출력 채널의 수와 다른 경우, 잔차 연결을 위한 shortcut 연결이 생성됨. 이 shortcut 연결은 입력과 출력 특성 맵의 차원을 맞추기 위해 합성곱 레이어 (nn.Conv2d)와 배치 정규화 (nn.BatchNorm2d)를 사용하여 구현함
- forward 메서드는 잔차 블록의 순전파를 정의함. 입력 텐서 x를 받아서 합성곱 레이어, 배치정규화, ReLU 활성화 함수를 통과함.
-스트라이드가 1이 아니거나 입력 채널의 수가 출력 채널의 수와 다른 경우, 입력 텐서 (x)는 shortcut 연결을 통과하고 out 텐서에 더해. 이 잔차 연결은 기울기를 전파하고 입력의 정보를 보존하는 데 도움이 됨.
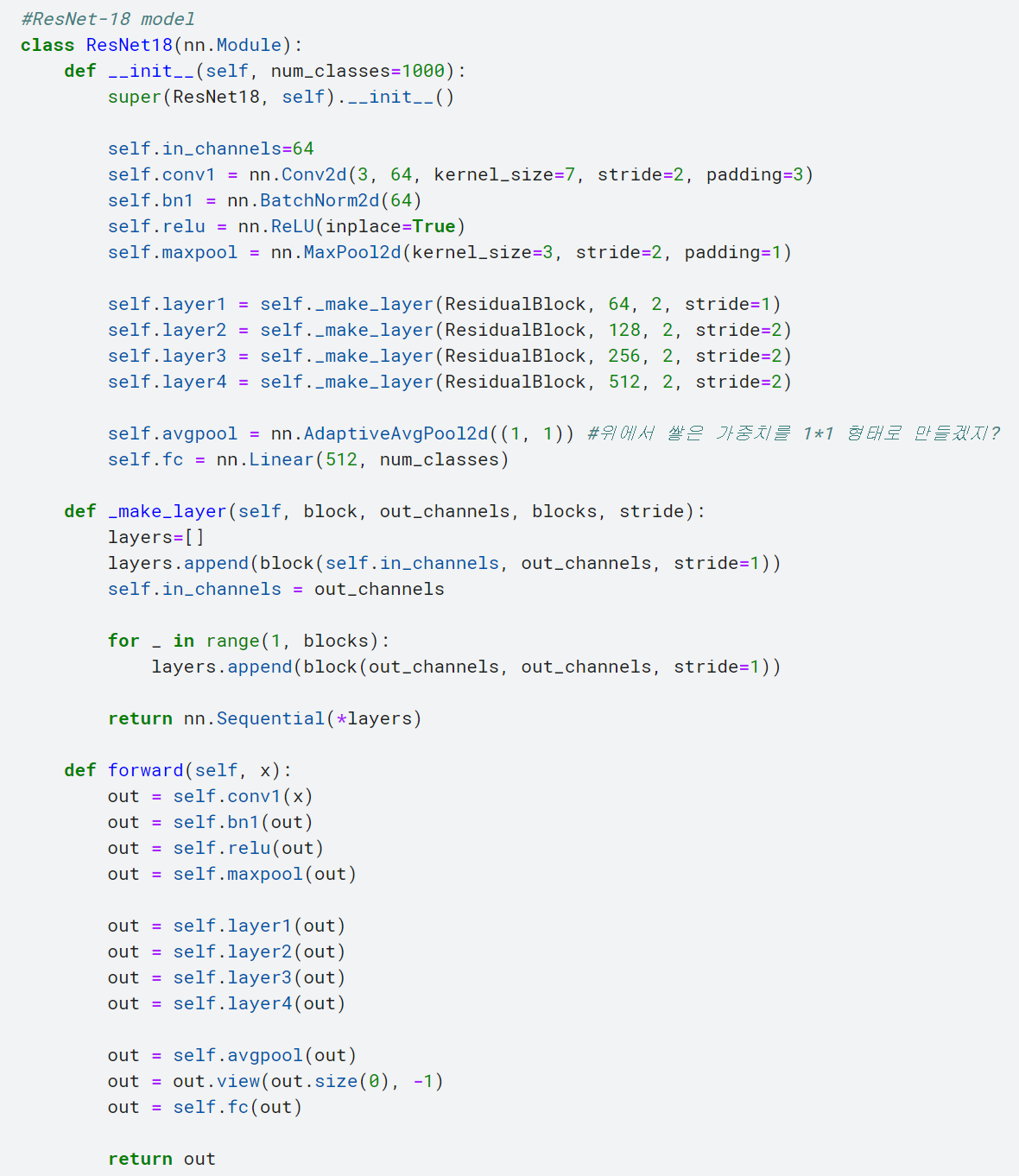
이 코드는 ResNet-18 모델을 정의합니다. ResNet-18은 딥러닝 모델 중 하나로, 이미지 분류와 같은 컴퓨터 비전 작업에서 널리 사용되는 모델입니다. 코드를 설명해보겠습니다:
- ResNet18 클래스는 nn.Module을 상속하여 모델을 정의합니다.
- __init__ 메서드에서는 모델의 구조를 초기화합니다. num_classes는 분류할 클래스의 수를 나타냅니다. super()를 사용하여 부모 클래스의 __init__ 메서드를 호출합니다.
- self.in_channels 변수를 64로 설정하고, 첫 번째 합성곱 레이어인 self.conv1을 정의합니다. 이 레이어는 입력 채널이 3이고 출력 채널이 64인 7x7 커널을 사용하며, 스트라이드는 2로 설정되어 입력 크기를 절반으로 줄입니다. self.bn1은 배치 정규화 레이어이고, self.relu는 ReLU 활성화 함수입니다. 그리고 self.maxpool은 3x3 커널과 스트라이드 2로 맥스 풀링을 수행합니다.
- _make_layer 메서드는 잔차 블록(ResidualBlock)을 반복하여 레이어를 생성하는 메서드입니다. block은 잔차 블록 클래스를 가리키고, out_channels는 출력 채널의 수, blocks는 반복할 블록 수, stride는 스트라이드 값입니다. 이 메서드는 잔차 블록을 반복하여 리스트(layers)에 추가하고, 출력 채널의 수를 갱신합니다.
- forward 메서드는 모델의 순전파를 정의합니다. 입력 x를 self.conv1을 통과시키고, 배치 정규화와 ReLU 활성화 함수를 적용합니다. 그리고 맥스 풀링을 수행합니다.
- self.layer1부터 self.layer4까지 순서대로 잔차 블록 레이어를 통과시킵니다. 이러한 레이어를 통과한 결과는 out 변수에 저장됩니다.
- self.avgpool은 Adaptive Average Pooling 레이어로, 출력 크기를 1x1로 조정합니다. 이를 통해 공간적인 정보를 압축하고 1차원 벡터로 변환합니다.
- out을 1차원 벡터로 변환한 후 (out.view(out.size(0), -1)), self.fc 레이어를 통과시켜 최종적인 클래스 예측을 수행합니다.
♣ 모델 생성,


- if torch.cuda.device_count() > 1:은 GPU가 하나 이상 있는지 확인합니다. 이 조건이 참이라면, 여러 개의 GPU를 사용할 수 있음을 의미합니다.
- if 문 내에서 print('Using', torch.cuda.device_count(), "GPUs!")는 사용 가능한 GPU의 개수를 출력합니다.
- model = parallel.DataParallel(model)은 모델을 DataParallel로 래핑하여 여러 개의 GPU를 사용한 병렬 처리를 가능하게 합니다. 이를 통해 모델은 사용 가능한 GPU를 동시에 활용하며 작업을 분산시킵니다.
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")는 device 변수를 생성하고 CUDA (GPU 컴퓨팅 플랫폼)의 사용 가능 여부를 확인합니다. CUDA가 사용 가능하면, 장치를 "cuda"로 설정하여 GPU를 사용함을 나타냅니다. 그렇지 않은 경우, 장치를 "cpu"로 설정하여 CPU를 사용합니다.
- 마지막으로, model.to(device)은 모델을 선택한 장치 (GPU 또는 CPU)로 이동시킵니다. 이를 통해 계산이 선택한 장치에서 수행되도록 보장합니다.
※ 참고 자료
1. num_workers: https://velog.io/@seokjin1013/PyTorch-numworkers%EC%97%90-%EA%B4%80%ED%95%98%EC%97%AC
PyTorch num_workers에 관하여
PyTorch에서의 데이터의 흐름과 적절한 num_workers값을 지정하는 방법
velog.io
2. Fruite Classification Code
https://www.kaggle.com/code/polljjaks/fruits-classification-using-res-net/edit/run/136823768
Fruits classification(using Res-Net)
Explore and run machine learning code with Kaggle Notebooks | Using data from Fruit Classification
www.kaggle.com
'ResNet' 카테고리의 다른 글
| ResNet 만들기(stem, body, header) (0) | 2023.09.18 |
|---|---|
| Human Protein Atlas Image Classification(ResNet34) (0) | 2023.09.11 |
| (예시)ResNet 50 구현 (0) | 2023.07.23 |
| (논문)Deep Residual Learning for Image Recognition (0) | 2023.07.23 |
| (개념)ResNet(잔차신경망) (0) | 2023.07.18 |