2023. 7. 23. 13:54ㆍResNet
♣ Introduction
깊은 합성곱 신경망은 이미지 분류에 대한 연속적인 폭발적인 발전을 이끌었습니다. 최근 연구 결과는 네트워크의 깊이가 중요하다는 것을 밝혀냈습니다. 어려운 ImageNet 데이터셋에서 우수한 결과를 보이는 연구들은 모두 "아주 깊은(very deep)" 모델을 활용하며, 16개에서 30개의 층을 가지고 있습니다. 또 다른 다양한 어려운 시각적 인식 작업들도 아주 깊은 모델에서 크게 이득을 얻고 있습니다.
더 많은 층을 쌓는 것만으로 더 나은 네트워크를 학습하는 것이 쉬울까? 이 질문에 대한 해답을 찾는 것은 증발/폭발 그래디언트(vanishing/exploding gradient) 문제 때문에 어려움이 있었습니다. 이 문제는 SGD(Stochastic Gradient Descent)와 역전파(backpropagation)로 인한 수렴을 초기 단계부터 방해합니다. 그러나 이러한 문제는 정규화된 초기화(normalized initialization)와 중간 정규화 레이어(intermediate normalization layers)로 대부분 해결되었습니다. 이로써 수십 개의 층을 가진 네트워크도 SGD와 역전파를 이용하여 수렴을 시작할 수 있게 되었습니다.
더 깊은 네트워크가 수렴을 시작할 수 있을 때, 저하 문제(degration problem)가 노출되었습니다: 네트워크의 깊이가 증가함에 따라 정확도가 포화상태가 되고, 그 후에는 빠르게 저하됩니다. 뜻밖에도 이러한 저하는 과적합에 의해 발생하는 것이 아니며 적절히 깊은 모델에 더 많은 층을 추가하면 훈련 오류가 증가합니다. 그림 1은 전형적인 예를 보여줍니다.
-> 즉 신경망의 층이 더 깊어진다고 해서 무조건 성능이 좋아지는 것이 아님. 정확도가 오히려 떨어지기도 함.

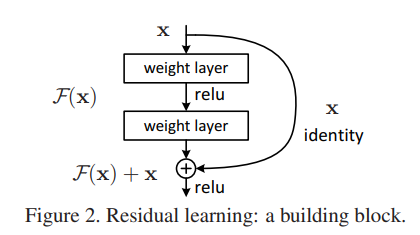
본 논문에서는 깊은 잔차 학습 프레임워크를 도입함으로써 저하 문제를 해결합니다. 몇 개의 쌓인 레이어들이 직접 원하는 기저 매핑(underlying mapping)에 적합하길 기대하기보다, 우리는 이러한 레이어들이 잔차 매핑(residual mapping)에 적합하도록 명시적으로 만듭니다. (즉 원하는 값이 나오도록 레이어들을 쌓는 게 아니라 잔차 매핑에 적합하도록 레이어들을 만드는 것)
우리는 잔차 매핑을 최적화하는 것이 원래의 매핑을 최적화하는 것보다 더 쉽다고 가정합니다. 극단적으로, 만약 항등 매핑이 최적이라면, 비선형 레이어들의 쌓음으로 항등 매핑을 맞추는 것보다 잔차를 0으로 만드는 것이 더 쉬울 것입니다.
기존의 CNN 모델은 입력값 x를 타깃값 y로 매핑하는 함수 H(x)를 얻는 것이 목적입니다.
하지만 ResNet은 F(x)+x를 최소화하는 것을 목적으로 합니다. x는 input으로 현 시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 됨. F(x)가 0과 가까워질수록 출력과 입력이 모두 x와 가까워짐.
F(x) = H(x) -x 이므로(잔차매핑) F(x)를 0에 가깝게 만든다는 것은 결국 H(x)를 x와 가깝게 한다는 것과 동일함.
H(x) - x 를 Residual이라고 함.
weight layer를 통과한 F(x)와 weight layer를 통과하지 않은 x의 합을 논문에서는 Residual Mapping이라고 하며 아래 Fig2를 Residual Block이라고 함. Residual Block이 쌓이면 Residual Network, 즉 ResNet이 됨.
F(x) + x의 표현은 "shortcut 연결"을 가진 전방전달(feedforward) 신경망을 통해 구현될 수 있습니다(fig. 2). Shortcut 연결 은 하나 이상의 레이어를 건너뛰는 연결을 의미합니다. shortcut 연결은 단순히 항등 매핑을 수행하며, 그 결과는 쌓인 레이어들의 출력과 더해집니다. 항등 shortcut 연결은 추가적인 매개변수나 계산 복잡도를 추가하지 않습니다. 전체 네트워크는 여전히 SGD와 역전파를 이용하여 end-to-end로 훈련될 수 있으며, 일반적인 라이브러리를 사용하여 솔버를 수정하지 않고도 쉽게 구현할 수 있습니다.
- 극도로 깊은 잔차 네트워크는 최적화하기 쉽지만, 깊이가 증가할 때 "일반" 네트워크(단순히 레이어를 쌓는 것)는 높은 훈련 오류를 보여줍니다.
- 깊은 잔차 네트워크는 크게 증가한 깊이로부터 쉽게 정확도 향상을 이뤄냅니다. 결과적으로 이전 네트워크보다 상당히 우수한 결과를 도출합니다.
♣ Deep Residual Learning(안 봐도 됨)
- Residual Learning(잔차 학습)
H(x)를 여러 층으로 이루어진 맵핑으로 가정하겠습니다. 이 맵핑은 모델의 처음 몇 층에서부터 적용되며, x는 이러한 층 중 첫 번째 층에 들어가는 입력을 나타냅니다. 여러 비선형 층들이 복잡한 함수를 점진적으로 근사할 수 있다고 가정한다면, 이는 결국 잔차 함수를 점진적으로 근사할 수 있다는 것과 동등합니다. 여기서 잔차 함수는 H(x) - x를 의미하며, 입력과 출력이 동일한 차원을 가정합니다. 따라서 H(x)를 근사하기 위해 층들을 쌓는 대신, 우리는 이러한 층들이 명시적으로 잔차 함수 F(x) := H(x) - x를 근사하도록 합니다. 이렇게 하면 원래의 함수는 F(x) + x가 됩니다.
이러한 재구성은 디그레이데이션 문제에 대한 역설적인 현상에 대한 동기부여에서 나왔습니다 (Fig. 1, 왼쪽). 이전에 소개한 것처럼, 추가된 층이 항등 매핑으로 구성될 수 있다면, 더 깊은 모델은 더 얕은 모델보다 훈련 오류가 크지 않아야 합니다. 그러나 디그레이데이션 문제는 여러 비선형 층을 이용해 항등 매핑을 근사하기 어렵다는 것을 시사합니다. 잔차 학습 재구성을 통해, 만약 항등 매핑이 최적의 경우라면, 솔버는 단순히 다중 비선형 층의 가중치를 영으로 바꾸어 항등 매핑을 근사할 수 있습니다.
실제로는 항등 매핑이 최적의 경우가 아닐 수 있지만, 우리의 재구성은 문제에 대한 사전 조건을 도와줄 수 있습니다. 최적 함수가 영 매핑보다는 항등 매핑에 더 가까울 경우, 솔버가 항등 매핑을 기준으로 변동을 찾는 것이 새로운 함수를 학습하는 것보다 더 쉬울 수 있습니다. 실험들을 통해 (Fig. 7) 학습된 잔차 함수들은 일반적으로 작은 반응을 가지며, 이는 항등 매핑이 합리적인 사전 조건을 제공한다는 것을 시사합니다.
- Identity Mapping by Shortcuts(shortcuts를 이용한 항등 매핑)
항등 매핑은 입력을 출력으로 직접 복사하는 것을 의미합니다. 따라서 신경망에서 항등 매핑은 아무런 변환도 가하지 않고 입력을 그대로 출력으로 전달하는 것을 의미합니다. 그러나 딥러닝 모델에서 모든 층을 통과하면서 변환되어 버리면서 출력이 입력과 동일한 값이 되는 것은 쉽지 않은 일입니다.
이러한 문제를 해결하기 위해 shortcuts이라는 기법이 사용됩니다. shortcuts은 입력을 하나 이상의 층을 건너뛰어 바로 출력에 더해주는 방법을 말합니다. 이를 통해 입력의 항등 매핑이 층을 통과하면서 유지될 수 있습니다.
예를 들어, shortcuts을 이용하여 두 개의 층을 건너뛰는 경우, 입력 x를 직접 출력에 더해주게 됩니다. 따라서 신경망의 출력은 입력과 동일한 값을 가지면서도 층들을 통과하면서 원하는 변환을 수행할 수 있게 됩니다. 이러한 기법은 딥러닝 모델의 깊이를 증가시킬 때 특히 유용하며, 더 깊은 네트워크에서도 학습이 안정적으로 이루어지도록 도와줍니다.
이러한 항등 매핑을 통해 shortcuts은 딥러닝 모델의 깊이를 증가시키는 데 기여하며, 더 정확한 예측 결과를 얻는 데 도움이 됩니다.
우리는 잔차 학습(Residual Learning)을 몇 개의 층에 대해 적용합니다. 논문에서 정의하는 빌딩 블록은 다음과 같습니다:

여기서 x와 y는 고려된 층의 입력 및 출력 벡터입니다. 함수 F(x, {Wi})는 학습할 잔차 매핑을 나타냅니다. 예를 들어, 그림 2의 예제에서 두 개의 층이 있는 경우, F = W2σ(W1x)로 나타낼 수 있습니다. 여기서 σ는 ReLU [29]를 의미하며, 편향은 단순화를 위해 생략되었습니다. 연산 F + x은 shortcuts 연결과 요소별 덧셈으로 수행됩니다. 이후 덧셈 이후에 두 번째 비선형성(즉, σ(y), 그림 2 참조)을 적용합니다.
식 (1)의 쇼트컷 연결은 추가 매개변수나 계산 복잡성을 도입하지 않습니다. 이는 실제로 매우 유용하며, 또한 일반적인 신경망과 잔차 네트워크 간의 비교에서 중요합니다. 우리는 동시에 동일한 매개변수 수, 깊이, 너비 및 계산 비용을 가지는 일반적인 및 잔차 네트워크를 공정하게 비교할 수 있습니다(무시할 수 있는 요소별 덧셈을 제외하고). 식 (1)에서 x와 F의 차원은 동일해야 합니다. 이를 만족하지 않는 경우 (예: 입력/출력 채널을 변경하는 경우), 우리는 shortcuts 연결을 통해 차원을 맞추기 위해 선형 투영 Ws를 수행할 수 있습니다.

- Network Architectures
우리는 다양한 일반적인/잔차 네트워크를 테스트하고 일관된 현상을 관찰했습니다. 이를 논의하기 위한 예시로, ImageNet을 위한 두 개의 모델을 다음과 같이 설명합니다.
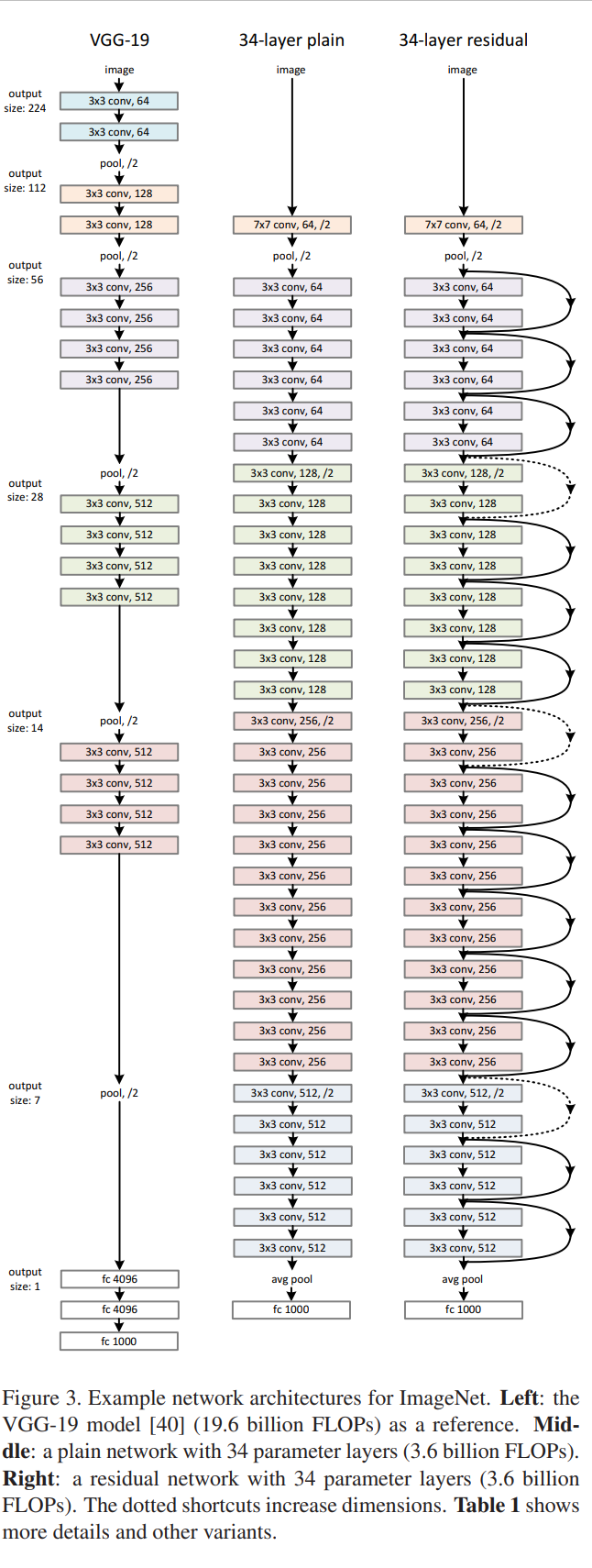
Plain Network(베이스라인, 위 Figure 3의 가운데 이미지)
일반적인 베이스라인(그림 3, 가운데)은 주로 VGG 네트워크의 철학에 영감을 받았습니다(그림 3, 왼쪽). 합성곱 층들은 대부분 3×3 필터를 가지며 두 가지 간단한 설계 규칙을 따릅니다: 같은 출력 피쳐 맵 크기를 가진 층들은 동일한 수의 필터를 가지고 있으며, 만약 피쳐 맵 크기가 반으로 줄어든다면, 계층의 시간 복잡성을 보존하기 위해 필터 수가 두 배로 늘어납니다. 저희는 스트라이드가 2인 합성곱 층을 통해 직접 다운샘플링을 수행합니다.
-> 즉 스트라이드가 2인 kernerl을 이용하여 input의 크기(size)가 작아지면 채널 수는 2배로 늘어남. 따라서 size가 224일 때는 채널 수가 64, 사이즈가 112일 때는 채널 수가 128... 이렇게 되는 것.
네트워크는 글로벌 평균 풀링 층(avg pool)과 소프트맥스를 가진 1000-way 완전 연결층(fc 1000)으로 끝납니다. 그림 3 (가운데)에서 가중된 총 계층 수는 34입니다.
이 모델은 VGG 네트워크 [40] (그림 3, 왼쪽)보다 적은 필터와 낮은 복잡성을 가진다는 점을 주목할 가치가 있습니다. 34층 베이스라인은 36억 개의 FLOP(곱셈-덧셈 연산)을 가지며, VGG-19 (196억 개의 FLOP)의 18%에 불과합니다.
Residual Network(잔차신경망 모델, Figure3의 오른쪽 이미지)
위의 일반적인 네트워크를 기반으로 shortcuts 연결을 삽입합니다(그림 3, 오른쪽), 이렇게 하면 네트워크가 잔차 버전으로 변환됩니다. 입력과 출력의 차원이 동일한 경우(그림 3의 실선 shortcuts) 항등 shortcuts(Eqn.(1))을 직접 사용할 수 있습니다. 차원이 증가하는 경우(그림 3의 점선 shortcuts), 두 가지 옵션을 고려합니다: (A) 여전히 항등 매핑을 수행하며 차원을 늘리기 위해 추가적인 0 항목을 패딩합니다. 이 옵션은 추가적인 매개변수를 도입하지 않습니다. (B) Eqn.(2)의 투영 shortcuts을 사용하여 차원을 맞춥니다(1×1 컨볼루션으로 수행). 두 옵션 모두 shortcuts이 두 개의 크기가 다른 피쳐 맵을 건너뛸 때, 스트라이드 2로 수행됩니다.
Eqn.(1) vs Eqn.(2)
식 (1)과 식 (2)의 차이점은 shortcuts 연결의 목적과 작동 방식에 있습니다: 식 (1)은 항등 shortcuts 연결을 나타냅니다. 입력과 출력의 차원이 동일한 경우 사용됩니다. 이 shortcuts은 단순히 입력 x를 잔차 함수의 출력(F(x))에 더하는 역할을 합니다. ( F(x) + x)
식 (2)은 투영 shortcuts 연결을 나타냅니다. 입력과 출력의 차원이 다른 경우 사용됩니다. 이 경우 차원을 맞추기 위해 1x1 컨볼루션(Ws)을 사용하여 선형 투영이 수행되고, 그 후 입력(x)을 잔차 함수의 출력(F(x))에 더합니다.
요약하면, 식 (1)은 항등 shortcuts에 사용되며 추가적인 매개변수를 필요로 하지 않습니다. 반면, 식 (2)는 차원을 맞추기 위해 투영 shortcuts에 사용되며 추가적인 매개변수를 포함할 수 있습니다.
♣ Experiments
-ImageNet Classification
1000개의 클래스로 구성된 ImageNet 2012 분류 데이터셋 [35]에서 본 논문의 방법을 평가합니다. 모델은 128만 개의 훈련 이미지에서 훈련되고, 5만 개의 검증 이미지에서 평가됩니다. 또한 테스트 서버에서 보고된 10만 개의 테스트 이미지에 대한 최종 결과를 얻습니다. 우리는 상위 1위 및 상위 5위 오류율을 평가합니다.
Plain Networks
먼저 18층과 34층의 일반 네트워크를 평가합니다. 34층 일반 네트워크는 그림 3 (중간)에 있습니다. 18층 일반 네트워크는 비슷한 형태를 가지고 있습니다. 자세한 아키텍처는 표 1을 참조하세요.
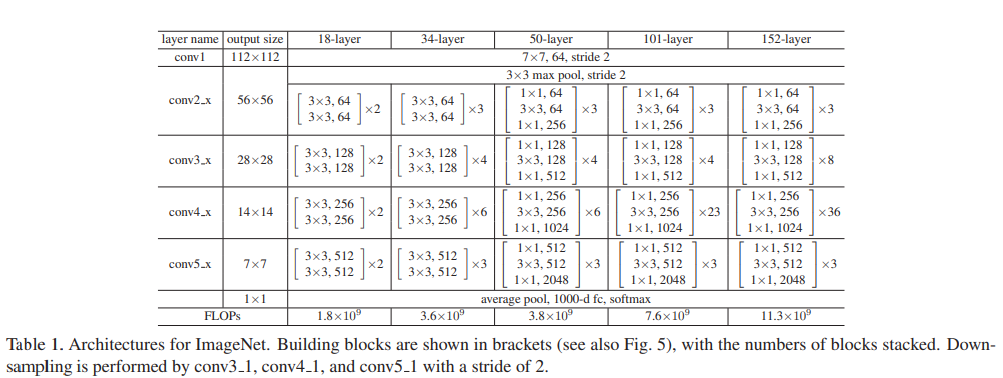

표 2의 결과는 더 깊은 34층 일반 네트워크가 더 얕은 18층 일반 네트워크보다 더 높은 검증 오류를 가지고 있음을 보여줍니다. 이러한 이유를 밝히기 위해, 그림 4 에서 그들의 훈련/검증 오류를 훈련 과정 동안 비교합니다. 34층 일반 네트워크는 전체 훈련 과정 동안 더 높은 훈련 오류를 가지고 있습니다.

Residaul Networks
다음으로 18층과 34층의 잔차 네트워크 (ResNet)를 평가합니다. 기본 아키텍처는 위의 일반 네트워크와 동일하지만, 그림 3 (오른쪽)과 같이 각각의 단축 연결이 추가되었습니다. 모든 단축 연결에 대해 항등 매핑을 사용하고 차원을 늘리기 위해 제로 패딩을 사용합니다. 따라서 일반 네트워크와 비교하여 추가적인 매개변수가 없습니다.
-> 즉 shortcuts에 대해 항등매핑을 사용하였기 때문에 추가적인 매개변수가 없다는 것.
표 2와 그림 4에서 세 가지 주요 관찰 사항이 있습니다. 첫째, 잔차 학습을 통해 상황이 반전되었습니다 - 34층 ResNet이 18층 ResNet보다 더 우수합니다 (2.8% 더 높은 정확도).
->즉 Plain Networks와 다르게 Residaul Networks에서는 깊이가 더 깊은 34 layer의 정확도가 더 높음.
더 중요한 것은, 34층 ResNet이 상당히 낮은 훈련 오류를 나타내고, 검증 데이터에 대해서도 잘 일반화한다는 것입니다. 이는 이 설정에서 감퇴 문제가 잘 해결되었으며, 깊이를 증가시켜 정확도를 얻을 수 있음을 보여줍니다.
-> 34 layer Residual Networks의 성능이 상당히 좋음.
두 번째, 34층 ResNet은 일반 네트워크와 비교하여 top-1 오류를 3.5% 줄였습니다. 이는 훈련 오류가 성공적으로 감소함으로 인한 결과입니다 (표 2, 그림 4 오른쪽 대 왼쪽). 이 비교는 잔차 학습이 극도로 깊은 시스템에 대해 효과적임을 확인합니다.
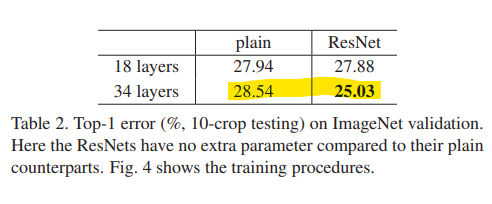
마지막으로, 18층 일반 네트워크와 18층 ResNet은 정확도가 비슷하다는 점에 주목할 필요가 있습니다 (표 2). 하지만 18층 ResNet은 더 빠르게 수렴합니다 (그림 4 오른쪽 대 왼쪽). 네트워크가 "지나치게 깊지 않을 때" (여기서는 18층), 현재 SGD 솔버는 여전히 일반 네트워크에 좋은 솔루션을 찾을 수 있습니다. 이 경우, ResNet은 초기 단계에서 빠른 수렴을 제공함으로써 최적화를 용이하게 합니다.
-> 18층 일반 신경망과 18층 잔차신경망의 정확도는 비슷하지만 잔차신경망의 수렴 속도가 더 빠름.
Identity vs Projection Shortcuts(항등매핑 vs 투영매핑)
Residual 네트워크(ResNets)는 깊은 신경망의 훈련을 용이하게 하기 위해 shortcut 연결을 도입합니다. 이 shortcut 연결은 정보가 입력에서 직접 출력으로 흐를 수 있도록 해줍니다. shortcut 연결은 두 가지 유형이 있습니다:
- 동일 매핑 (Identity Shortcut): 레이어의 입력과 출력 차원이 동일한 경우, 동일 매핑이 사용됩니다. 이는 shortcut 연결이 입력을 그대로 출력으로 전달하는 것을 의미합니다.
- 투영 매핑 (Projection Shortcut): 레이어의 입력과 출력 차원이 다른 경우 (예를 들어, 레이어를 거치면서 출력 feature map의 크기나 채널 수가 변경되는 경우입니다.), 투영 매핑이 사용됩니다. 이 경우 입력에 1x1 컨볼루션을 적용하여 입력을 출력과 동일한 차원으로 변환합니다. 투영 매핑은 입력과 출력 차원이 다른 레이어를 통과하는 동안 정보가 원활하게 흐를 수 있도록 보장합니다.
<실선이 항등매핑, 점선이 투영매핑>

동일 매핑과 투영 매핑 중 어떤 것을 선택하느냐는 레이어의 입력과 출력 feature map의 차원이 같은지 여부에 따라 달라집니다. 입력과 출력 차원이 같은 경우 동일 매핑이 사용되고, 차원이 변경되는 경우 투영 매핑이 사용됩니다.
-> 즉 위의 그림을 보면 사이즈가 같은 차원일 때는 실선(동일매핑)이다가 다른 차원일 때는 점선(투영매핑)이다.
투영 매핑을 사용하는 극도로 깊은 ResNets (예: ResNet-34, ResNet-50, ResNet-101, ResNet-152)은 훈련 오류를 낮추고 정확도를 높일 수 있어서 동일 매핑을 사용하는 일반적인 네트워크보다 성능이 우수합니다. 이는 residual learning이 깊은 신경망의 훈련에 대한 최적화 어려움을 해결하고 깊이 증가에 따른 정확도 향상을 가능케 한다는 것을 보여줍니다.
파라미터 없는 identity shortcuts이 학습에 도움이 되는 것을 확인했습니다. 다음으로, projection shortcuts (Eqn.(2))에 대해 조사해보겠습니다.
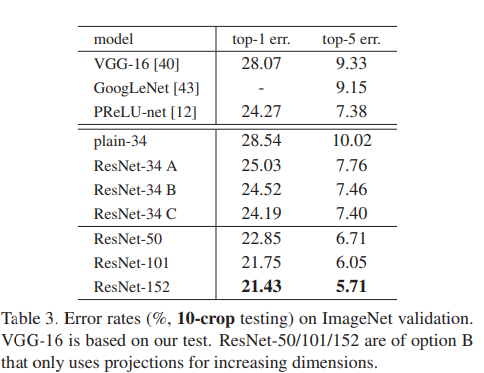
테이블 3에서 세 가지 옵션을 비교합니다: (A) 증가하는 차원에는 zero-padding shortcuts을 사용하고, 모든 shortcuts은 파라미터가 없습니다 (테이블 2와 그림 4 우측과 동일); (B) 증가하는 차원에는 projection shortcuts을 사용하고, 다른 shortcuts은 identity를 사용합니다; 그리고 (C) 모든 shortcuts이 projections입니다.
즉 A: 파라미터가 없는 34 residaul layer(Identity mapping만 사용) vs B: 증가하는 차원에는 투영매핑을, 증가하지 않는 차원에는 Identity mapping을 사용하는 34 residual layer vs C: 모든 차원에 투영매핑을 사용하는 34 residual layer
테이블 3은 이 세 가지 옵션이 모두 plain 네트워크보다 훨씬 우수하다는 것을 보여줍니다. B가 A보다 약간 더 좋은 결과를 보여줍니다. 이는 A의 zero-padding 된 차원들이 실제로 residual learning이 없다는 것을 의미합니다. C가 B보다 약간 더 좋은 결과를 보이며, 이는 (13개의) projection shortcuts으로 인해 추가된 추가 파라미터로 설명할 수 있습니다. 그러나 A/B/C 사이의 차이가 작다는 것은 projection shortcuts이 degradation problem을 해결하는데 필수적이지 않다는 것을 보여줍니다. 따라서 이후 연구에서는 메모리/시간 복잡성과 모델 크기를 줄이기 위해 option C를 사용하지 않습니다. Identity shortcuts은 복잡성을 증가시키지 않으면서 특히 bottleneck 아키텍처의 중요한 부분입니다.
Deeper Bottleneck Architecures
이 부분에서는 ImageNet 데이터셋에 대한 더 깊은 신경망 구조에 대해 설명합니다. 학습 시간에 대한 고려 사항으로, 병목 디자인으로 빌딩 블록을 수정합니다.
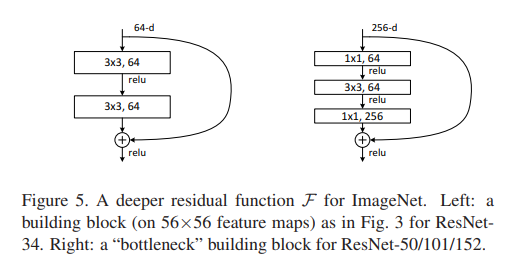
각 잔여 함수 F에 대해, 2개 대신 3개의 레이어 스택을 사용하며 (그림 5 참조), 이 3개 레이어는 1x1, 3x3, 1x1 컨벌루션으로 구성됩니다. 1x1 레이어는 차원을 줄이고 다시 증가시켜 (복원시킴) 작은 입력/출력 차원을 가지도록 하고, 3x3 레이어는 더 작은 입력/출력 차원을 가진 병목으로 작용합니다. 이 디자인은 계산적으로 더 효율적이며, 원래 디자인과 병목 디자인은 시간 복잡성이 유사합니다.
이 부분은 더 깊은 신경망 구조에서 사용되는 병목 디자인에 대한 설명입니다.
- "These three layers consist of 1x1, 3x3, and 1x1 convolutions." 여기서 세 개의 레이어는 각각 1x1, 3x3, 1x1 컨벌루션으로 구성됩니다. 각 레이어는 필터의 크기를 나타내며, 1x1 컨벌루션은 1픽셀 크기의 필터를 의미합니다. 이 세 레이어는 순서대로 연속적으로 적용됩니다.
- "The 1x1 layers are responsible for reducing and then increasing (restoring) the dimensions." 1x1 레이어는 차원을 줄이고 다시 증가시킵니다. 먼저, 입력 데이터의 차원을 줄여서 정보를 압축합니다. 그런 다음, 압축된 정보를 다시 복원하여 원래 차원으로 되돌립니다. 이렇게 함으로써 더 적은 차원으로 표현할 수 있는 중요한 정보를 추출하고, 더 효율적으로 계산할 수 있습니다.
- "The 3x3 layer acts as a bottleneck with smaller input/output dimensions." 3x3 레이어는 병목 역할을 하며, 입력 및 출력 차원이 더 작습니다. 이 레이어는 1x1 레이어를 통해 줄여진 차원의 정보를 처리하고, 더 적은 차원으로 매핑하여 병목을 형성합니다. 이를 통해 더 적은 계산 비용으로 더 효율적인 모델을 만들 수 있습니다.
매개변수가 없는 항등 매핑 바로가기가 병목 아키텍처에 특히 중요합니다. 그림 5 (오른쪽)의 병목 디자인에서 항등 바로가기를 투영 바로가기로 대체하면, 시간 복잡성과 모델 크기가 두 배로 증가하게 됩니다. 이는 투영 바로가기가 두 가지 고차원 끝점에 연결되기 때문입니다. 따라서 항등 바로가기를 사용하면 병목 디자인에 대해 더 효율적인 모델을 구성할 수 있으며, 이는 학습 효율성과 계산 효과성을 보장하기 위해 중요합니다.
-> 모든 shortcut에 투영매핑을 사용하지 않는 이유. 시간 복잡성과 무델의 크기가 증가함. 효율적인 모델 구성을 위해 항등매핑과 투영매핑을 함께 사용한다.
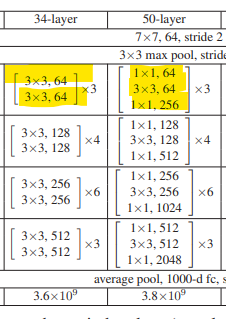
[Table 1]
1) 50-layer ResNet
34-layer 네트워크의 각 2-layer 블록을 이 3-layer bottleneck 블록으로 대체하여 50-layer ResNet을 만들었습니다 (Table 1 참조). 또한 차원을 증가시키기 위해 option B를 사용합니다(증가하는 차원에는 투영매핑을, 차원에 변화가 없는 경우에는 항등매핑을 사용). 이 모델은 38억 개의 FLOPs(곱하기-덧셈 연산)을 갖습니다.
2) 101-layer and 152-layer ResNets
우리는 더 많은 3-layer 블록을 사용하여 101-layer와 152-layer ResNets을 만들었습니다 (Table 1 참조).

놀랍게도, 깊이가 크게 증가하더라도, 152-layer ResNet(113억 개의 FLOPs)은 여전히 VGG-16/19 네트워크(각각 153/196억 개의 FLOPs)보다 낮은 복잡성을 갖습니다.
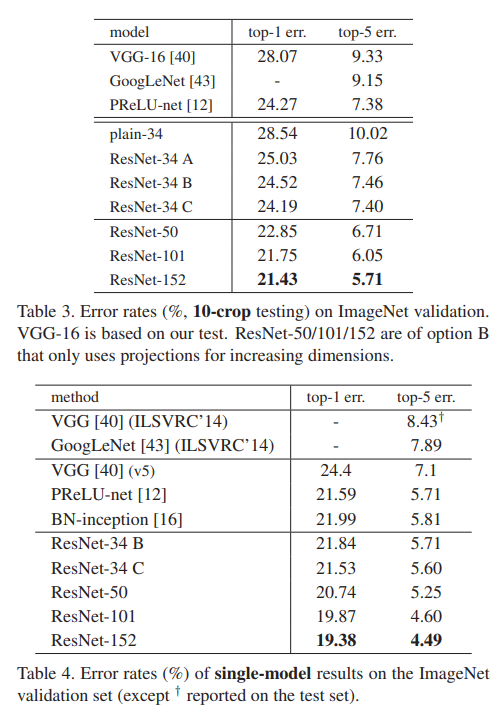
50/101/152-layer ResNets은 34-layer 모델보다 더 정확합니다(Table 3 and 4 참조). degradation problem이 나타나지 않으며, 크게 증가한 깊이에서 정확도 향상을 경험합니다. 깊이의 이점은 모든 평가 지표에서 관찰됩니다 (Table 3 and 4 참조).
다른 최신 기법들과의 비교
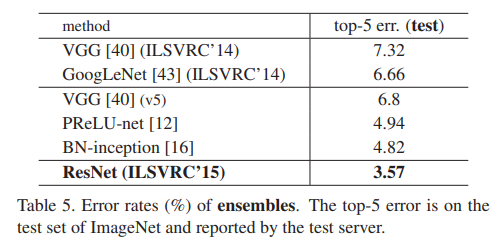
기준인 34-layer ResNet은 매우 경쟁력 있는 정확도를 달성했습니다. 또한, 152-layer ResNet은 단일 모델의 top-5 검증 오류가 4.49%로 이전 모든 앙상블 결과를 능가합니다 (Table 5). 이 결과를 바탕으로 다양한 깊이의 여섯 개 모델을 앙상블하여 생성합니다 (제출 시점에는 두 개의 152-layer 모델만 사용). 이로 인해 테스트 세트에서 3.57%의 top-5 오류를 달성하며 (Table 5), 이 결과로 ILSVRC 2015에서 1위를 차지했습니다.
-CIFAR-10 and Analysis
'ResNet' 카테고리의 다른 글
| ResNet 만들기(stem, body, header) (0) | 2023.09.18 |
|---|---|
| Human Protein Atlas Image Classification(ResNet34) (0) | 2023.09.11 |
| (예시)ResNet 50 구현 (0) | 2023.07.23 |
| (개념)ResNet(잔차신경망) (0) | 2023.07.18 |
| (예시)Fruit Prediction|CNN|Pytorch|ResNet-18 (0) | 2023.07.17 |